
概要
Stable Audio Open は、Stability AI 社が開発したテキストから 音声の生成ができるモデルです。
ここでは Stable Audio Open 1.0 を試してみたので情報残しておきます。
Stability Matrix と ComfyUI を使って簡単に環境は用意できました。
NVIDIA GeForce RTX 5060Ti 16GB で Stable Audio Open 1.0 がどこまで動くのか の一助になれば幸いです。
公式サイト
Stable Audio には、Stable Audio 2.0 もありますが、モデルが公開されているのは 2.0 ではなく Stable Audio Open 1.0 のほうです。
https://stability.ai/stable-audio
モデル配布 (Hugging Face)
https://huggingface.co/stabilityai/stable-audio-open-1.0
ライセンスなど
本稿更新時点では、Stable Audio Open は Community のライセンスに含まれています。
https://stability.ai/license
Stable Diffusion 3.5 や Stable Video Diffusion と同様に、Stable Audio Open も “年間売上が100万ドル未満の研究者・開発者・小規模事業者・クリエイター向け は、Community ライセンスでの利用が可能” と解釈します。
(ただし、商用利用する場合はメンバーシップへの登録は必要。)
Community
For researchers, developers, small businesses, and creators with less than $1M in annual revenue.
License includes:
https://stability.ai/license
- Stable Diffusion 3.5 Suite
- SDXL Turbo
- Stable Audio Open
- Stable Fast 3D
- View full list
利用にあたっては、STABILITY AI COMMUNITY LICENSE AGREEMENT に同意する必要があります。
https://huggingface.co/stabilityai/stable-audio-open-1.0/blob/main/LICENSE.md
Stable Audio Open の環境の用意。 (Stability Matrix + ComfyUI で使う場合)
ここでは Stability Matrix で用意した ComfyUI の環境で Stable Audio Open を利用します。
参考情報
ComfyUI の examples を参考にします。
https://comfyanonymous.github.io/ComfyUI_examples/audio
https://comfyuidoc.com/ja/Examples/audio/
PC 環境
NVIDIA GeForce RTX 5060Ti 16GBを入れて自作した PC で行います。

ComfyUI の実行環境の用意
ComfyUI は、以前 Stability Matrix で用意したものを使います。準備方法はこの過去記事をご参照ください。

必要なファイルダウンロード
(1) Hugging Face のサイトから、Stable Audio Open のモデルファイルをダウンロードします。
Hugging Face のサイトにアクセスします。
Stable Audio Open をダウンロードするには、Hugging Face へのログイン と、利用条件・ライセンス・プライバシーポリシーに同意する必要があります。
ログイン後、License Agreement を確認して、必要事項を入力後、[Agree and access repository] をクリックします。
同意すると、上部に [Gated model you have been granted access to this model] と表示されます。
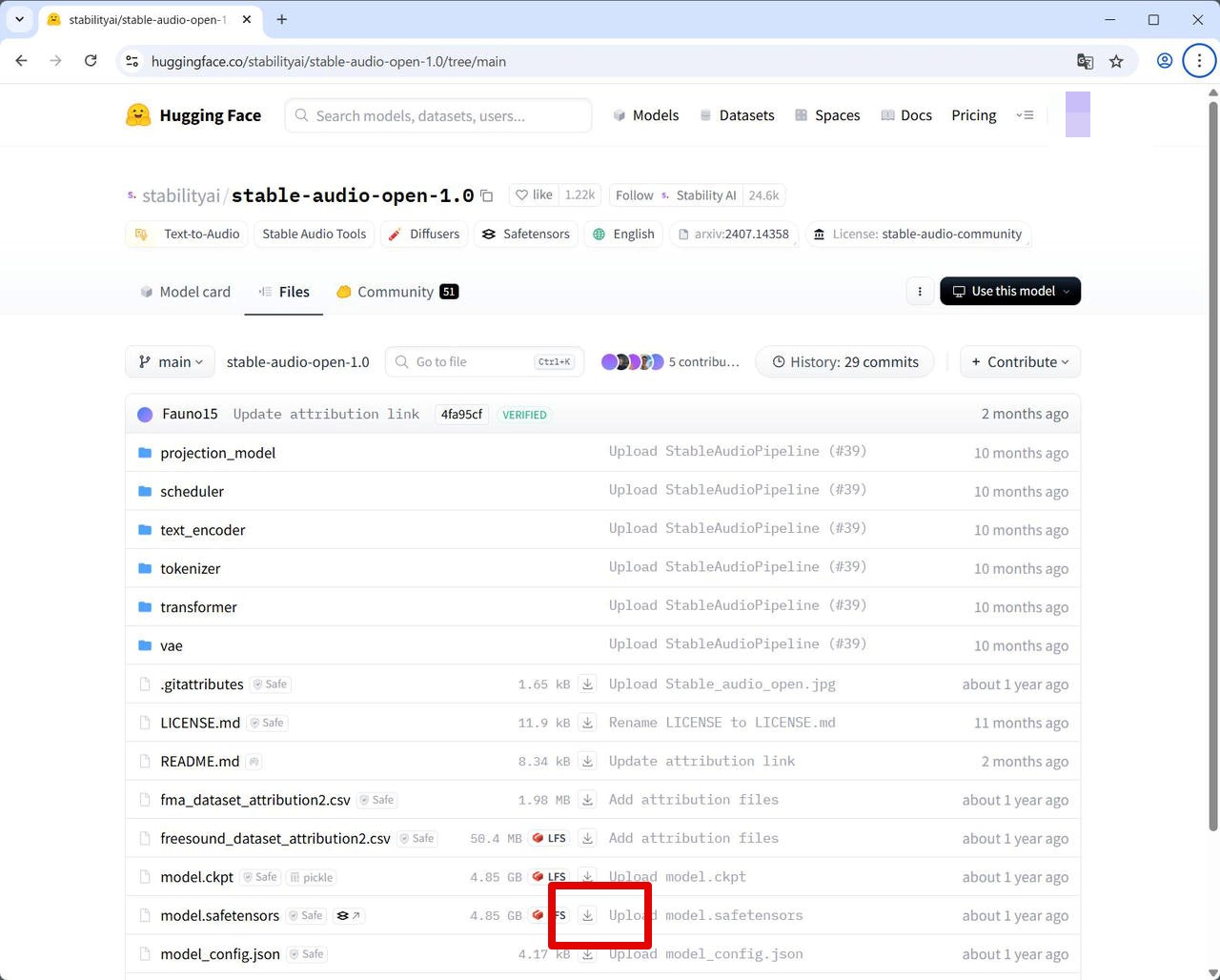
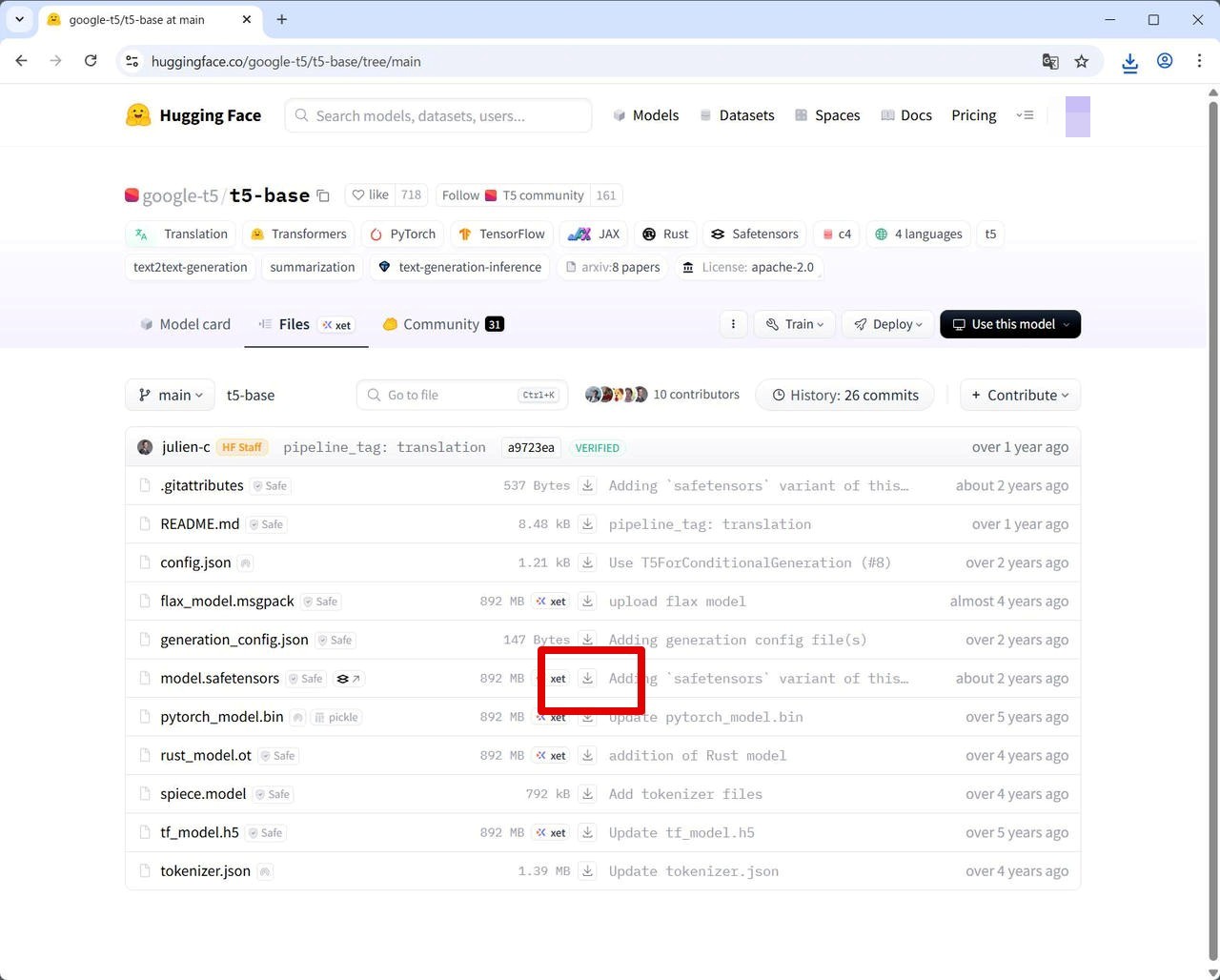
[Files] タブをクリックして、model.safetensors の右側のダウンロードボタンからダウンロードします。
保存する際のファイル名は、stable_audio_open_1.0.safetensors としておきます。(あるいはダウンロード後にリネームしておきます。)
(2) テキストエンコーダのダウンロード
以下のページから Text-To-Text Transfer Transformer(T5) をダウンロードします。プロンプトとして入力したテキストの変換に利用します。
https://huggingface.co/google-t5/t5-base
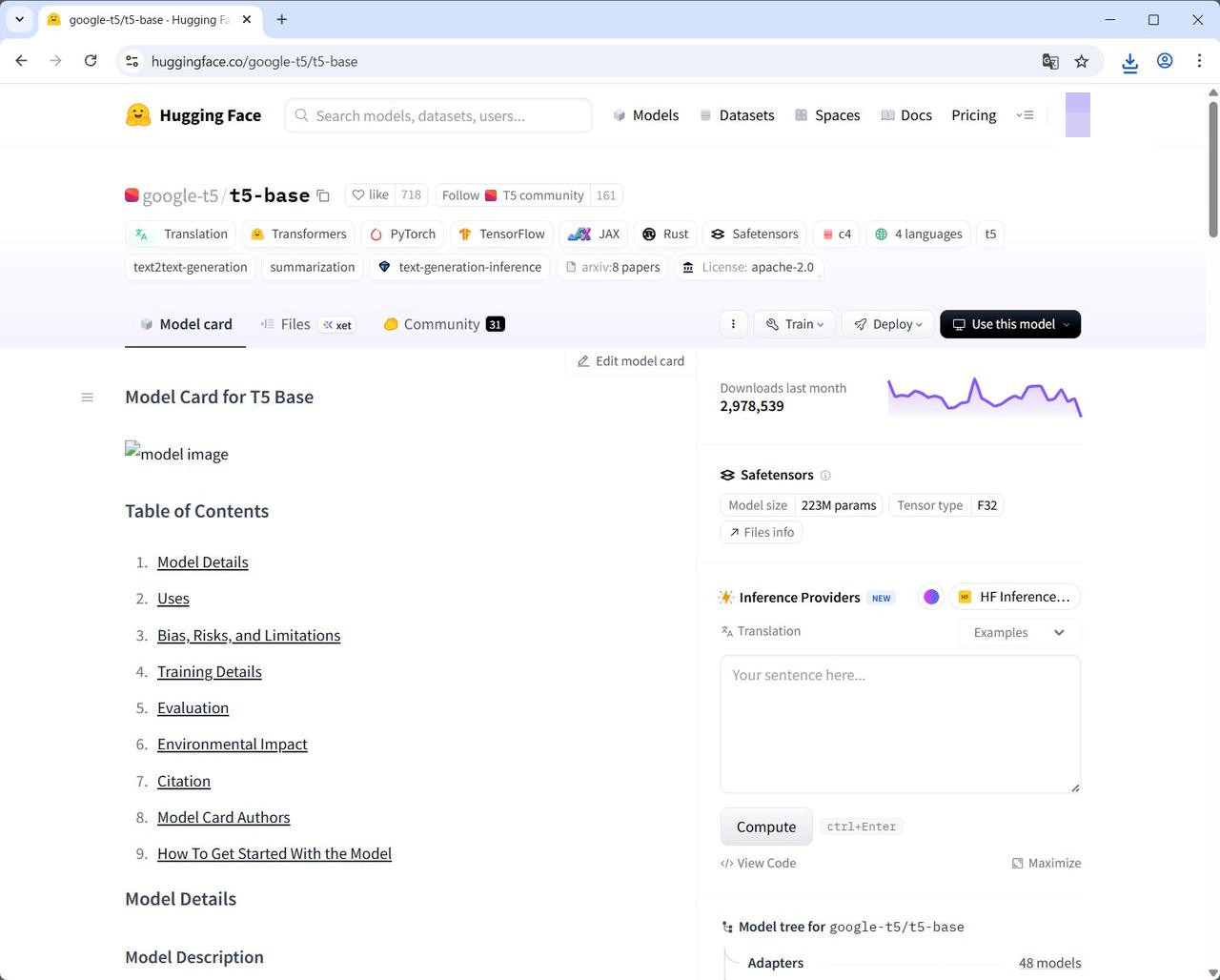
[Files] タブをクリックして model.safetensors の右側のダウンロードボタンからダウンロードします。
保存する際のファイル名は、t5_base.safetensors としておきます。(あるいはダウンロード後にリネームしておきます。)
(3) サンプルワークフローを含む音声ファイルのダウンロード
ComfyUI のサンプルページから、ワークフローを含む音声ファイル (stable_audio_example.flac) をダウンロードします。
https://comfyanonymous.github.io/ComfyUI_examples/audio
一番下の [download] を右クリックして、名前を付けてリンク先を保存 から保存できます。
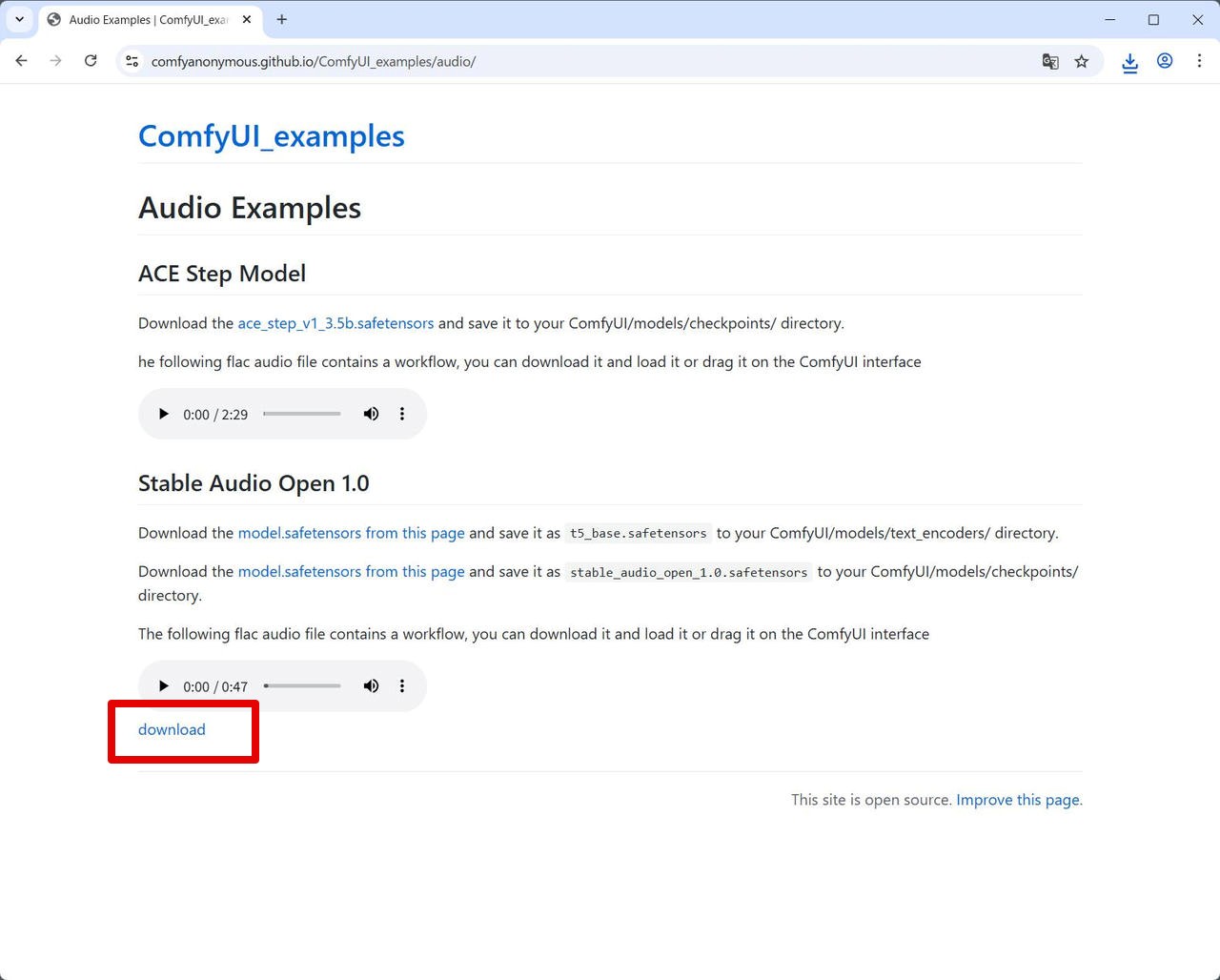
ダウンロードしたファイルの配置
Stability Matrix で用意した ComfyUI だと、オリジナルの ComfyUI とは違う場所にそれぞれのファイルを配置します。
(1) stable_audio_open_1.0.safetensors
- StabilityMatrixのインストールフォルダ\Data\Models\StableDiffusion
例) C:\StabilityMatrix にインストールした場合
C:\StabilityMatrix\Data\Models\StableDiffusion
(2) t5_base.safetensors
- StabilityMatrixのインストールフォルダ\Data\Models\TextEncoders
例) C:\StabilityMatrix にインストールした場合
C:\StabilityMatrix\Data\Models\TextEncoders
もし Stability Matrix 共通のフォルダではなくて、Stability Matrix でインストールされた ComfyUI のフォルダに配置したい場合は、https://comfyuidoc.com/ja/Examples/audio/ を参考に、StabilityMatrixのインストールフォルダ\Data\Packages\ComfyUI 配下の対象のフォルダに置きます。
ComfyUI の起動と、Stable Audio Open による音声の生成
(1) Stability Matrix から Package – ComfyUI を起動します。
(2) ComfyUI 起動後、WebUI にアクセスします。
(3) ダウンロードしていたサンプルワークフローを含む音声ファイル stable_audio_example.flac をドラックアンドドロップします。
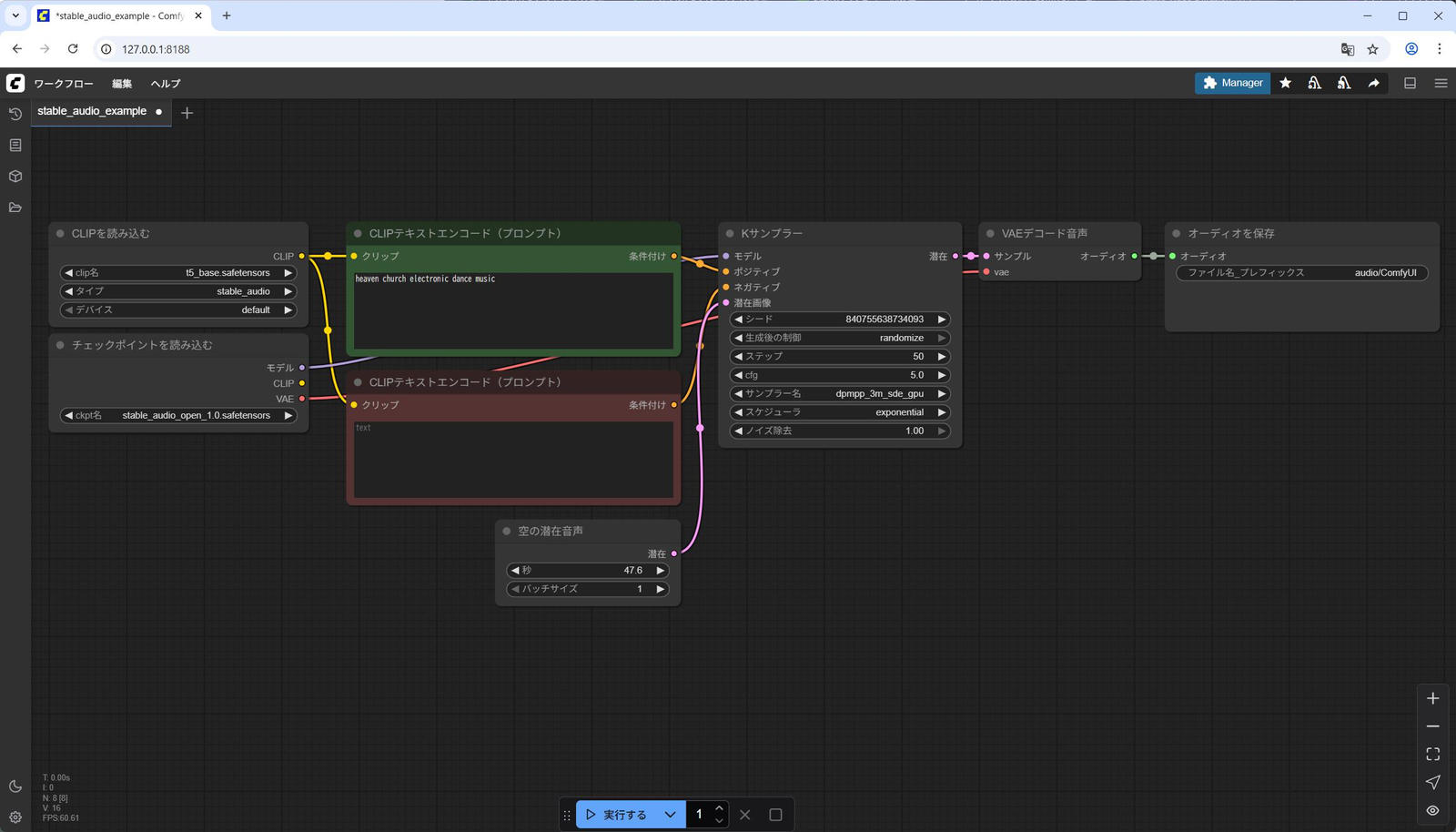
以下が選択されているか確認します。違うファイル名で保存していた場合は適切なものに選択します。
ドロップダウンに表示されない場合は、配置場所が間違っている可能性があります。
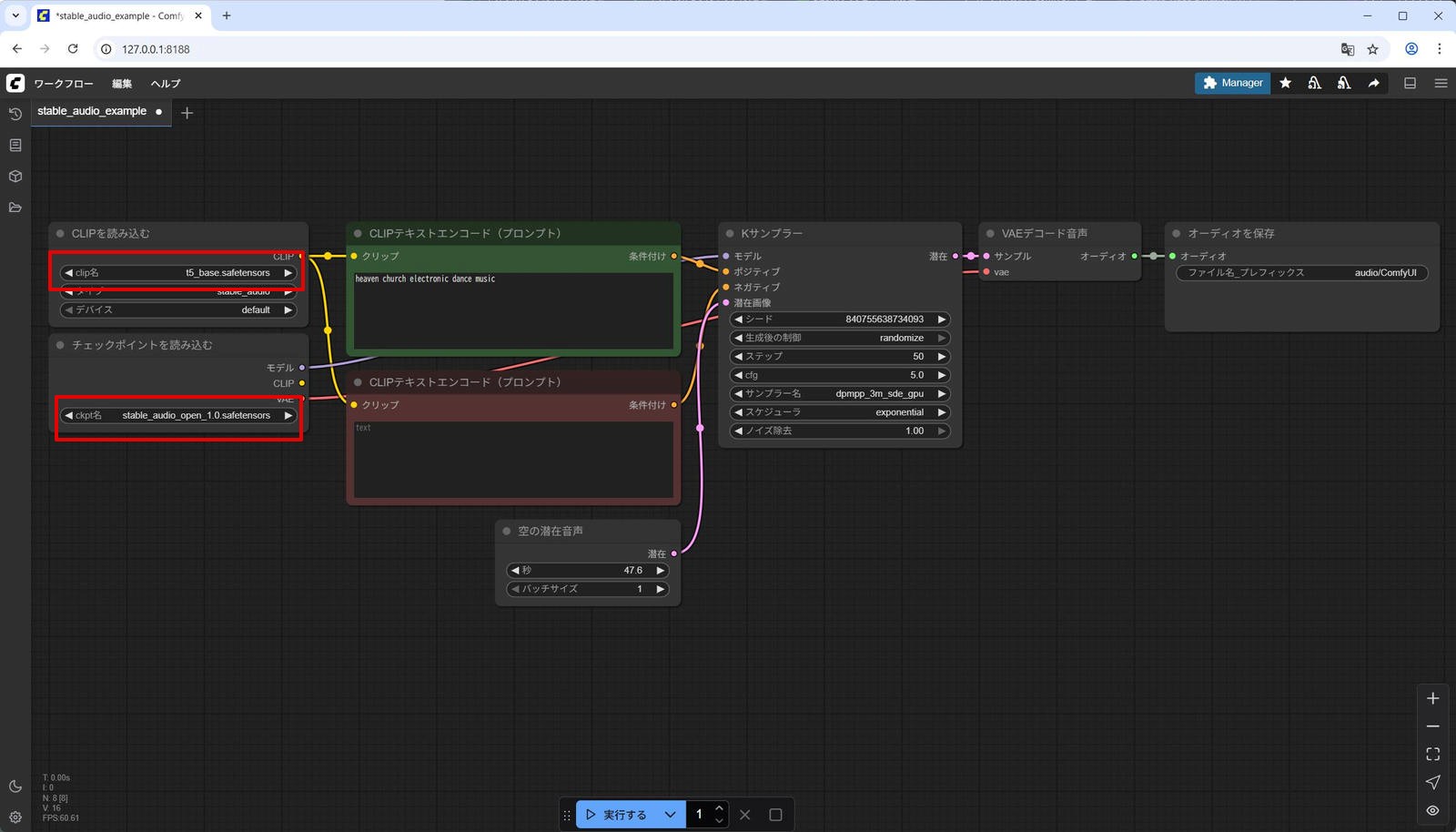
- [CLIP を読み込む] ノード – [clip名] : t5_base.safetensors
- [チェックポイントを読み込む] ノード – [ckpt名] : stable_audio_open_1.0.safetensors
(4) ワークフローを実行します。
私の環境で、初回実行時は 15秒程度、2回目以降 VRAMにすでに読み込み済みの場合は 9秒程度で生成できました。
生成されたファイルの保存先は StabilityMatrixのインストールフォルダ\Data\Images\Text2Img\audio です。
(C:\StabilityMatrix\Data\Images\Text2Img\audio など)
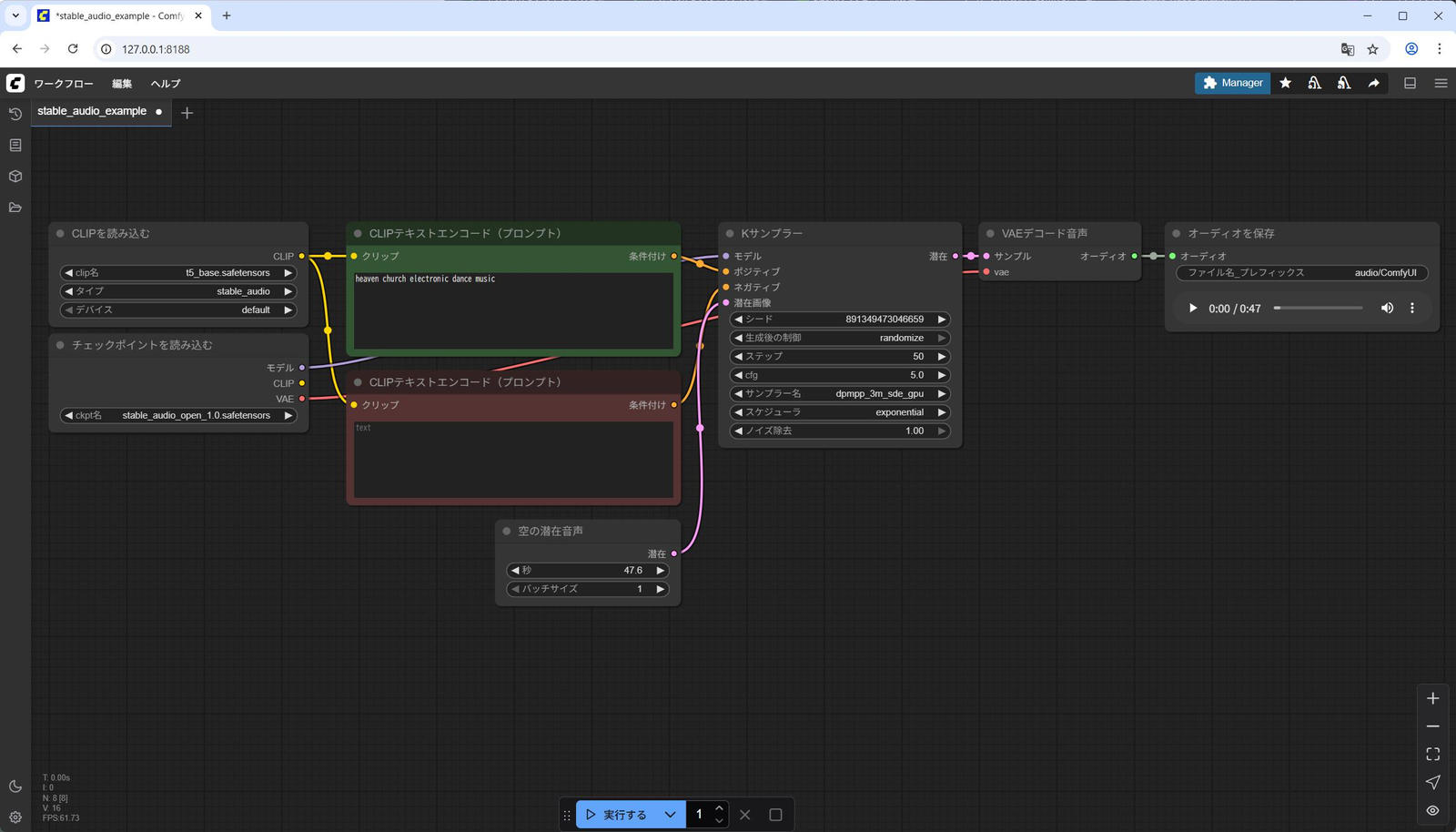
生成された音声ファイルは以下です。
参考となれば幸いです。
▼ 関連