
概要
高速に画像を生成できるとされている画像生成 AI モデルの Z-Image をローカル環境で試してみました。
一般的な GPU (NVIDIA GeForce RTX 5060Ti 16GB) でも快適に動作するといえるでしょう。
Z-Image とは
Z-Image は、Alibaba(正確にはその研究部門である Tongyi‑MAI)が開発した画像生成のための基盤モデルです。
6B パラメータを備えた高性能かつ非常に効率的な画像生成モデルで、 3 つのバリエーションがあります。
https://github.com/Tongyi-MAI/Z-Imageから抄訳
- Z-Image-Turbo
Z-Image を元に蒸留して作られた高速・軽量モデルです。
わずか 8ステップ (NFE/Number of Function Evaluations) で主要な競合モデルと同等、もしくはそれ以上の品質を実現します。
エンタープライズ向けの H800 GPU では1秒未満の推論 が可能で、16GB VRAM の一般的な GPU でも快適に動作するとされています。
フォトリアルな画像生成、英語と中国語のテキスト描画、そして高い指示追従能力が強みです。- Z-Image-Base (今後リリース予定)
蒸留前のオリジナルモデルとなる基盤バージョンです。
このチェックポイントが公開されたことで、コミュニティが独自にファインチューニングしたり、カスタムモデルを開発したりといった幅広い応用が可能になります。- Z-Image-Edit (今後リリース予定)
画像編集タスクに特化して Z-Image をファインチューニングした派生モデルです。
自然言語での指示に基づいて、既存画像の修正やスタイル変更など、柔軟なイメージ・トゥ・イメージ生成ができます。
公式サイト
公式サイト
https://github.com/Tongyi-MAI/Z-Image
HuggingFace
https://huggingface.co/Tongyi-MAI/Z-Image-Turbo
現在は、Z-Image-Turbo が利用可能です。
ライセンス
オープンソースとして公開されており Apache 2.0 ライセンスです。商用利用も可能です。https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.md
ローカル実行環境の用意
参考情報
ComfyUI の情報を参考にしています。
https://comfyanonymous.github.io/ComfyUI_examples/z_image
今回は Comfy Org による再パッケージ版のモデルを利用します。
https://huggingface.co/Comfy-Org/z_image_turbo
PC 環境
NVIDIA GeForce RTX 5060Ti 16GBを入れて自作した PC で行います。

Stability Matrix + ComfyUI の実行環境の用意
ComfyUI は、以前 Stability Matrix で用意したものを使います。準備方法はこの過去記事をご参照ください。

必要なファイルのダウンロード
今回は、Stability Matrix のフォルダに配置するため手動で全部用意します。
テキストエンコーダ、VAE、拡散モデルは、Comfy Org の hugginface にアクセスして、それぞれダウンロードボタンからダウンロードします。
テキストエンコーダ
https://huggingface.co/Comfy-Org/z_image_turbo/tree/main/split_files/text_encoders
qwen_3_4b.safetensors
VAE
https://huggingface.co/Comfy-Org/z_image_turbo/tree/main/split_files/vae
ae.safetensors
Diffusionモデル
https://huggingface.co/Comfy-Org/z_image_turbo/tree/main/split_files/diffusion_models
z_image_turbo_bf16.safetensors
ワークフローは ComfyUI Examples からダウンロードします。
ワークフロー
https://comfyanonymous.github.io/ComfyUI_examples/z_image
ファイルの配置
ここで利用するのは Stability Matrix による ComfyUI 環境なので、ダウンロードしたテキストエンコーダ、VAE、Diffusion モデルは以下に配置します。
(1) テキストエンコーダ
StabilityMatrix のインストールフォルダ\Data\Models\TextEncoders
(2) VAE
StabilityMatrix のインストールフォルダ\Data\Models\TextEncoders\Data\Models\VAE
(3) Diffusion モデル
StabilityMatrix のインストールフォルダ\Data\Models\TextEncoders\Data\Models\DiffusionModels
C:\StablilityMatrix にインストールしている場合は以下のような形です:
C:\STABILITYMATRIX\DATA\MODELS
├─DiffusionModels
│ z_image_turbo_bf16.safetensors
├─TextEncoders
│ qwen_3_4b.safetensors
└─VAE
ae.safetensors画像の生成
準備
(1) Stability Matrix を起動し、Stability Matrix や ComfyUI を更新します。
古いバージョンだとうまく動かない可能性があるので更新しておきます。
- Stability Matrix – Settings – アップデート
- Stability Matrix – パッケージ – ComfyUI の更新
以下では、
Stability Matrix 2.15.4
ComfyUI v0.3.75
で試しています。
Z-Image Turbo (画像から画像)
ダウンロードしていた z_image_turbo_example.png を ComfyUI の WebUI にドラックアンドドロップして実行するだけでサンプルと同じものは生成できます。
より詳細には以下のとおりです:
- ワークフローが埋め込まれた画像ファイル
z_image_turbo_example.pngを ComfyUI の WebUI にドラッグアンドドロップします。 拡張モデルを読み込むノードがz_image_turbo_bf16.safetensorsモデルをロードしていることを確認します。CLIPを読み込むノードがqwen_3_4b.safetensorsモデルをロードしていることを確認します。VAEを読み込むノードがae.safetensorsモデルをロードしていることを確認します。実行をクリックします。
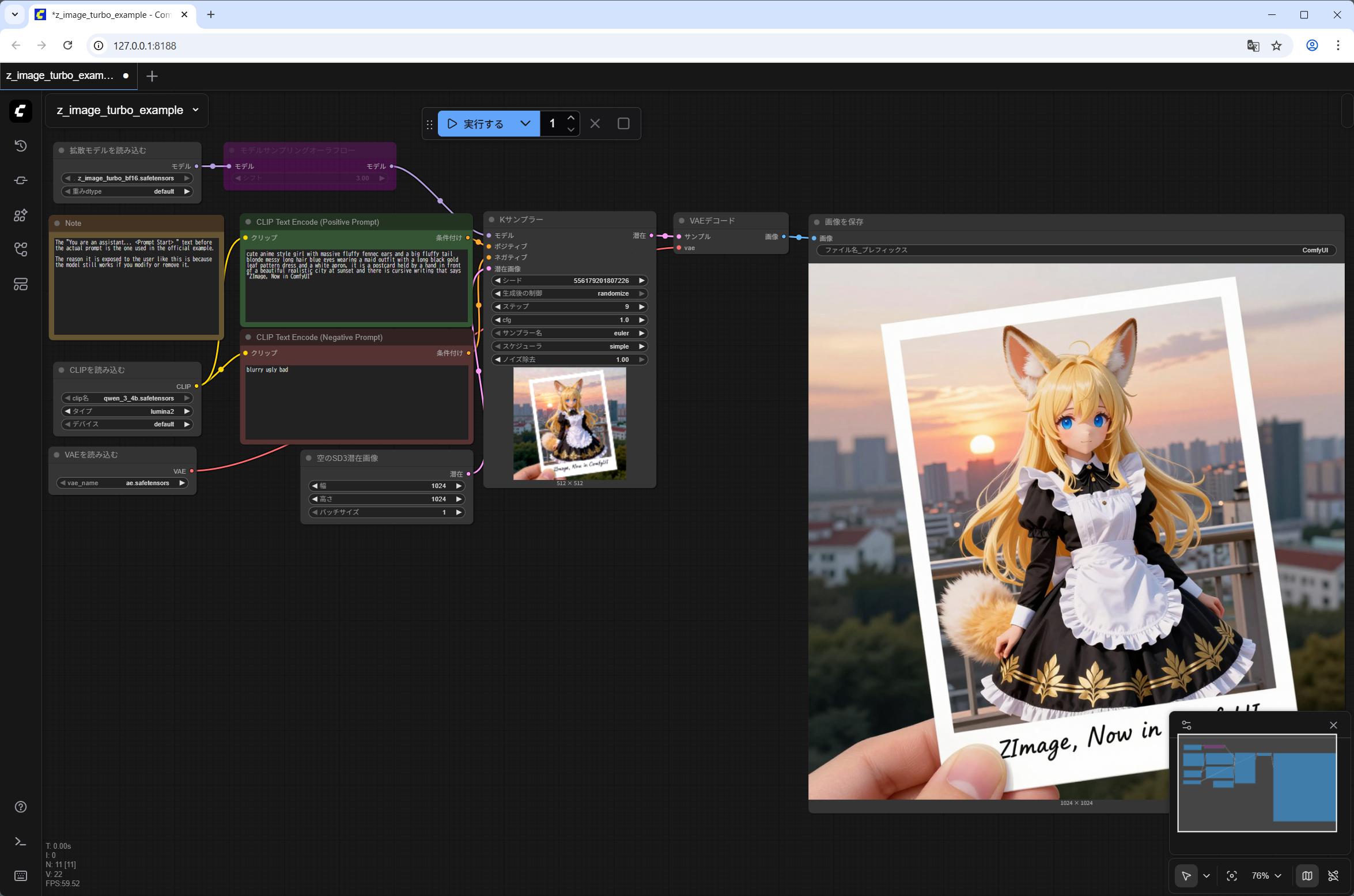
私の NVIDIA GeForce RTX 5060Ti 16GB の環境で 約 35秒かかりました。
一度モデルを VRAM にロードした後、プロンプトを変えての再実行だと約 22秒で生成できます。

Qwen Image の時と比べるために、同じ解像度 (1328 x 1328) に変更して、同じプロンプトを使ってみたところ、以下のような画像となりました。生成には 27秒くらいかかっています。これもよい感じの画像です。
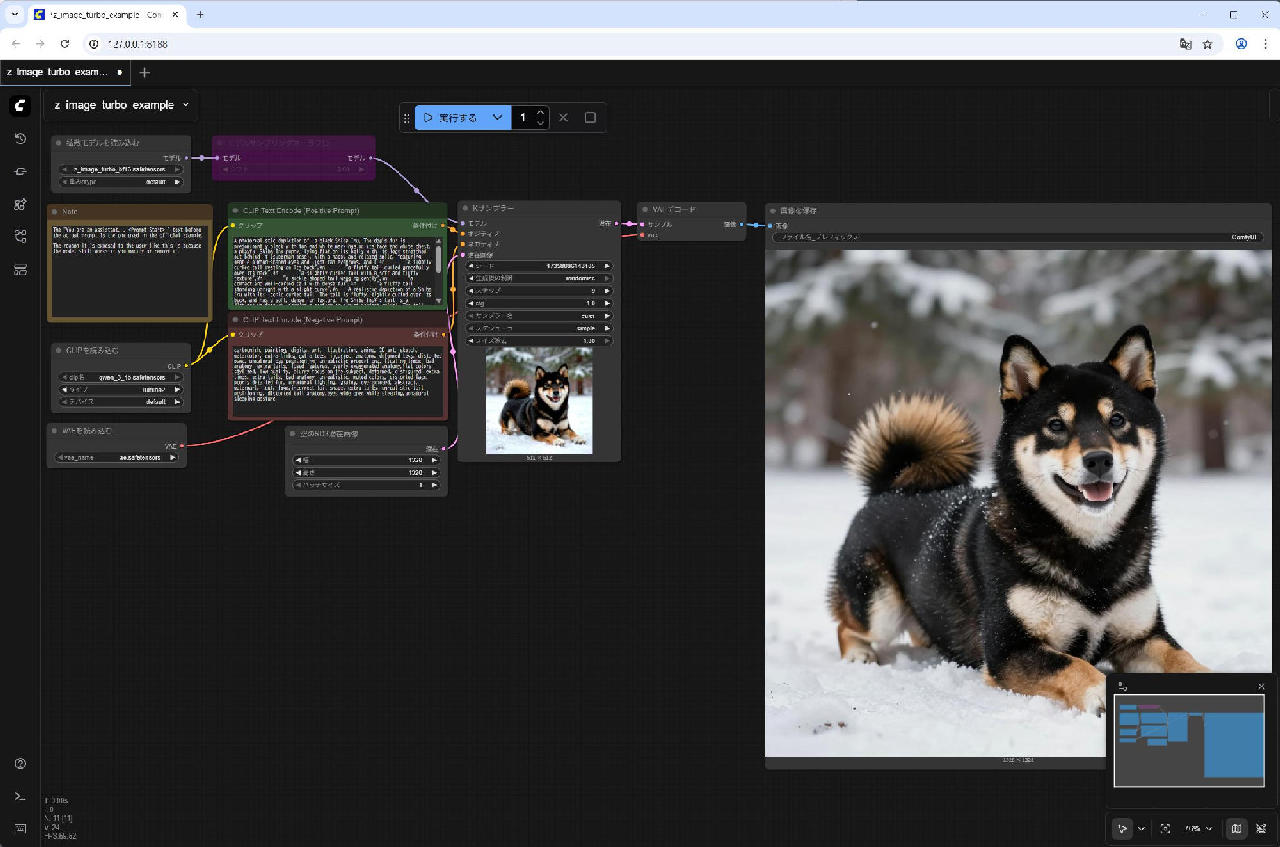

高速に画像を生成できるので、使い勝手は良さそうです。
参考となれば幸いです。
▼ 関連