
概要
アニメ・イラストに特化した画像生成モデルの Anima の正式版がリリースされているので、手元の環境で試してみました。
Anima とは
Anima は、CircleStone Labs と Comfy Org が共同開発している、2B(20億)パラメータの画像生成AIモデルです。
主に アニメ・イラスト・非写実系アート に特化しており、リアル写真風よりも、アニメ調やアーティスティックな表現を得意としています。
公式サイト
https://huggingface.co/circlestone-labs/Anima
ローカル実行環境の用意
PC 環境
NVIDIA GeForce RTX 5060 Ti 16GB を搭載した自作 PC を使用します。

Stability Matrix + ComfyUI の実行環境の用意
ComfyUI は、以前 Stability Matrix で用意したものを使います。準備方法については、過去記事をご参照ください。

Stability Matrix と ComfyUI のアップデート
古いバージョンだと正常に動作しない可能性があるため、事前に更新しておきます。
- Stability Matrix – Settings – アップデート
- Stability Matrix – パッケージ – ComfyUI の更新
以下では、
Stability Matrix 2.15.8
ComfyUI v0.21.1
で試しています。
必要なモデルファイルのダウンロード
(1) 必要なモデルファイルをダウンロードします。
- diffusion_models / anima-base-v1.0.safetensors
https://huggingface.co/circlestone-labs/Anima/resolve/main/split_files/diffusion_models/anima-base-v1.0.safetensors - text_encoders / qwen_3_06b_base.safetensors
https://huggingface.co/circlestone-labs/Anima/resolve/main/split_files/text_encoders/qwen_3_06b_base.safetensors - vae / qwen_image_vae.safetensors
https://huggingface.co/circlestone-labs/Anima/resolve/main/split_files/vae/qwen_image_vae.safetensors
ファイルの配置
ダウンロードしたファイルを以下のフォルダに置きます。
※ Stability Matrix ではなく、ComfyUI を直接インストールしている場合は適宜読み替えてください。
(1) Diffusion Model
anima-base-v1.0.safetensors
→ StabilityMatrix のインストールフォルダ\Data\Models\TextEncoders\Data\Models\DiffusionModels
(2) テキストエンコーダ
qwen_3_06b_base.safetensors
→ StabilityMatrix のインストールフォルダ\Data\Models\TextEncoders
(3) VAE
qwen_image_vae.safetensors
→ StabilityMatrix のインストールフォルダ\Data\Models\TextEncoders\Data\Models\VAE
C:\StablilityMatrix にインストールしている場合は以下のような形になります:
C:\STABILITYMATRIX\DATA\MODELS
├─DiffusionModels
│ anima-base-v1.0.safetensors
│
├─TextEncoders
│ qwen_3_06b_base.safetensors
│
└─VAE
qwen_image_vae.safetensors画像生成を試してみる
まずは、ComfyUI から読み込めるワークフローを使ってそのまま画像生成します。
(1)
左側 [テンプレート] – anima で検索 – [Anima : アニメ文生図] をクリックします。
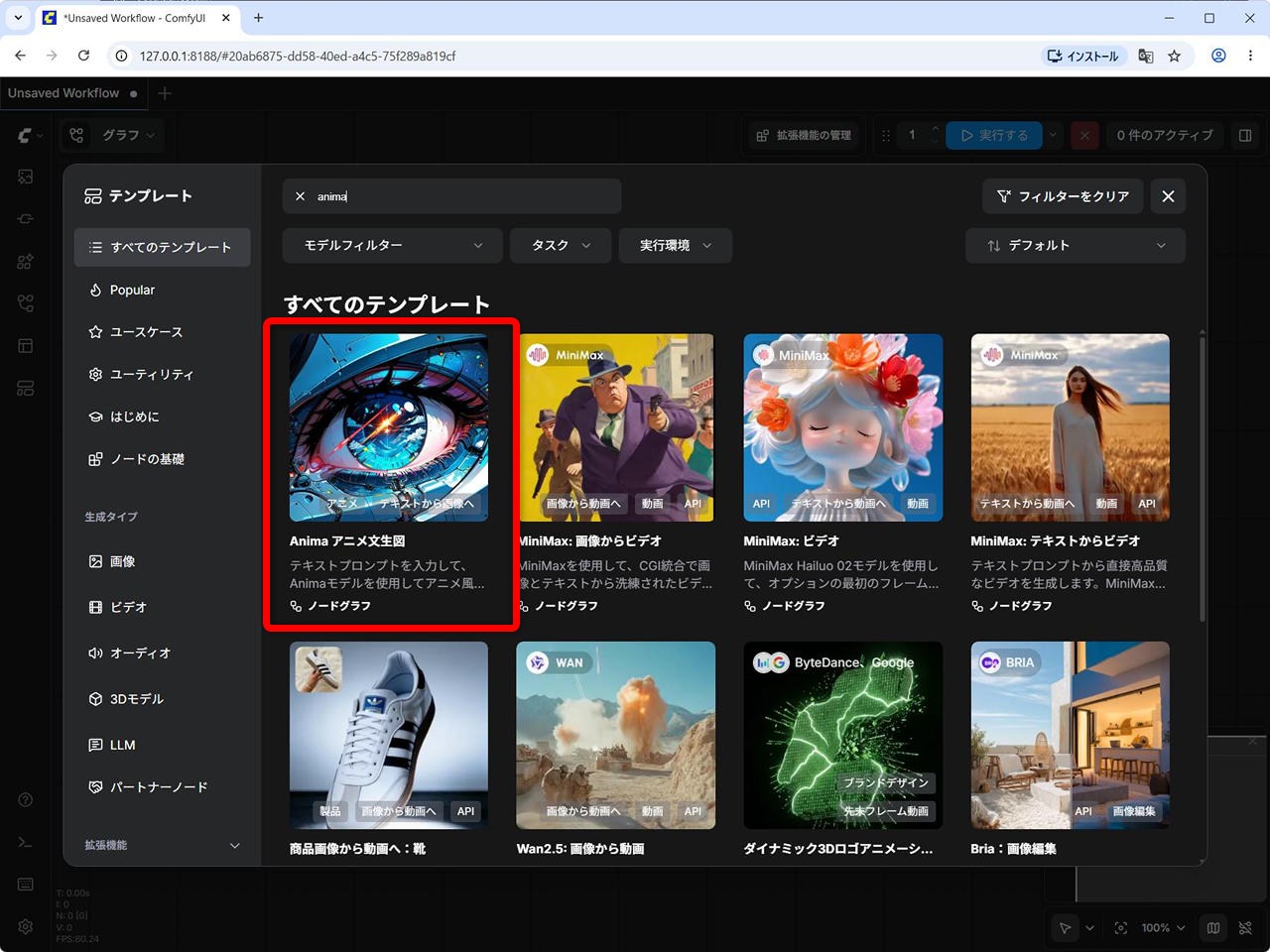
(2)
本稿更新時点だと、ワークフロー内の unet_name が preview3 のモデル名になっていて、エラーとなるので、正式リリース版の anima-base-v1.0.safetensors に変更します。
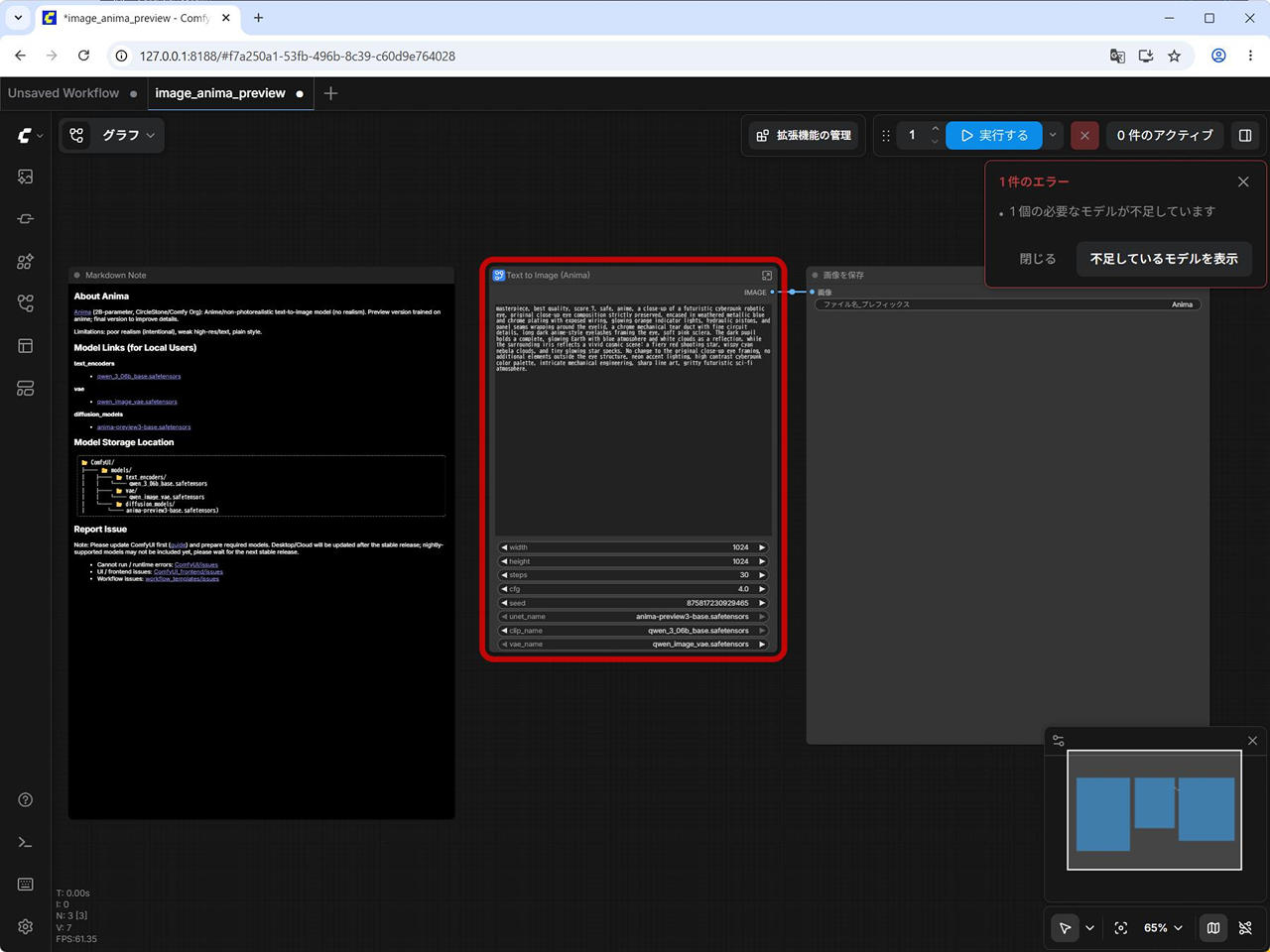
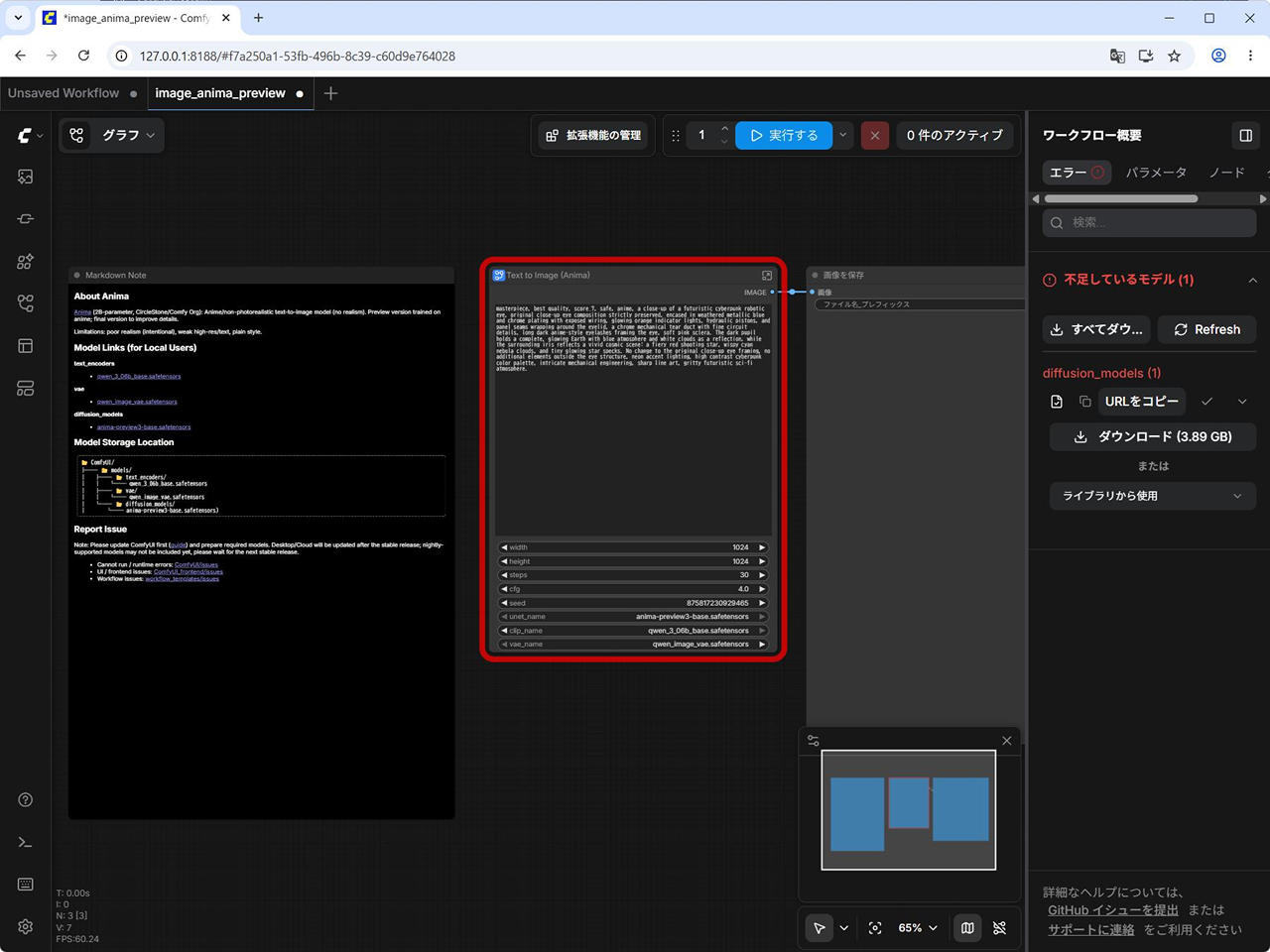
![[Text to Image (Anima)] の unet_name を変更する](https://iwannacreateapps.com/wp-content/uploads/2026/05/Anima_04.jpg)
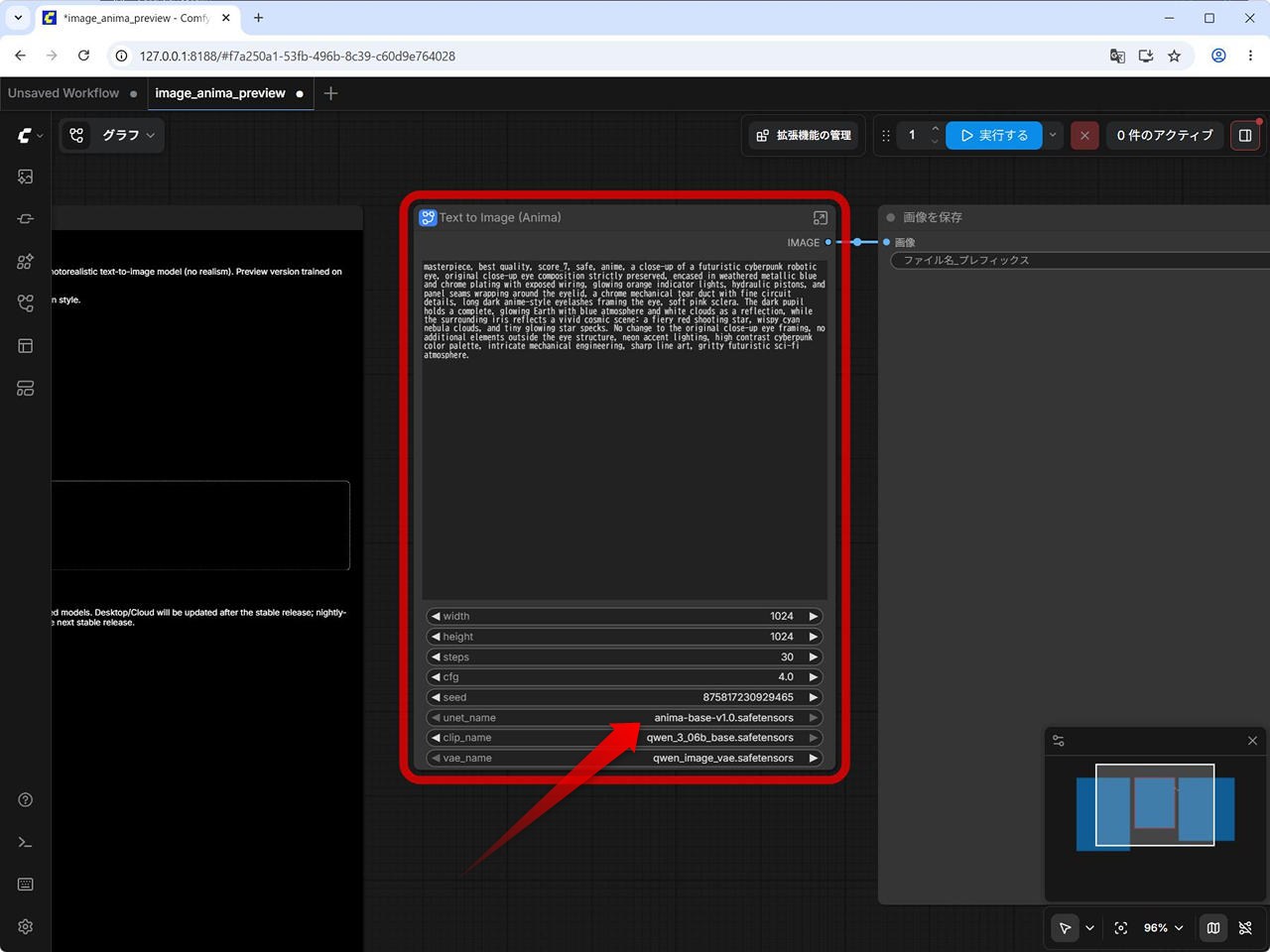
(3)
他は、特に変更せずそのまま生成してみます。
実行時間 : 約38秒
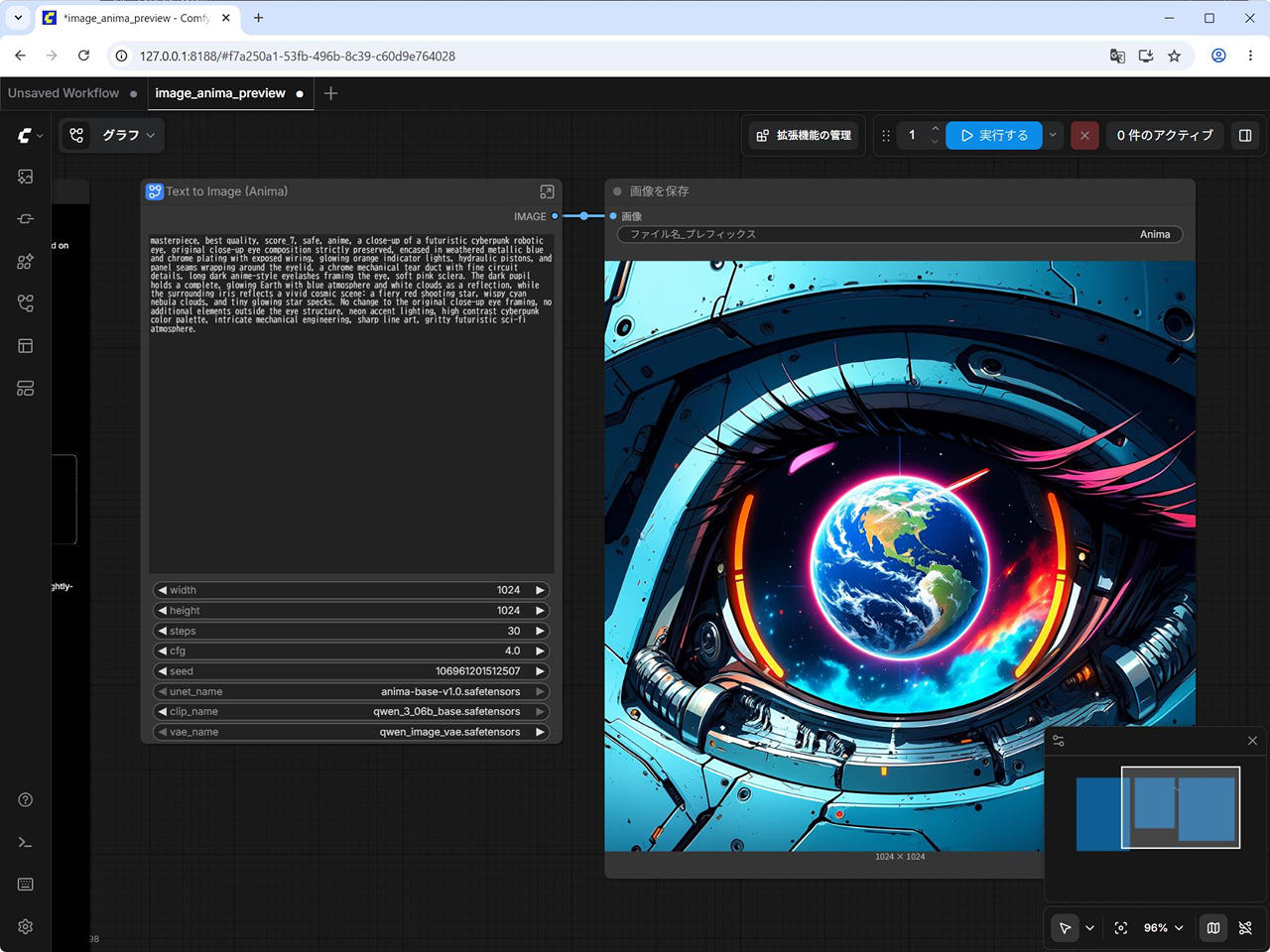
テンプレートの画面に表示されていた画像が生成できます。

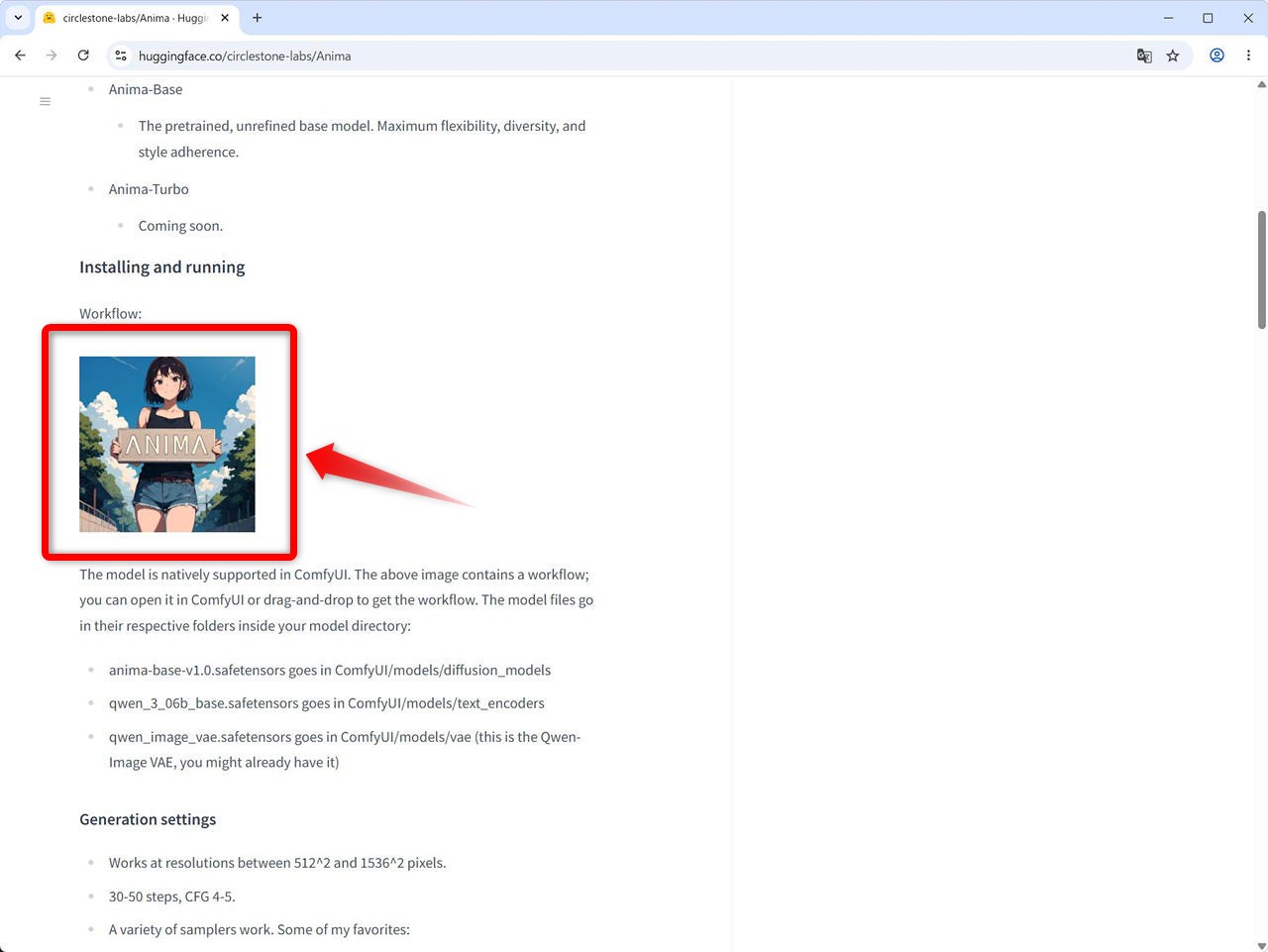
Hugging Face にあるのと同じ画像を生成してみる。
次に、Hugging Face に掲載されているサンプル画像と同じ条件で生成してみます。
以下の画像です。
この画像にはワークフローが埋め込まれているため、ダウンロードして ComfyUI で読み込むと、ワークフローやプロンプトを確認できます。
入力するプロンプトや Seed は以下です。
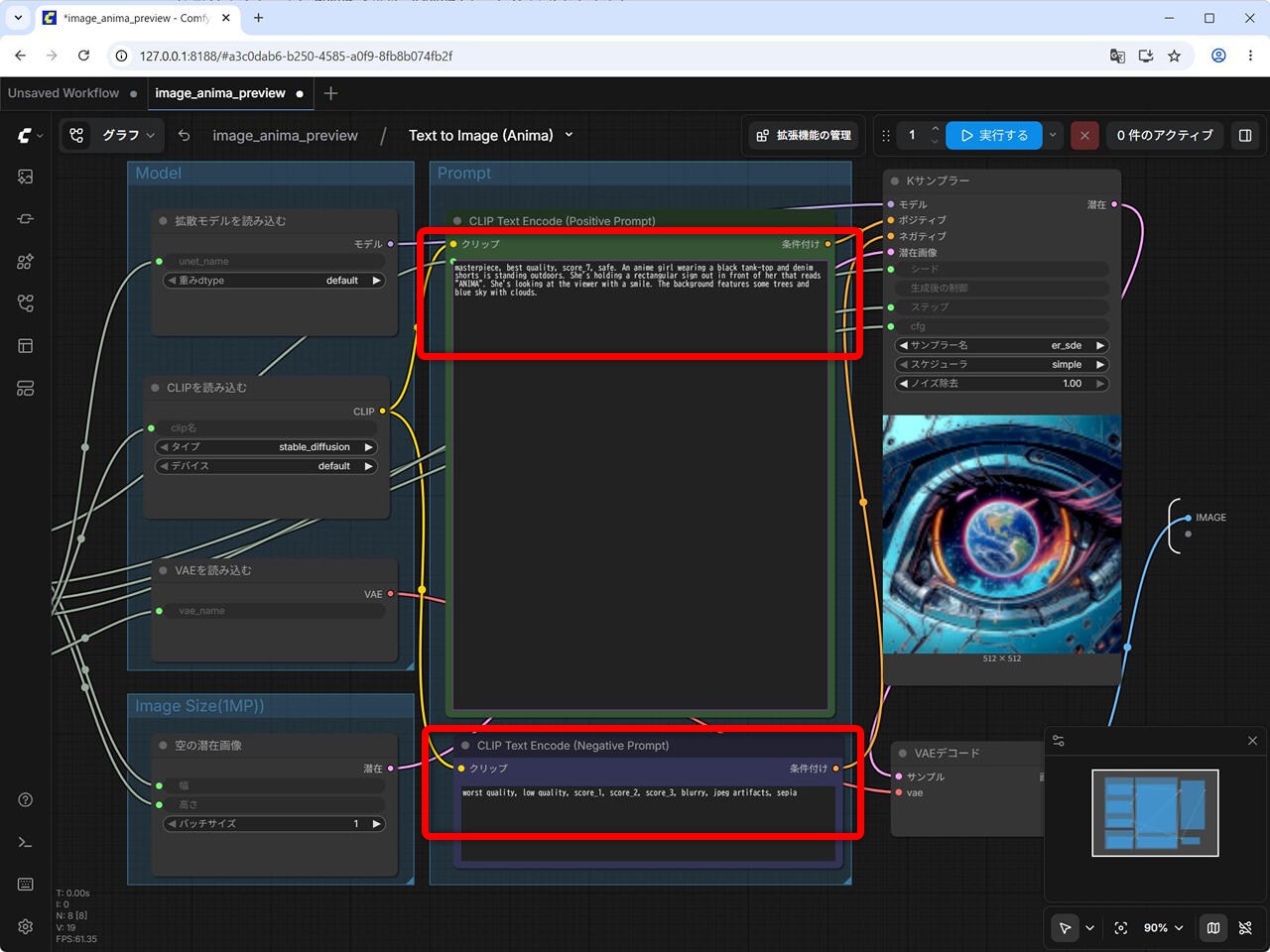
Prompt
masterpiece, best quality, score_7, safe. An anime girl wearing a black tank-top and denim shorts is standing outdoors. She's holding a rectangular sign out in front of her that reads "ANIMA". She's looking at the viewer with a smile. The background features some trees and blue sky with clouds.
Negative Promptworst quality, low quality, score_1, score_2, score_3, blurry, jpeg artifacts, sepia
Seed
856853657535148
(1) Negative Prompt を確認、入力するためにサブグラフを開きます
[Text to Image (Anima)] のノードの右上の [Subgraph node for Text to Image (Anima)] のボタンをクリックします。
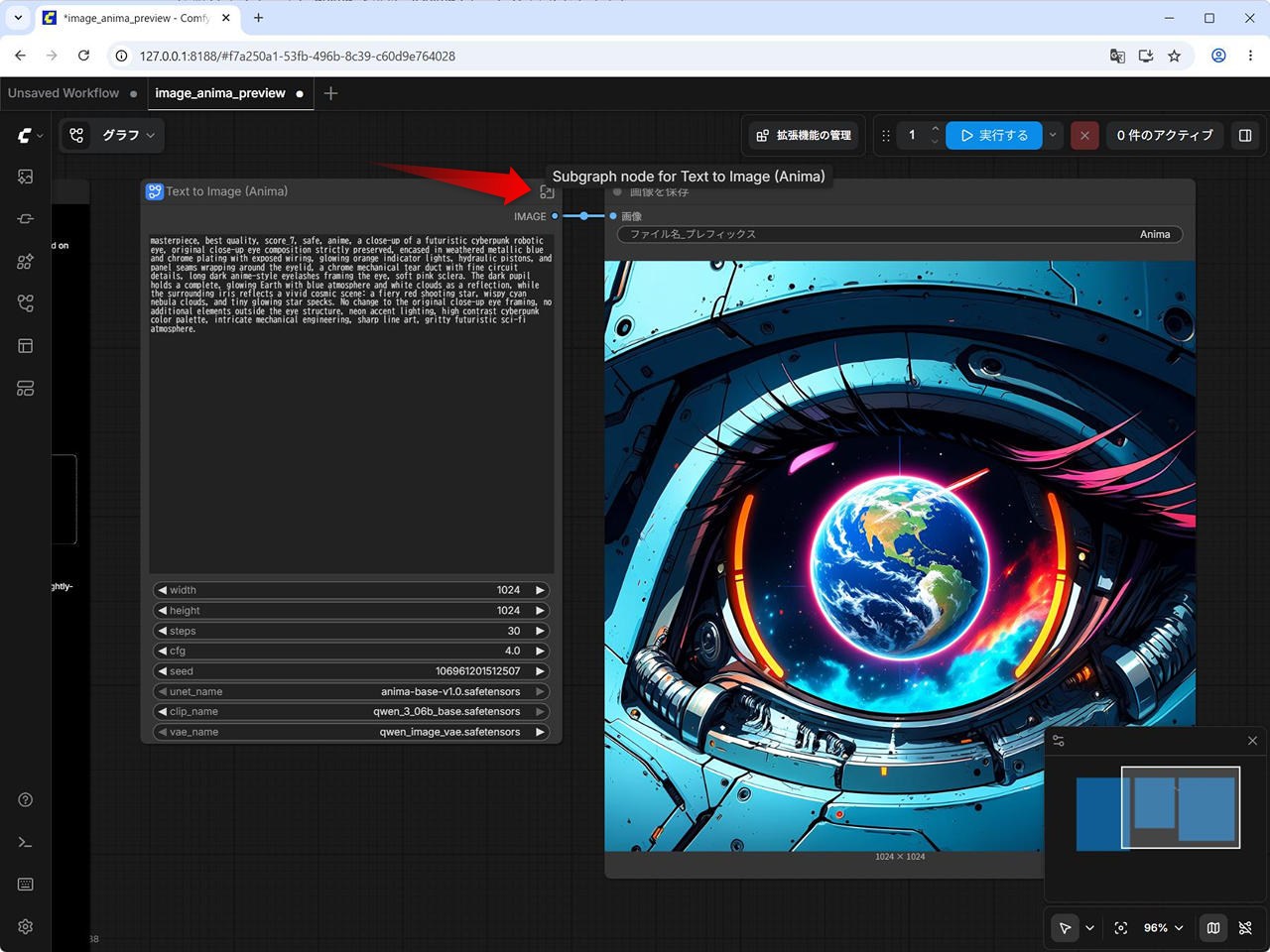
Prompt と Negative Prompt を入力します。
(2) メイングラフ側に戻って Seed を入力して開始します。
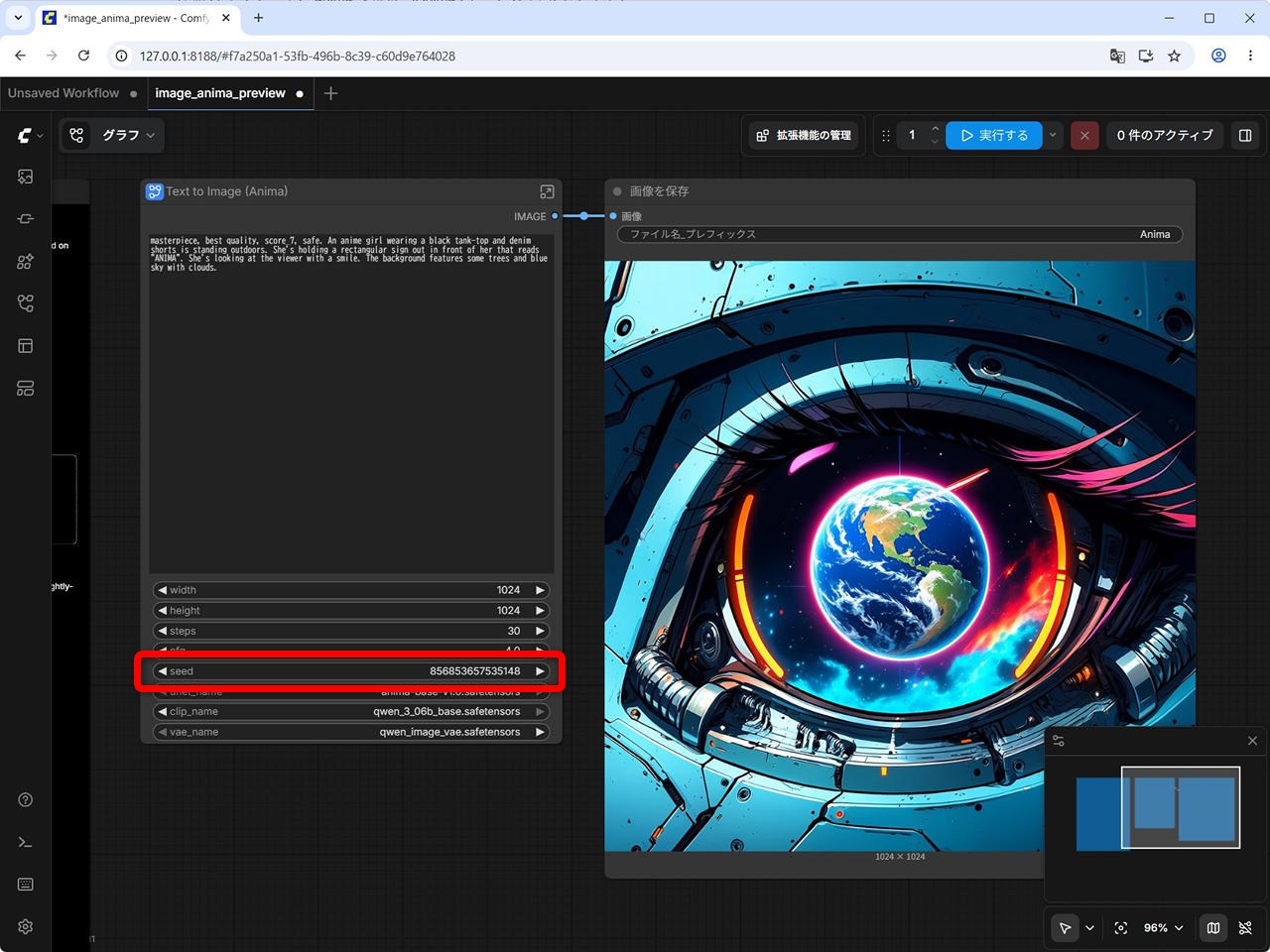
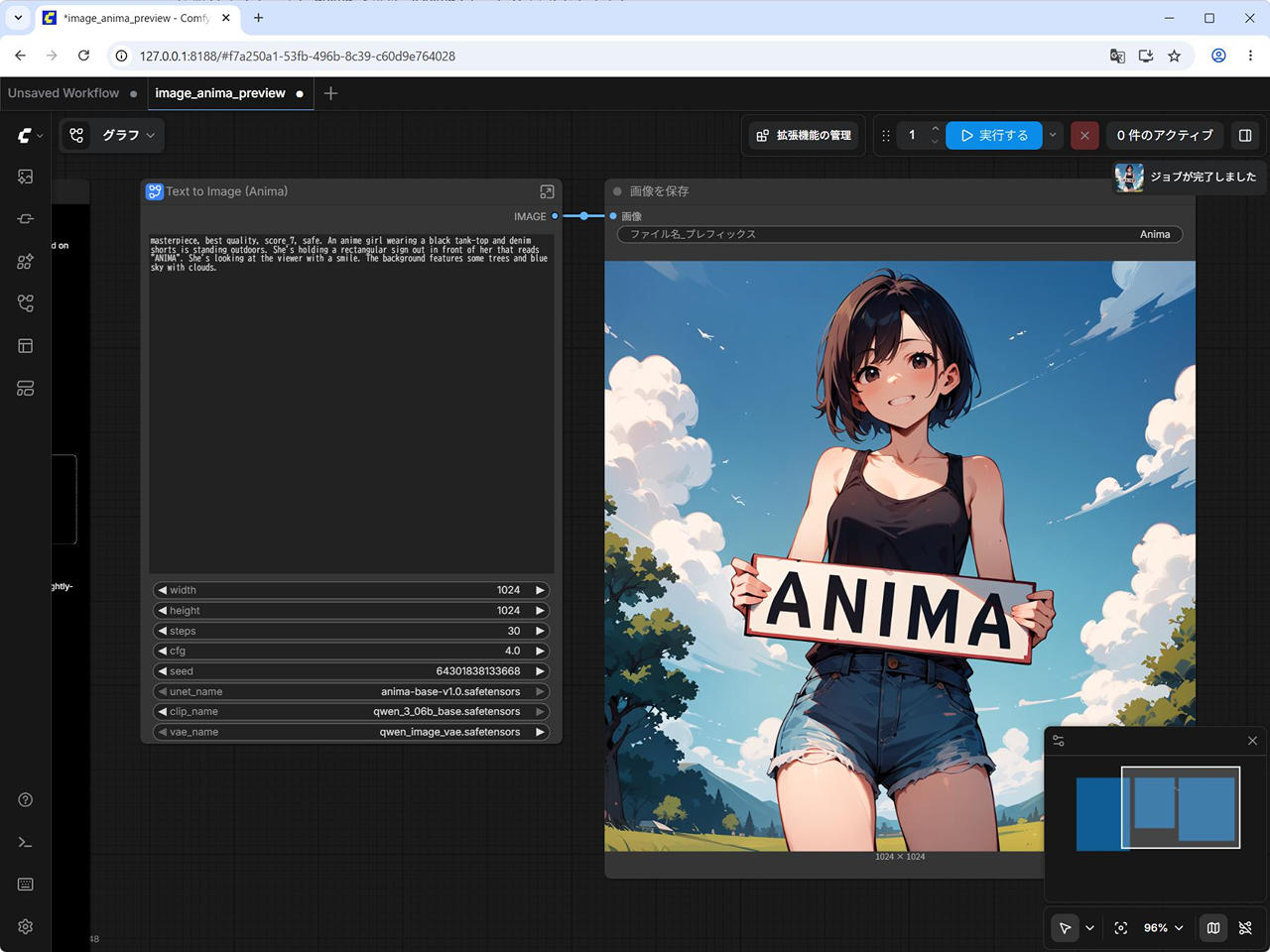
生成時間 : 30秒
Preview3 のモデルではなく、正式リリースの base v1.0 を使っているので、サイトとは若干違うものが生成されますね。

柴犬の鼻ドアップ画像を生成してみる。
続いて、プロンプトを工夫しながら、柴犬の鼻のドアップ画像を生成してみます。
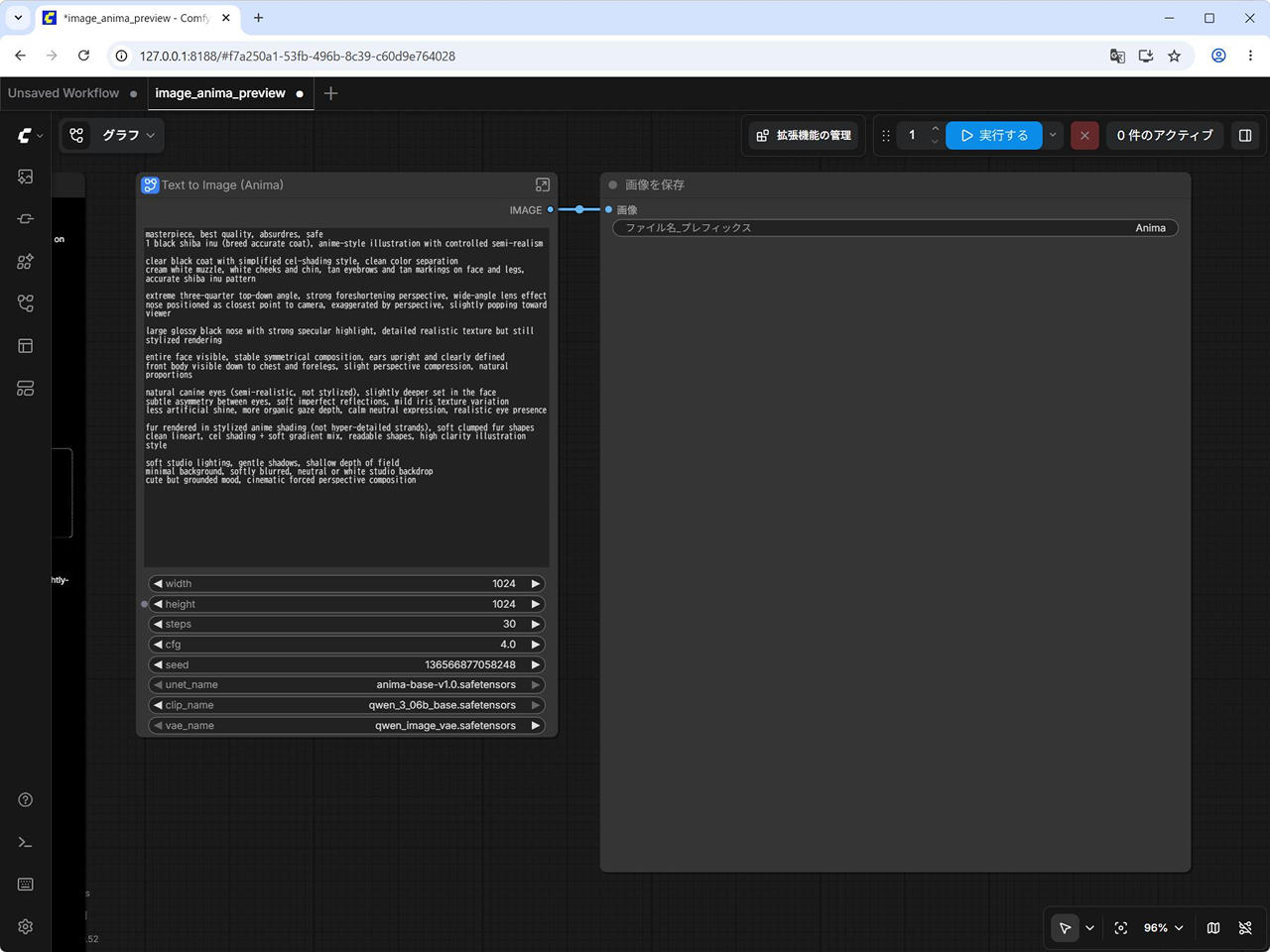
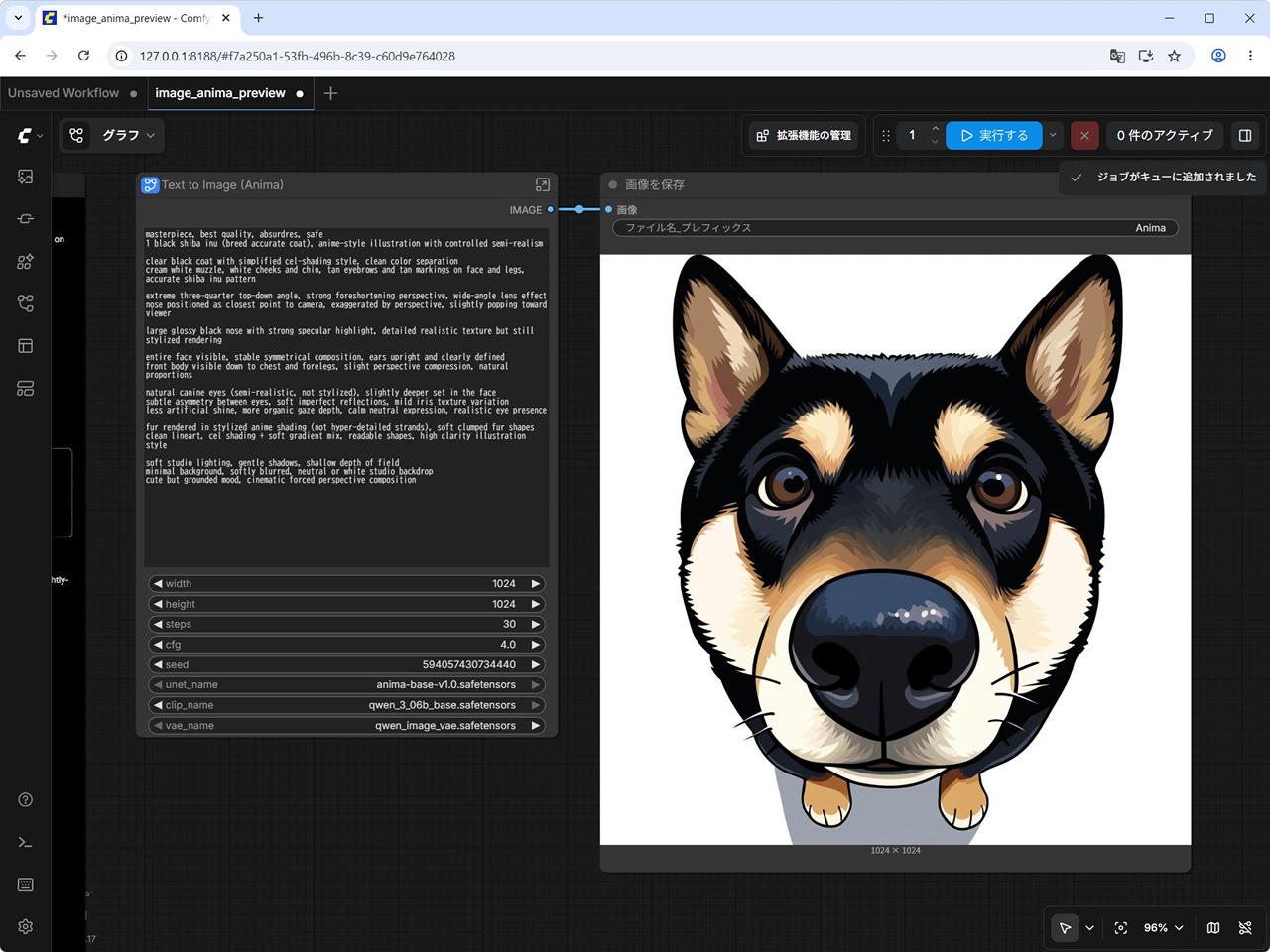
生成した画像は以下です。
Anima はプロンプトへの追従性が比較的高いとされているため、プロンプトをさらに調整すれば、より安定した出力が得られそうです。

Anima の推奨生成設定・プロンプト仕様について
Hugging Face には、ワークフロー設定やプロンプト記法についても説明があります。
概要をまとめてみると以下のような感じでしょうか。
Anima は、Danbooru系タグと自然文の両方に対応した、アニメ・イラスト特化型の画像生成モデルです。タグのみ、自然文のみ、あるいは両方を混在したプロンプトが利用できます。
生成設定としては、1024×1024 前後の約 1MP 解像度が推奨されており、Steps は 30~50、CFG は 4~5 が目安です。Sampler は複数対応していますが、er_sde はシャープで安定した画風、euler_a は柔らかめで 2.5D 寄り、dpmpp_2m_sde_gpu はよりクリエイティブな出力傾向とされています。
プロンプトでは、小文字・スペース区切りタグを推奨しており、long hair のように記述します。例外として score_7 などの score 系タグのみアンダースコアを使用します。推奨プロンプト例は以下のような形です。
masterpiece, best quality, score_7, safe
ネガティブプロンプトでは、
worst quality, low quality, score_1, score_2, score_3
などが推奨されています。
タグ順は、
品質/メタ/年代/安全 → 人数 → キャラクター → 作品名 → 絵師 → 一般タグ
が推奨されています。絵師タグは @artist_name のように @ を付ける必要があります。
自然文プロンプトにも対応しており、例えば
Digital artwork of Fern from Sousou no Frieren...
のようにキャラクター名と外見説明を組み合わせることで安定しやすくなるとされています。特に複数キャラクター生成時は、外見説明を含めることが重要です。
参考となれば幸いです。
▼ 関連