
概要
動画生成AIモデル LTX-2 の後継である LTX-2.3 を試してみました。
また、NVIDIA の Blackwell GPU アーキテクチャで導入された、4ビット浮動小数点フォーマット「NVFP4」版のモデルも公開されていたため、あわせて検証しています。
LTX-2.3 とは
LTX-2.3 は、Lightricks が開発した、動画と音声を同時に生成可能なマルチモーダル動画生成AIモデルです。
従来の LTX-2 と比較して、映像と音声の同期精度や生成品質が大幅に向上しているとされています。
公式サイト
Hugging Face
https://huggingface.co/Lightricks/LTX-2.3
ライセンス
LTX-2.3 は「LTX-2 Community License」で提供されています。
https://github.com/Lightricks/LTX-2/blob/main/LICENSE
このライセンスは完全なオープンソースではなく、コミュニティ向けの制限付きライセンスです。
- 個人・小規模開発者:無料で利用可能
- 大企業:商用ライセンスが必要
- 用途制限あり
利用前には必ず原文を確認してください。
参考情報
現時点では ComfyUI に統合されており、モデルやワークフローは ComfyUI 経由でダウンロード可能です。
今回は、Comfy Cloud にあるサンプル画像も使用しています。
https://blog.comfy.org/p/ltx-23-day-0-supporte-in-comfyui
https://docs.comfy.org/ja/tutorials/video/ltx/ltx-2-3
ローカル実行環境の用意
PC 環境
NVIDIA GeForce RTX 5060 Ti 16GB を搭載した自作 PC を使用します。

Stability Matrix + ComfyUI の実行環境の用意
ComfyUI は、以前 Stability Matrix で用意したものを使います。準備方法については、過去記事をご参照ください。

Stability Matrix と ComfyUI のアップデート
古いバージョンだと正常に動作しない可能性があるため、事前に更新しておきます。
- Stability Matrix – Settings – アップデート
- Stability Matrix – パッケージ – ComfyUI の更新
以下では、
Stability Matrix 2.15.7
ComfyUI v0.19.3
で試しています。
latent_upscale_models 用のフォルダの用意と設定
Stability Matrix 版の ComfyUI では、latent_upscale_models に対応するフォルダが StabilityMatrixのインストールフォルダ\Data\Models\ 配下に標準では存在しません。そのため、extra_model_paths.yaml を編集する定義する必要があります。
詳細は、LTX-2 の際の操作をご参照ください。

必要なファイルのダウンロード
ComfyUI v0.19.3 では LTX-2.3 は統合済みのため、基本的なモデルはUIから取得できます。
今回は、以下については手動でダウンロードしています:
- NVFP4 モデル
- LoRA v1.1
(1) ComfyUI の Web UI を起動し、左側メニューの [テンプレート] をクリックします。
(2) “LTX-2.3” で検索します。
[LTX-2.3 : テキストからビデオへ] を選択します。
![テンプレート - [LTX-2.3 : テキストからビデオへ] を選択](https://iwannacreateapps.com/wp-content/uploads/2026/04/LTX-2.3_01.jpg)
(3) ワークフローが開きます。必要なモデルトファイルが不足している場合は、エラーが表示されます。
右上の [プロパティパネルの切り替えボタン] をクリックし、不足しているモデルファイルをダウンロードします。
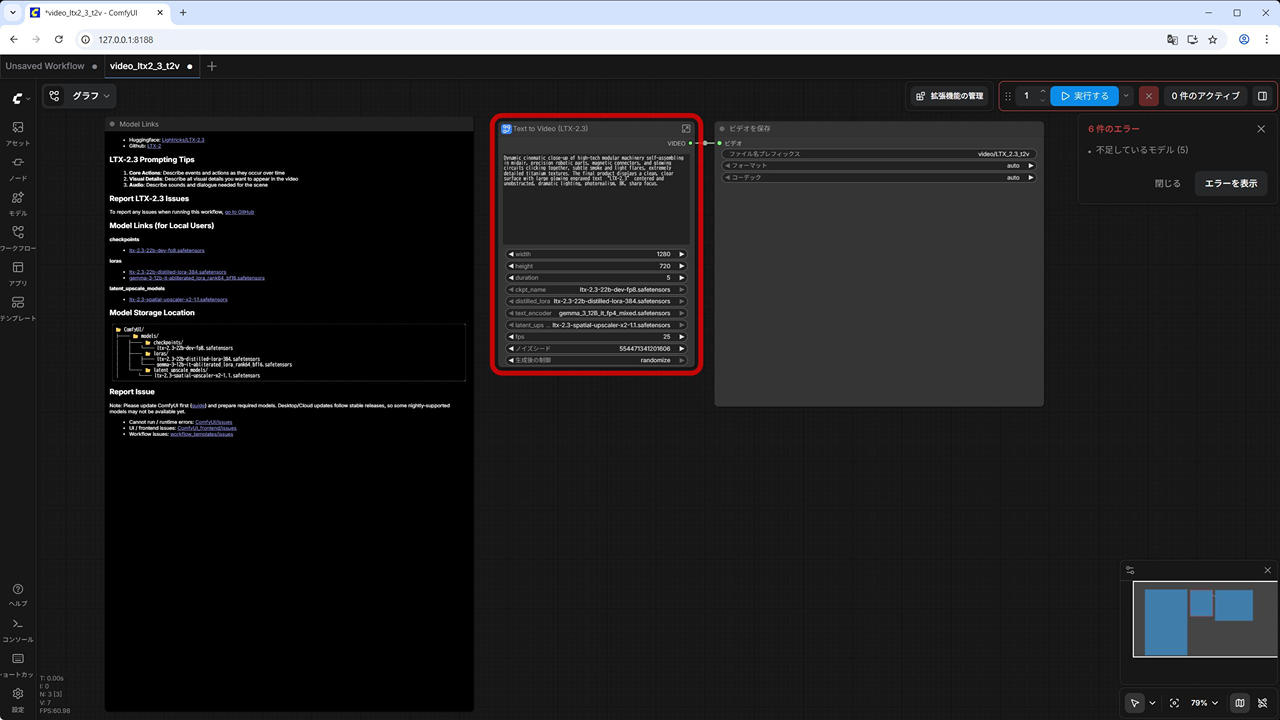
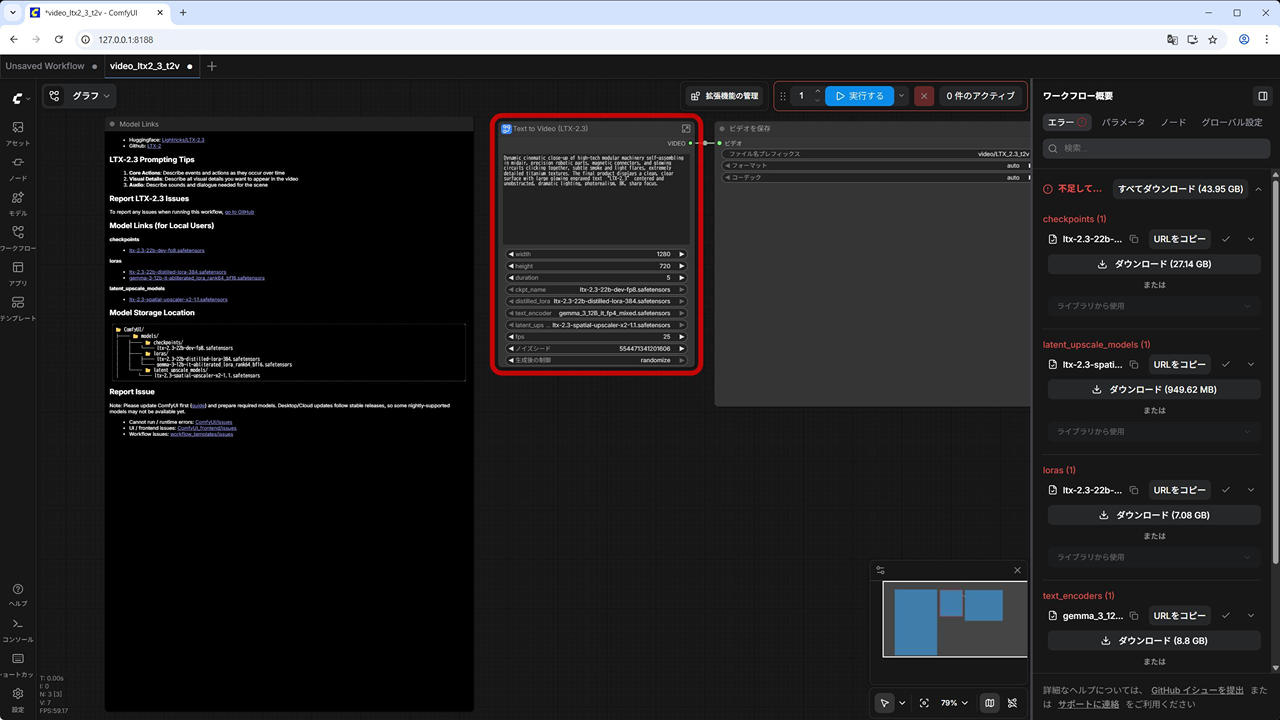
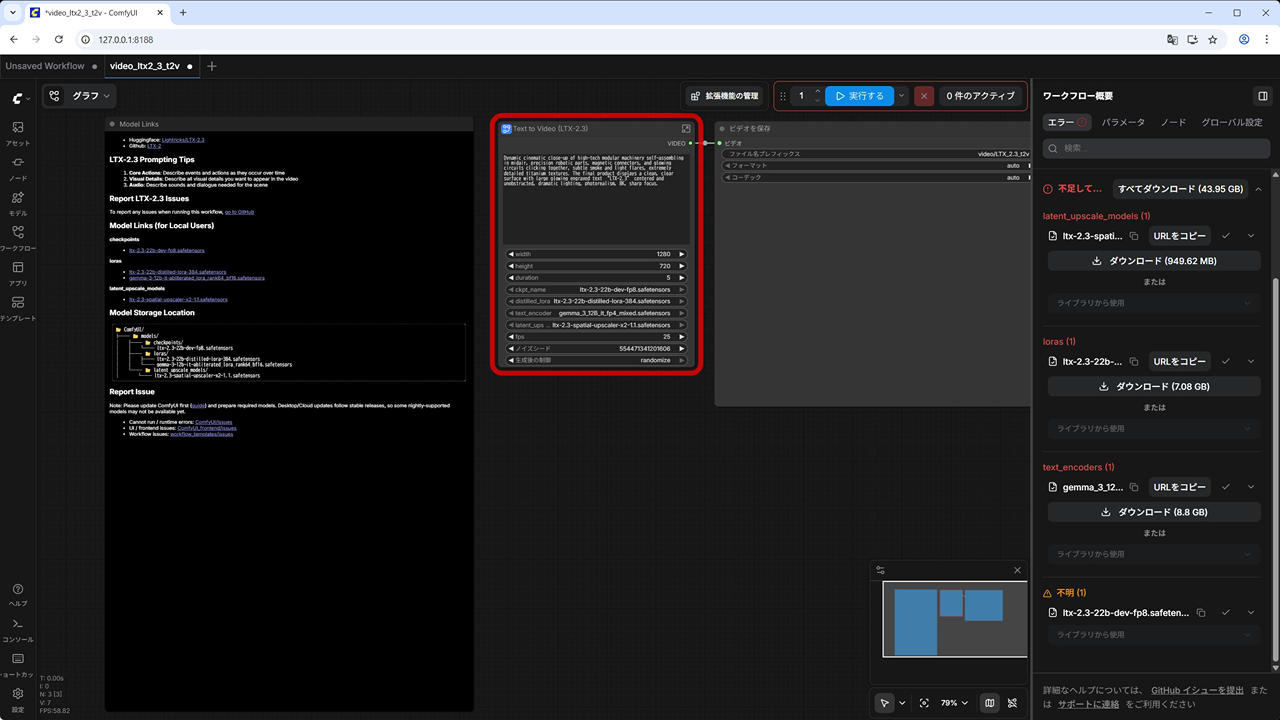
- checkpoints / ltx-2.3-22b-dev-fp8.safetensors
https://huggingface.co/Lightricks/LTX-2.3-fp8/resolve/main/ltx-2.3-22b-dev-fp8.safetensors - text_encoders / gemma_3_12B_it_fp4_mixed.safetensors
https://huggingface.co/Comfy-Org/ltx-2/resolve/main/split_files/text_encoders/gemma_3_12B_it_fp4_mixed.safetensors - latent_upscale_models / ltx-2.3-spatial-upscaler-x2-1.1.safetensors
https://huggingface.co/Lightricks/LTX-2.3/resolve/main/ltx-2.3-spatial-upscaler-x2-1.1.safetensors - loras / ltx-2.3-22b-distilled-lora-384.safetensors
https://huggingface.co/Lightricks/LTX-2.3/resolve/main/ltx-2.3-22b-distilled-lora-384.safetensors
(4) NVFP4 版のモデルと version 1.1. の Lora は、以下から個別にダウンロードします。
ltx-2.3-22b-dev-nvfp4.safetensors
https://huggingface.co/Lightricks/LTX-2.3-nvfp4
https://huggingface.co/Lightricks/LTX-2.3-nvfp4/resolve/main/ltx-2.3-22b-dev-nvfp4.safetensors
ltx-2.3-22b-distilled-lora-384-1.1.safetensors
https://huggingface.co/Lightricks/LTX-2.3
https://huggingface.co/Lightricks/LTX-2.3/resolve/main/ltx-2.3-22b-distilled-lora-384-1.1.safetensors
ファイルの配置
ダウンロードしたモデルファイルを配置します。
(1) Diffusion モデル
ltx-2.3-22b-dev-fp8.safetensors, ltx-2.3-22b-dev-nvfp4.safetensors
→ StabilityMatrix のインストールフォルダ\Data\Models\DiffusionModels
(2) テキストエンコーダ
gemma_3_12B_it_fp4_mixed.safetensors
→ StabilityMatrix のインストールフォルダ\Data\Models\TextEncoders
(3) Lora
ltx-2.3-22b-distilled-lora-384.safetensors, ltx-2.3-22b-distilled-lora-384-1.1.safetensors
→ StabilityMatrix のインストールフォルダ\Data\Models\Lora
(4) Latent Upscale モデル
ltx-2.3-spatial-upscaler-x2-1.1.safetensors
→ StabilityMatrix のインストールフォルダ\Data\Models\LatentUpscaleModels
C:\StablilityMatrix にインストールしている場合は以下のような形です:
C:\STABILITYMATRIX\DATA\MODELS
├─LatentUpscaleModels
│ ltx-2.3-spatial-upscaler-x2-1.1.safetensors
├─Lora
│ ltx-2.3-22b-distilled-lora-384-1.1.safetensors
│ ltx-2.3-22b-distilled-lora-384.safetensors
├─StableDiffusion
│ ltx-2.3-22b-dev-fp8.safetensors
│ ltx-2.3-22b-dev-nvfp4.safetensors
└─TextEncoders
gemma_3_12B_it_fp4_mixed.safetensorsサンプル画像
[LTX-2.3 : 画像から動画へ] で用いるサンプル画像を、Comfy Cloud からダウンロードします。
https://docs.comfy.org/ja/tutorials/video/ltx/ltx-2-3
(1) 画像から動画 → Comfy Cloudで実行 をクリック
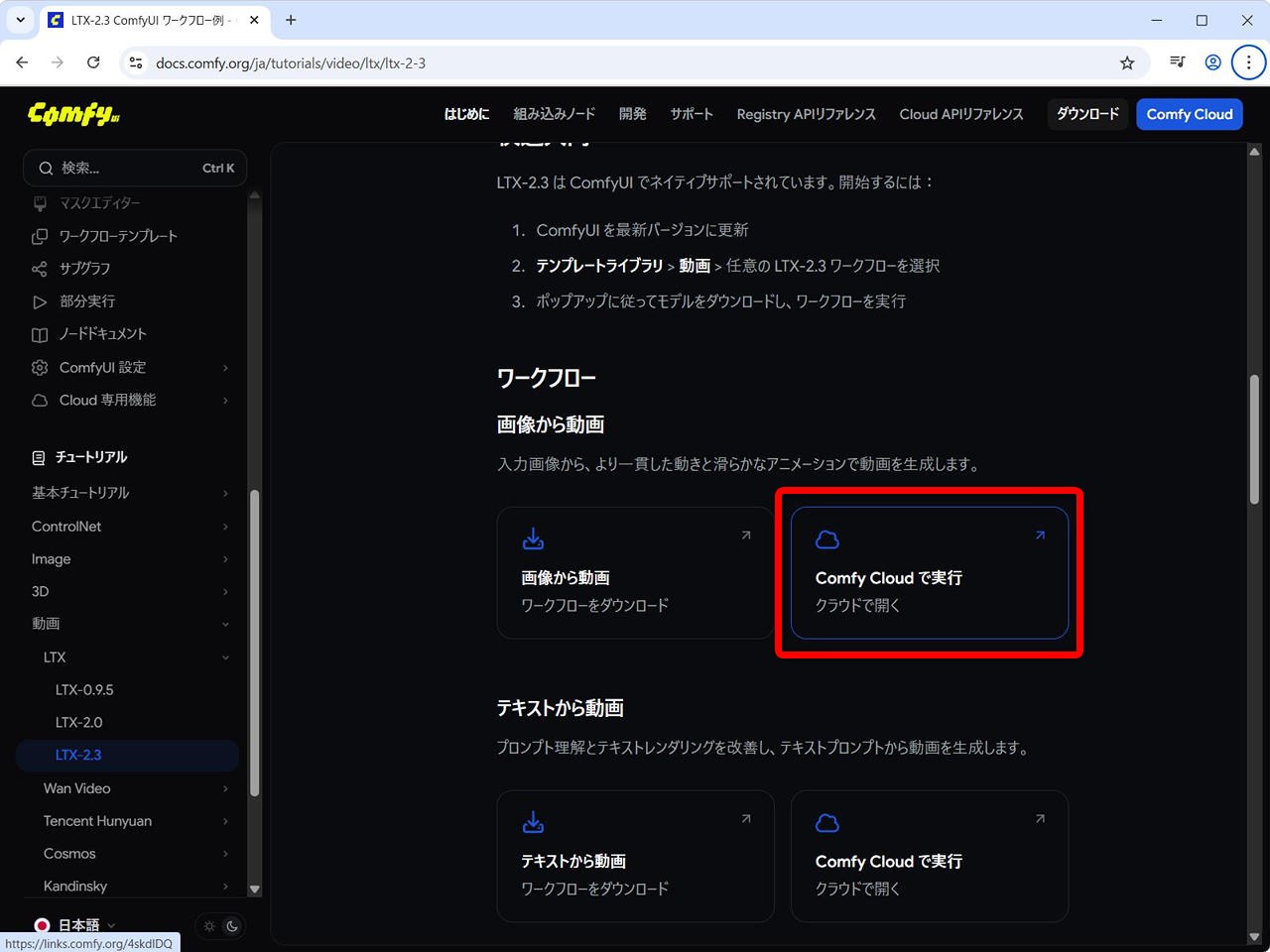
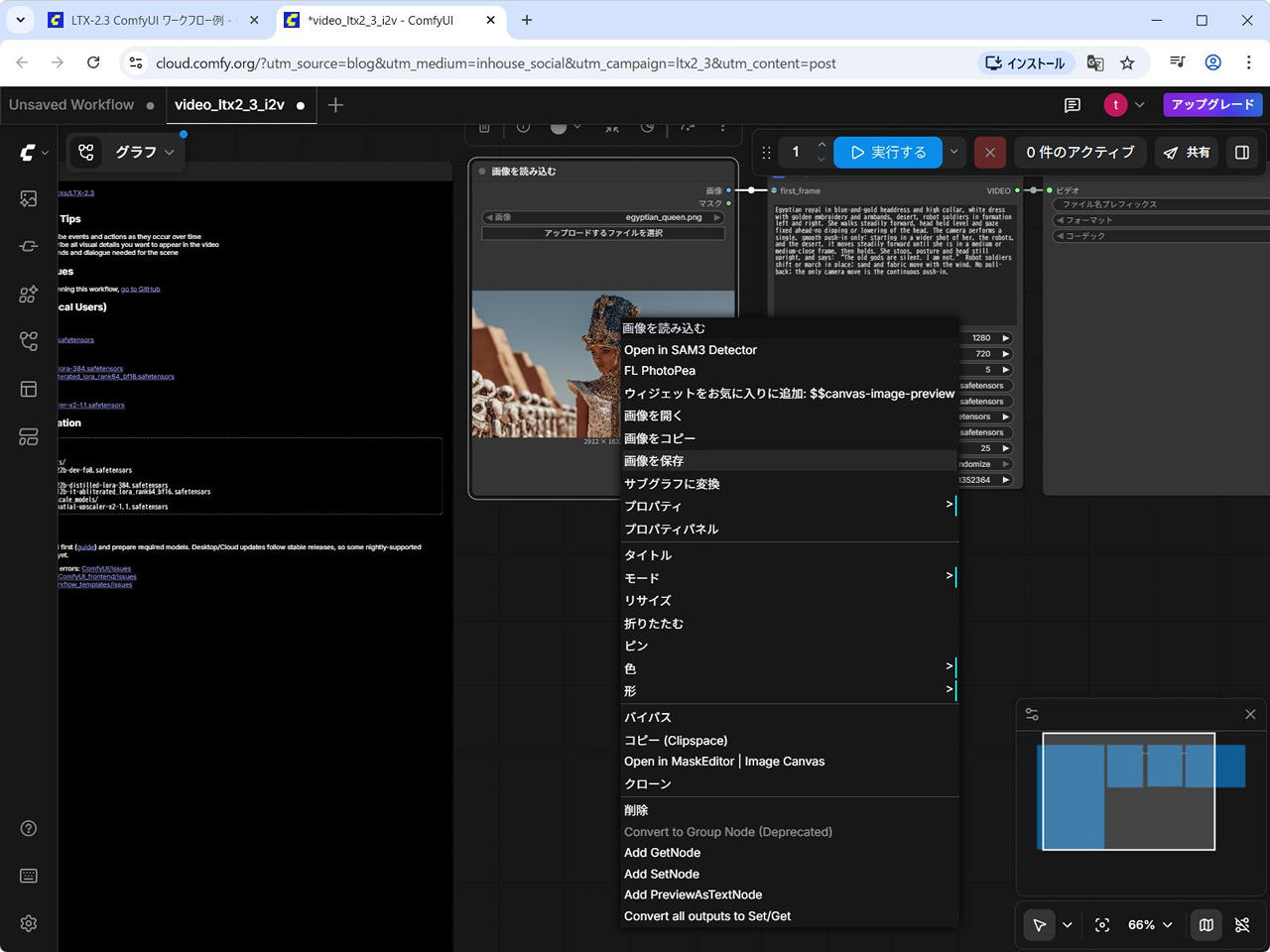
(2) 開いた ComfyUI Cloud の画像を読み込むノードの画像を右クリックして名前を付けて保存します。
(今回は egyptian_queen.png として保存しています。)
動画生成を行ってみた
今回は以下の2パターンで検証しました:
- デフォルト構成
- NVFP4 + LoRA 1.1
NVFP4 について
NVFP4は、NVIDIA Blackwell GPUアーキテクチャで導入された革新的な4ビット浮動小数点フォーマットであり、Blackwell GPU が利用できる環境であれば、試してみる価値は高いでしょう。(参考)
(NVIDIA GeForce RTX 50xx は、Blackwell GPU です。)
テキストからビデオ (デフォルトのまま)
ワークフローを開きます。
ComfyUI の Web UI – 左側メニューの [テンプレート] – [LTX-2.3 : テキストからビデオへ]
![[LTX-2.3 : テキストからビデオへ] のワークフローを実行](https://iwannacreateapps.com/wp-content/uploads/2026/04/LTX-2.3_05.jpg)
サンプルのワークフローをそのまま実行してみます。
約 211 秒で生成できました。
![[LTX-2.3 : テキストからビデオへ] のワークフローで動画生成後](https://iwannacreateapps.com/wp-content/uploads/2026/04/LTX-2.3_06.jpg)
以下生成した動画 (再生すると音声が出るので注意)
テキストからビデオ (NVFP4 + Rola 1.1)
次に NVFP4 版で試します。
今回は、Lora も 1.1 を使います。(NVFP4 を利用する上で必須というわけではないですが、せっかくなので)
[LTX-2.3 : テキストからビデオへ] のワークフローを開きます。
[Text to Video (LTX-2.3) ] のノードを変更します。
- ckpt_name : [ ltx-2.3-22b-dev-nvfp4.safetensors]
- distilled_lora : [ltx-2.3-22b-distilled-lora-384-1.1.safetensors]
![[LTX-2.3 : テキストからビデオへ] のワークフローの ckpt_name と distilled_lora を変更する](https://iwannacreateapps.com/wp-content/uploads/2026/04/LTX-2.3_07.jpg)
実行します。
約 179 秒で生成できました。
![[LTX-2.3 : テキストからビデオへ] のワークフローの ckpt_name と distilled_lora を変更して生成後](https://iwannacreateapps.com/wp-content/uploads/2026/04/LTX-2.3_08.jpg)
プロンプトは以下ですが、今回は “LTX-2.3” のテキスト描画が不十分な部分が見えました。(小数点が反映できていない。)
Dynamic cinematic close-up of high-tech modular machinery self-assembling in midair, precision robotic parts, magnetic connectors, and glowing circuits clicking together, subtle smoke and light flares, extremely detailed titanium textures. The final product displays a clean, clear surface with large glowing engraved text “LTX-2.3” centered and unobstructed, dramatic lighting, photorealism, 8K, sharp focus.
以下生成した動画 (再生すると音声が出るので注意)
画像からビデオ (デフォルト)
次に、画像から動画生成を行います。
ワークフローを開きます。
ComfyUI の Web UI – 左側メニューの [テンプレート] – [LTX-2.3 : 画像から動画へ]
![テンプレート - [LTX-2.3 : 画像から動画へ] を選択](https://iwannacreateapps.com/wp-content/uploads/2026/04/LTX-2.3_09.jpg)
ダウンロードしていたサンプル画像(egyptian_queen.png) を [画像を読み込む] ノードにドラッグアンドドロップし、実行します。
![[LTX-2.3 : 画像から動画へ] のワークフローを実行](https://iwannacreateapps.com/wp-content/uploads/2026/04/LTX-2.3_10.jpg)
大体 219 秒で生成できました。
![[LTX-2.3 : 画像から動画へ] で動画生成](https://iwannacreateapps.com/wp-content/uploads/2026/04/LTX-2.3_11.jpg)
以下生成した動画 (再生すると音声が出るので注意)
画像からビデオ(NVFP4 + Rola 1.1)
[LTX-2.3 : 画像から動画へ] のワークフローで 同様に ckpt_name と distilled_lora を変更して実行します。
![[LTX-2.3 : 画像から動画へ] のワークフローの ckpt_name と distilled_lora を変更して生成](https://iwannacreateapps.com/wp-content/uploads/2026/04/LTX-2.3_12.jpg)
約 187 秒で生成できました。
![[LTX-2.3 : 画像から動画へ] のワークフローの ckpt_name と distilled_lora を変更して生成後](https://iwannacreateapps.com/wp-content/uploads/2026/04/LTX-2.3_13.jpg)
以下生成した動画 (再生すると音声が出るので注意)
柴犬動画を作る
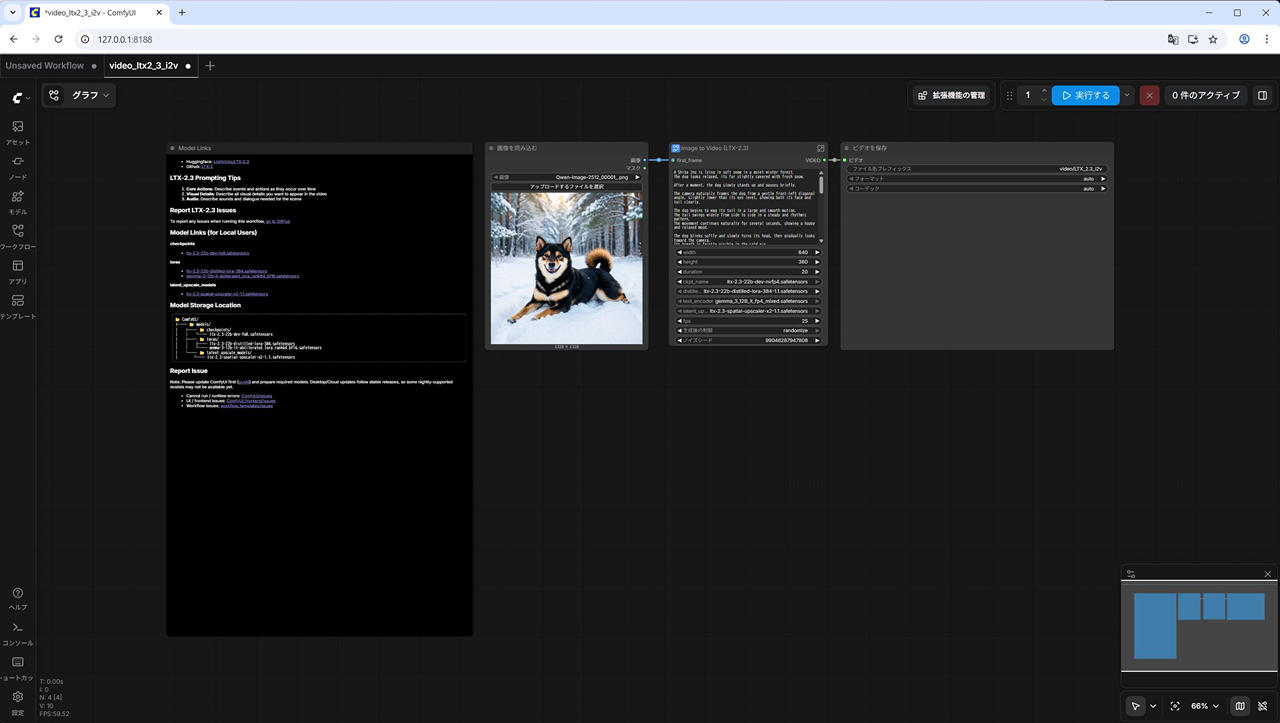
以前作成した画像をもとに [LTX-2.3 : 画像から動画へ] のワークフローで動画を作ってみました。
以下の変更を行っています。
- NVFP4 モデル
- Lora 1.1
- Witdth : 640
- Height : 320
- Duration : 20
- プロンプトを適宜変更
これで 130秒くらいで生成できます。
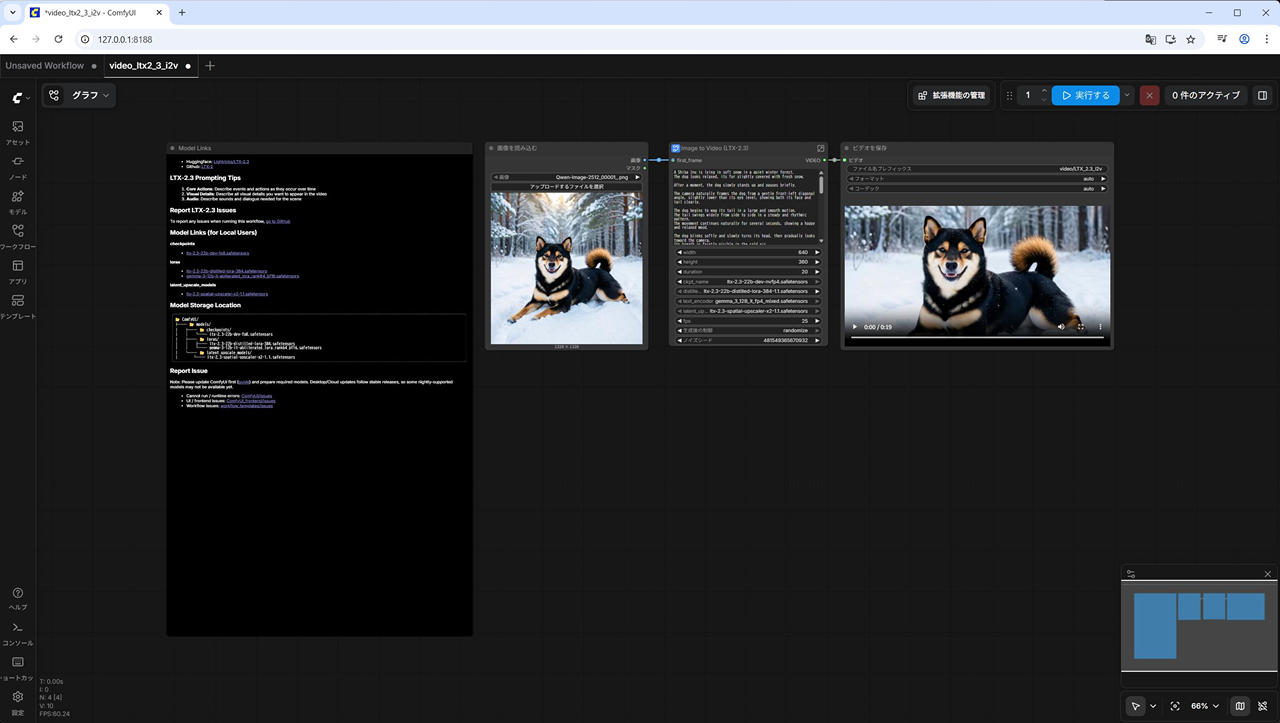
以下生成した動画 (再生すると音声が出るので注意)
プロンプトにも依存する部分は大きいですが、スムーズに動いていて、音楽も指示通り追加されています。
まとめ
LTX -2.3 の FP8 版に関しては、私の環境だと LTX-2 のときと実行時間が短くなるわけではないですが、少し質はよくなった気がします。
NVFP4 版だと、実行時間はかなり短くなるといえます。
Sora のサービス終了もありましたので、こういったローカルでの動画生成も一つの代替の選択肢になると思います。
参考となれば幸いです。
▼ 関連