
概要
Wan2.2 は、Alibaba などが関与するWAN‐AIチームによって開発された、動画生成用のマルチモーダルAIモデルです。
ローカル PC 上で Wan2.2 の実行環境を用意して試してみましたので記載しておきます。
生成される動画の質もよく、ミドルレンジのグラフィックカード NVIDIA GeForce RTX 5060Ti 16GB でもそこまで時間がかからず生成できました。
ここでは、以下の方法を記載しています。
- Text to Video (テキスト → 動画)
- Image to Video (画像 → 動画) : 開始画像のみ指定
- Image to Video (画像 → 動画) : 開始画像と、終了画像を指定
Wan2.2 とは
Wan2.2(WAN 2.2) は、Alibaba などが関与する WAN-Video チーム が開発した 動画生成AIモデル です。
本稿更新時点で、以下に対応したマルチモーダルAIです。
- Text to Video (テキスト → 動画, t2v)
- Image to Video (画像 → 動画, i2v)
- Text to Image (テキスト → 画像, t2i)
- Speech to Video (音声+画像 → 動画)
ComfyUI との統合も進められているので利用しやすいです。
公式サイト
https://wan.video
https://github.com/Wan-Video/Wan2.2
Hugging Face (モデルのダウンロードサイト)
https://huggingface.co/Wan-AI/Wan2.2-TI2V-5B
https://huggingface.co/Wan-AI/Wan2.2-I2V-A14B
https://huggingface.co/Wan-AI/Wan2.2-T2V-A14B
ライセンス
オープンソースとして公開されており Apache 2.0 ライセンスです。商用利用も可能です。
参考
https://github.com/Wan-Video/Wan2.2/blob/main/LICENSE.txt
配布されているモデル
Wan2.2 のオリジナルの Diffution モデルは以下です。
ComfyOrgチーム による再パッケージ版のモデルは以下で配布されています。
https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged
ローカル実行環境の用意
参考情報
ComfyUI の情報を参考にしています。
https://comfyui-wiki.com/ja/tutorial/advanced/video/wan2.2/wan2-2
https://comfyanonymous.github.io/ComfyUI_examples/wan22/
今回は Comfy Org による再パッケージ版のモデルを利用します。
PC 環境
NVIDIA GeForce RTX 5060Ti 16GBを入れて自作した PC で行います。

Stability Matrix + ComfyUI の実行環境の用意
ComfyUI は、以前 Stability Matrix で用意したものを使います。準備方法はこの過去記事をご参照ください。

必要なファイルのダウンロード
今回は、Stability Matrix のフォルダに配置するため手動で全部用意します。
(1) テキストエンコーダ、VAE、Diffusion モデル、Lora
ComfyUI による再パッケージ版を以下からダウンロードします。
テキストエンコーダ
https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/text_encoders
umt5_xxl_fp16.safetensors
umt5_xxl_fp8_e4m3fn_scaled.safetensors
→ それぞれのダウンロードボタンからダウンロード
VAE
https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/vae
wan2.2_vae.safetensors
wan_2.1_vae.safetensors
→ それぞれのダウンロードボタンからダウンロード
Diffusion モデル
https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/diffusion_models
wan2.2_i2v_high_noise_14B_fp16.safetensors
wan2.2_i2v_high_noise_14B_fp8_scaled.safetensors
wan2.2_i2v_low_noise_14B_fp16.safetensors
wan2.2_i2v_low_noise_14B_fp8_scaled.safetensors
wan2.2_t2v_high_noise_14B_fp16.safetensors
wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors
wan2.2_t2v_low_noise_14B_fp16.safetensors
wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors
wan2.2_ti2v_5B_fp16.safetensors
→ それぞれのダウンロードボタンからダウンロード (スクロールダウンすると見つかります。)
LoRA
14B T2V と 14B I2V では、LoRA も利用されているのでダウンロードしておきます。
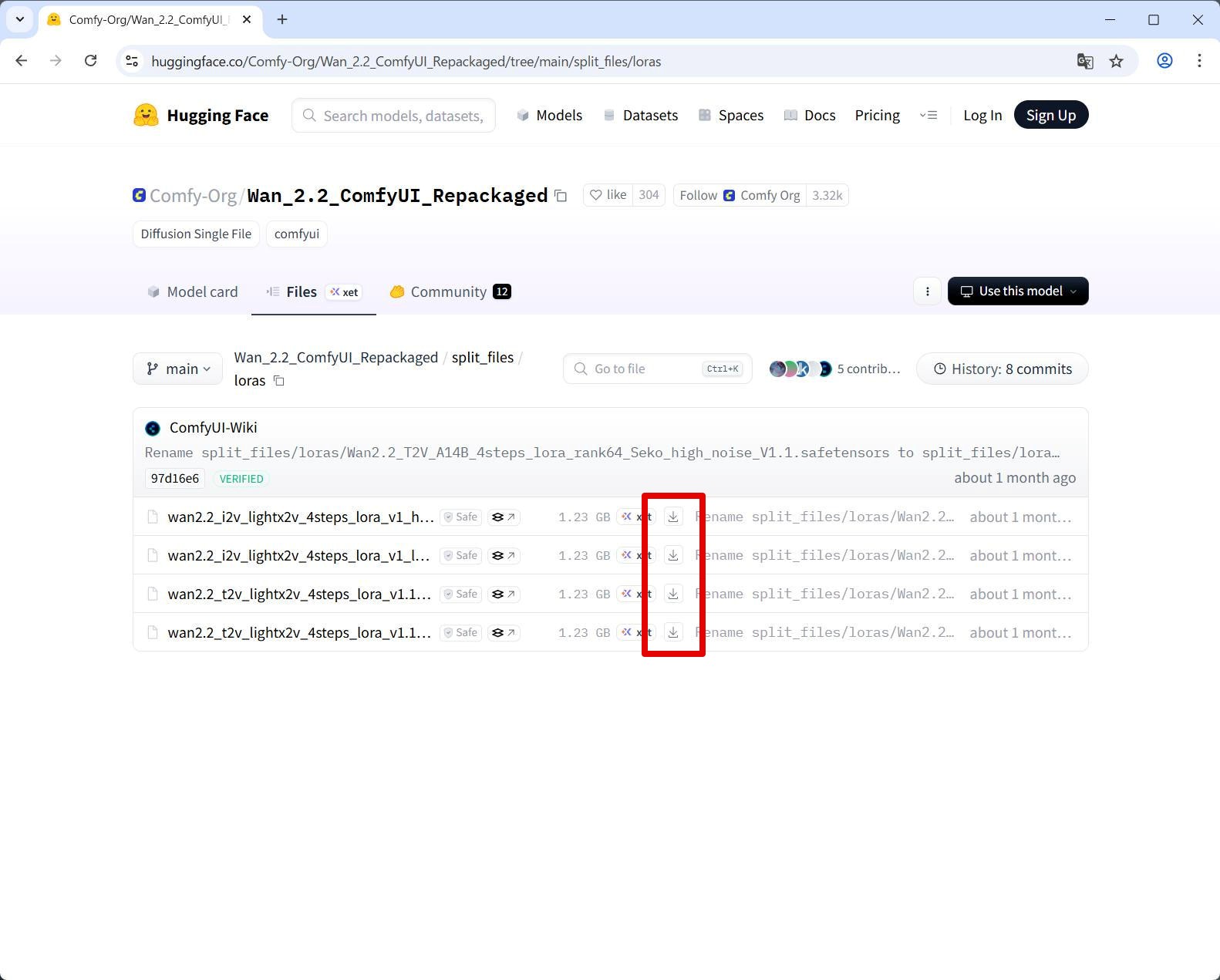
https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/loras
wan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensors
wan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors
wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors
wan2.2_t2v_lightx2v_4steps_lora_v1.1_low_noise.safetensors
→ それぞれのダウンロードボタンからダウンロード
(2) ワークフローとサンプル画像ファイル
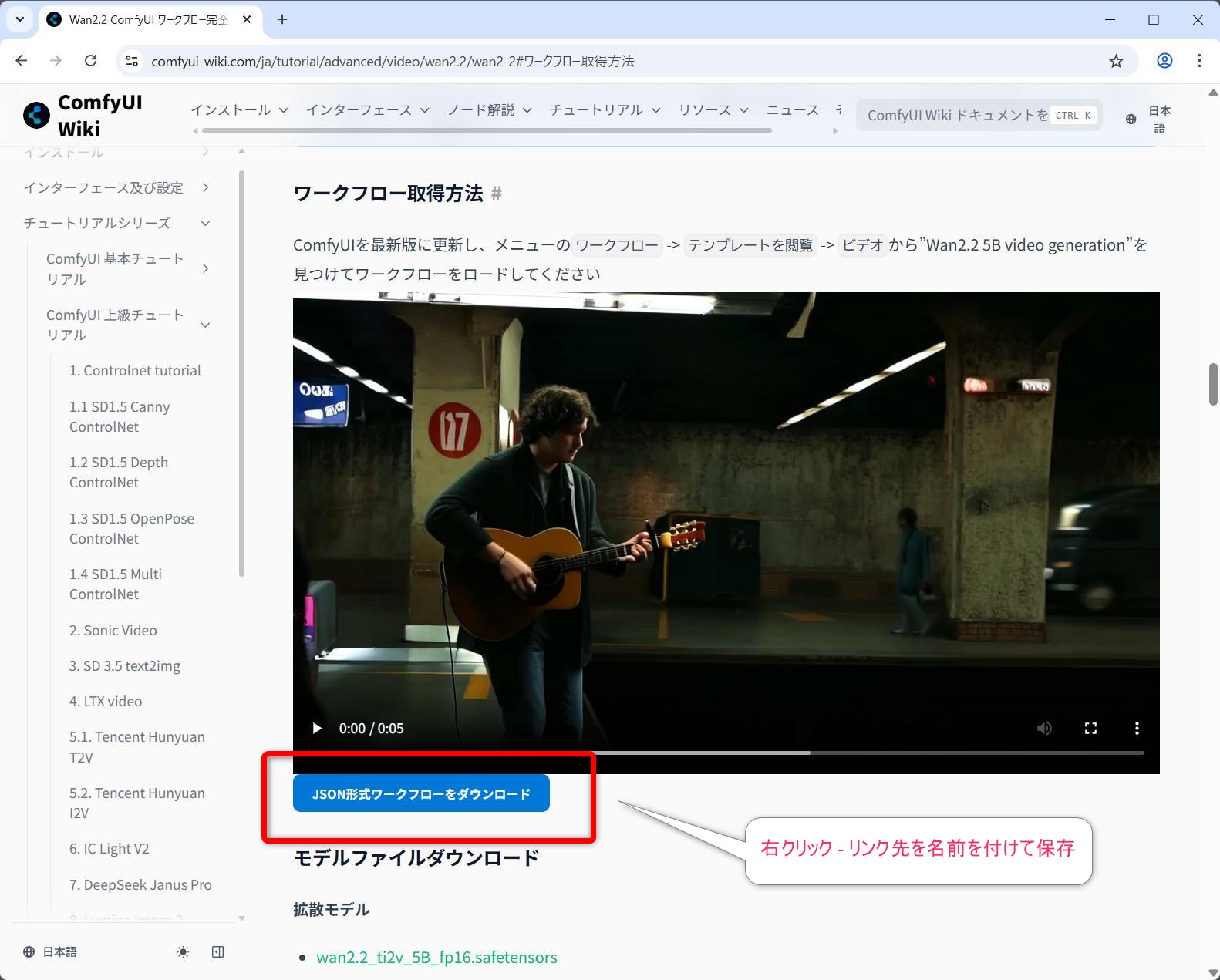
以下のページからそれぞれのワークフローと画像ファイルをダウンロードします。
https://comfyui-wiki.com/ja/tutorial/advanced/video/wan2.2/wan2-2
4 パターン実行するので、それぞれ用意します。
2-1) Wan2.2 TI2V 5B ハイブリッド版用 ワークフロー
video_wan2_2_5B_ti2v.json
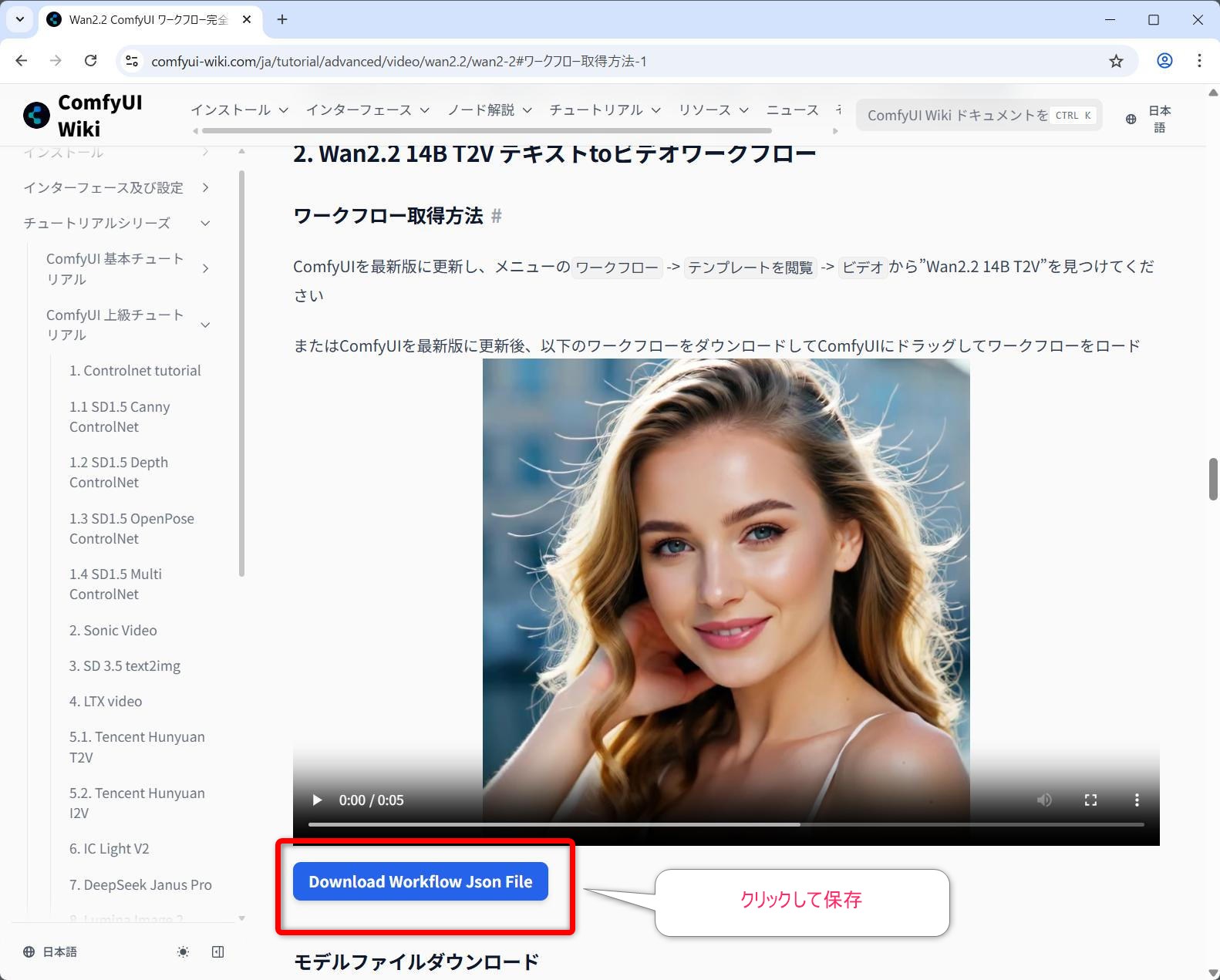
video_wan2_2_14B_t2v.json
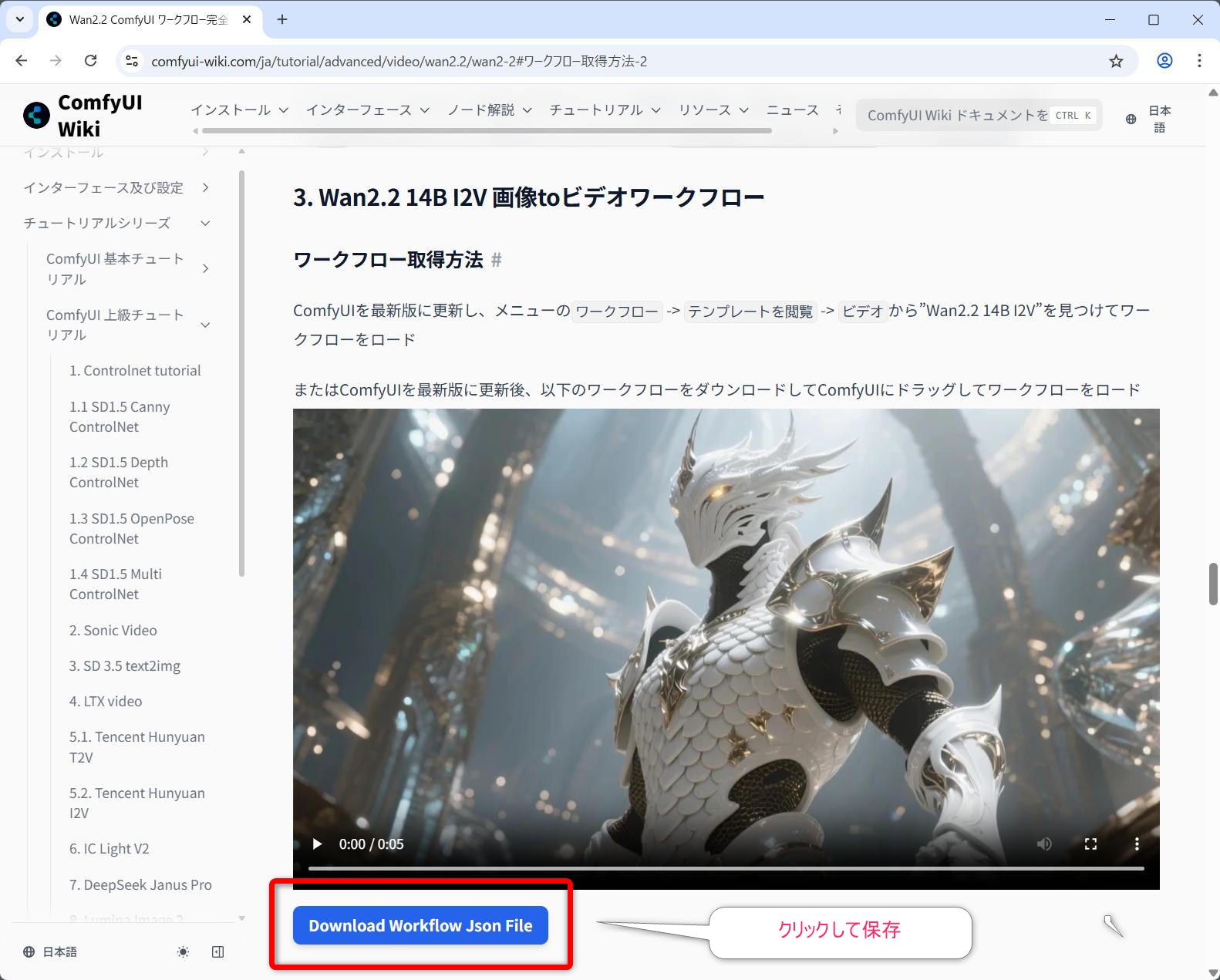
video_wan2_2_14B_i2v.json
画像もダウンロードします。
input.jpg
2-4) Wan2.2 14B FLF2V 用 ワークフロー
video_wan2_2_14B_flf2v.json
wan22_14B_flf2v_start_image.png
wan22_14B_flf2v_end_image.png
ファイルの配置
StabilityMatrix だと ComfyUI 個別の models に配置しなくてよいです。
ダウンロードしたテキストエンコーダ、VAE、Diffusion モデル、Lora のファイルは以下に配置します。
(1) テキストエンコーダ
StabilityMatrix のインストールフォルダ\Data\Models\TextEncoders
(2) VAE
StabilityMatrix のインストールフォルダ\Data\Models\TextEncoders\Data\Models\VAE
(3) Diffution モデル
StabilityMatrix のインストールフォルダ\Data\Models\TextEncoders\Data\Models\DiffusionModels
(4) LoRA
StabilityMatrix のインストールフォルダ\Data\Models\TextEncoders\Data\Models\Lora
C:\StablilityMatrix にインストールしている場合は以下のような形です。
C:\STABILITYMATRIX\DATA\MODELS
├─DiffusionModels
│ wan2.2_i2v_high_noise_14B_fp16.safetensors
│ wan2.2_i2v_high_noise_14B_fp8_scaled.safetensors
│ wan2.2_i2v_low_noise_14B_fp16.safetensors
│ wan2.2_i2v_low_noise_14B_fp8_scaled.safetensors
│ wan2.2_t2v_high_noise_14B_fp16.safetensors
│ wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors
│ wan2.2_t2v_low_noise_14B_fp16.safetensors
│ wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors
│ wan2.2_ti2v_5B_fp16.safetensors
│
├─Lora
│ wan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensors
│ wan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors
│ wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors
│ wan2.2_t2v_lightx2v_4steps_lora_v1.1_low_noise.safetensors
│
├─TextEncoders
│ umt5_xxl_fp16.safetensors
│ umt5_xxl_fp8_e4m3fn_scaled.safetensors
│
└─VAE
wan2.2_vae.safetensors
wan_2.1_vae.safetensorsワークフローや画像ファイルは実行時に指定するので、どこに置いてあっても大丈夫です。
実行
準備
(1) Stability Matrix を起動し、Stability Matrix や ComfyUI を更新します。
古いバージョンだとうまく動かない可能性があるので更新しておきます。
- Stability Matrix – Settings – アップデート
- Stability Matrix – パッケージ – ComfyUI の更新
以下では、
Stability Matrix 2.15.0
ComfyUI v0.3.59
で試しています。
(2) Stability Matrix 経由で ComfyUI を起動し、ブラウザで ComfyUI の WebUI (http://127.0.0.1:8188) を開いておきます。
Wan2.2 TI2V 5B ハイブリッド版 Text to Video (テキストから動画の生成)
まずは、軽量な統合モデルによる T2V です。
サンプルと同じものは video_wan2_2_5B_ti2v.json をドラッグアンドドロップするだけで生成できます。
- ワークフローファイル
video_wan2_2_5B_ti2v.jsonを ComfyUI の WebUI にドラッグアンドドロップします。 Load Diffusion Modelノードがwan2.2_ti2v_5B_fp16.safetensorsモデルをロードしていることを確認します。Load CLIPノードがumt5_xxl_fp8_e4m3fn_scaled.safetensorsモデルをロードしていることを確認します。Load VAEノードがwan2.2_vae.safetensorsモデルをロードしていることを確認します。実行をクリックします。
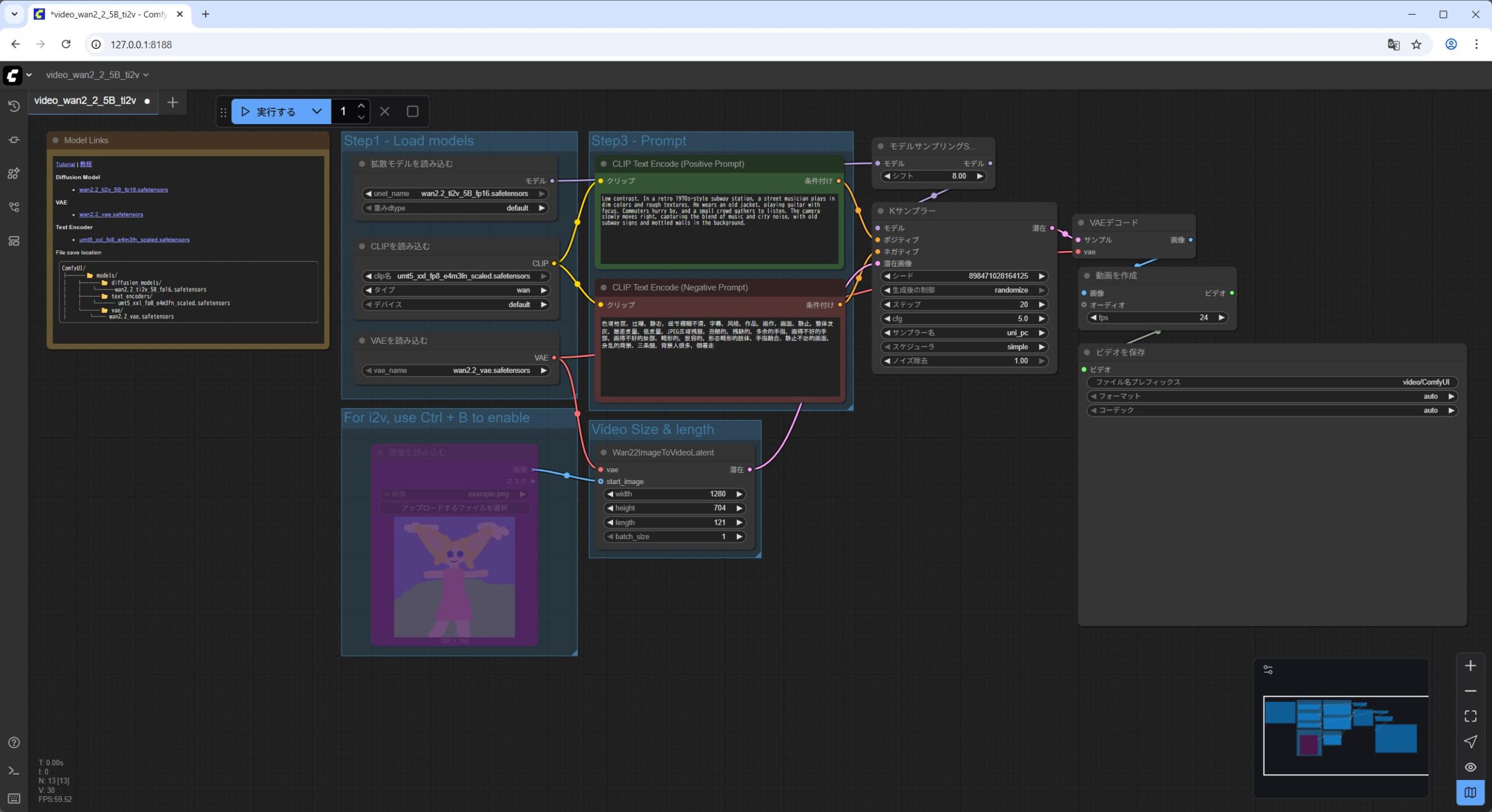
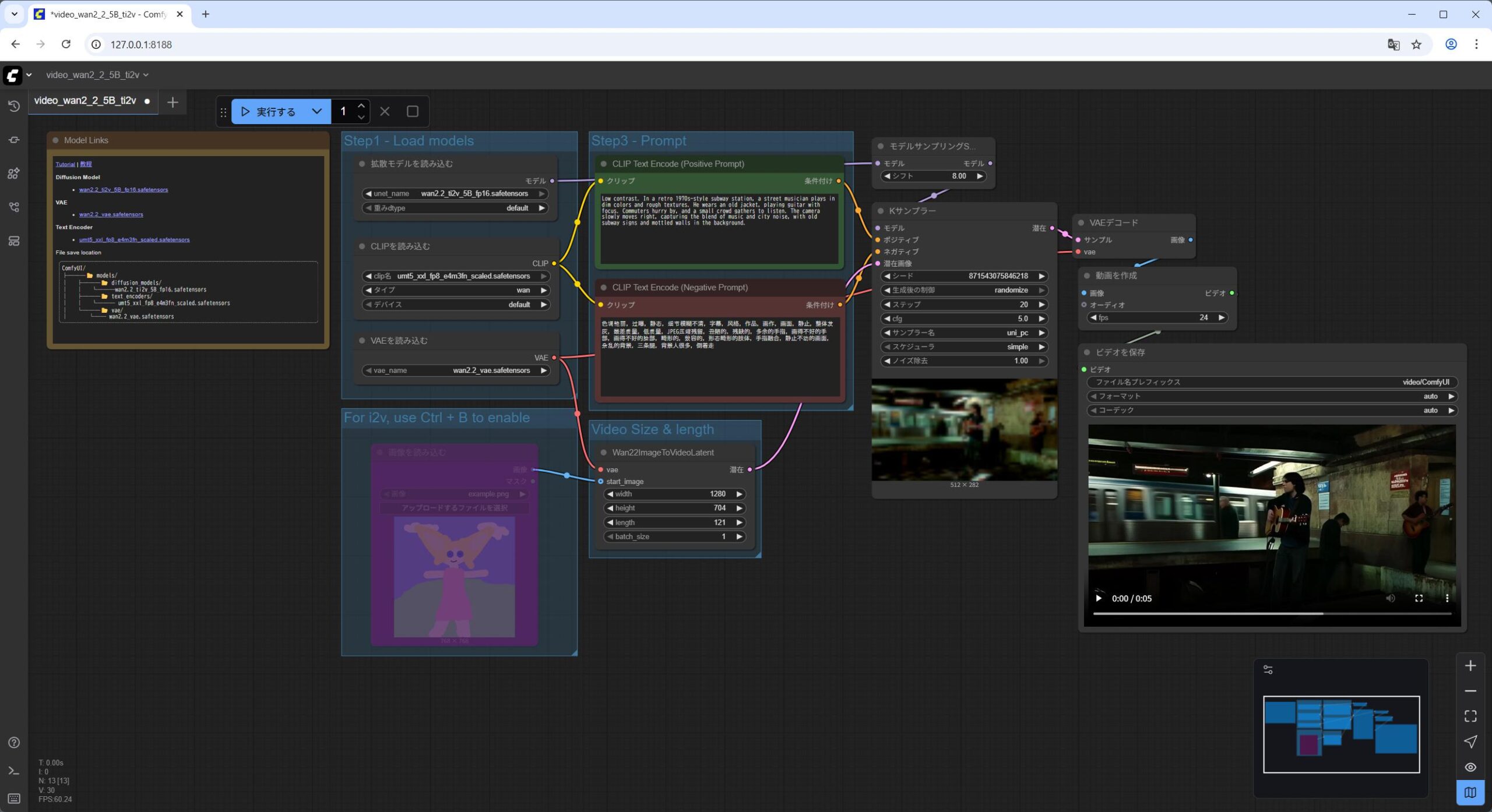
私の NVIDIA GeForce RTX 5060Ti 16GB の環境で 11分くらいかかりました。
Wan2.2 14B T2V Text to Video
次に、高品質な Text-to-Video モデルを使って動画を生成してみます。
これもサンプルと同じものは video_wan2_2_14B_t2v.json をドラッグアンドドロップするだけで生成できます。
ワークフローには、LoRA を利用しないフローもありますが、今回は LoRA を使用している部分(上半分だけ) を利用する形です。
- ワークフローファイル video_wan2_2_14B_t2v.json を ComfyUI の WebUI にドラッグアンドドロップします。
- 最初の
Load Diffusion Modelノードがwan2.2_t2v_high_noise_14B_fp8_scaled.safetensorsモデルをロードしていることを確認します。 - 2番目の
Load Diffusion Modelノードがwan2.2_t2v_low_noise_14B_fp8_scaled.safetensorsモデルをロードしていることを確認します。 Load CLIPノードがumt5_xxl_fp8_e4m3fn_scaled.safetensorsモデルをロードしていることを確認します。Load VAEノードがwan_2.1_vae.safetensorsモデルをロードしていることを確認します。- 1番目の
Lora Loader Model Onlyノードがwan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensorsモデルをロードしていることを確認します。 - 2番目の
Lora Loader Model Onlywan2.2_t2v_lightx2v_4steps_lora_v1.1_low_noise.safetensorsモデルをロードしていることを確認します。 実行をクリックします。
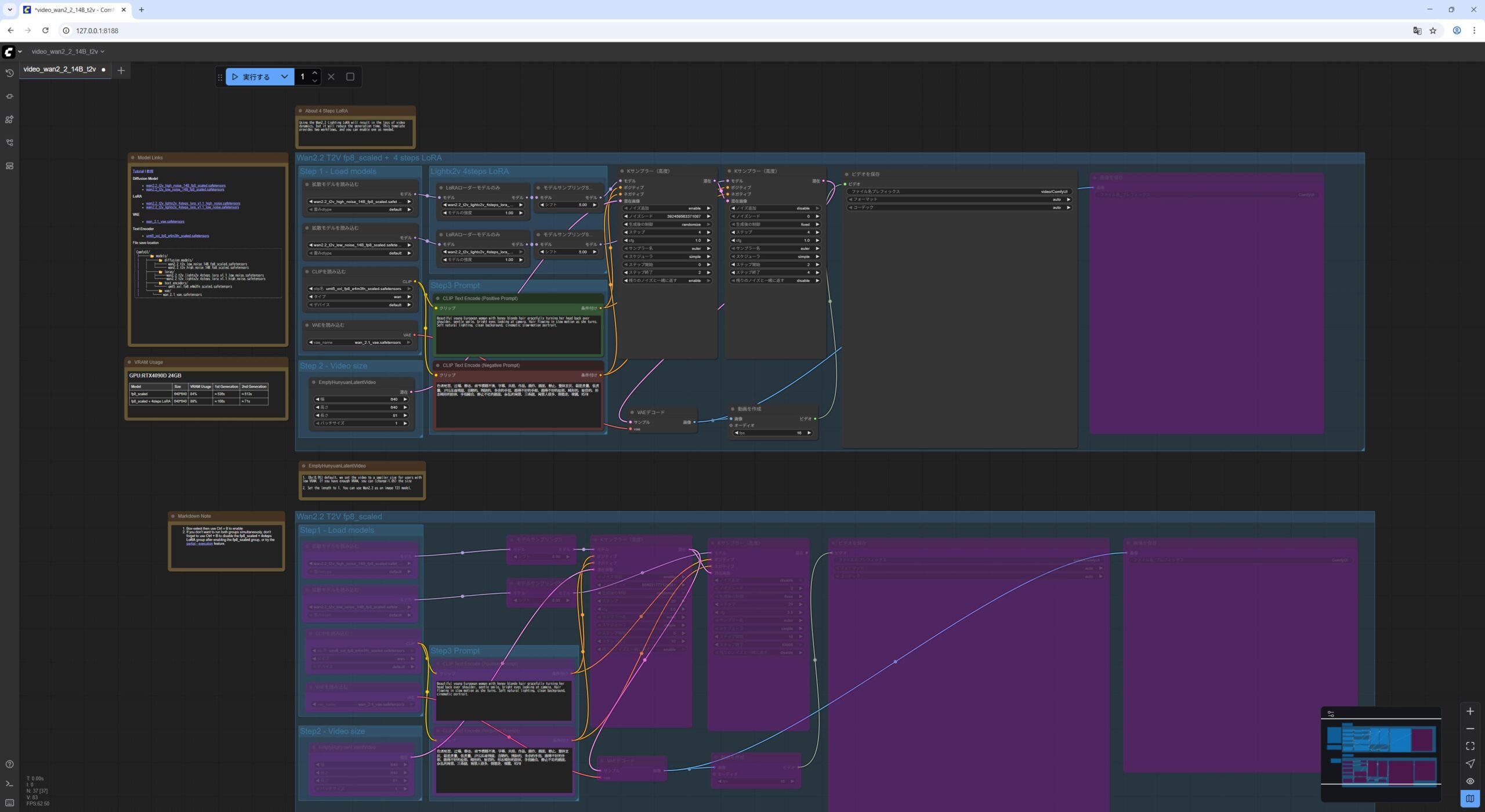
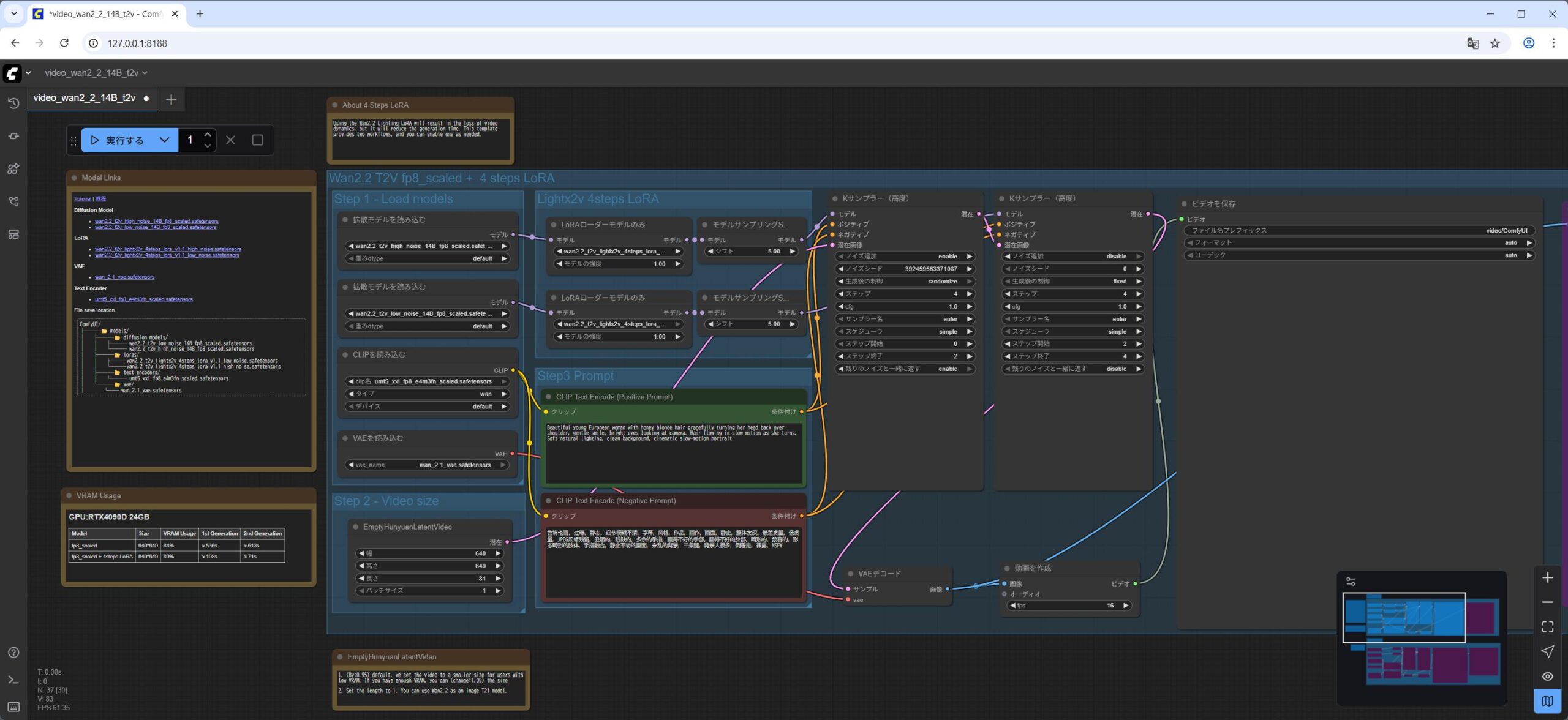
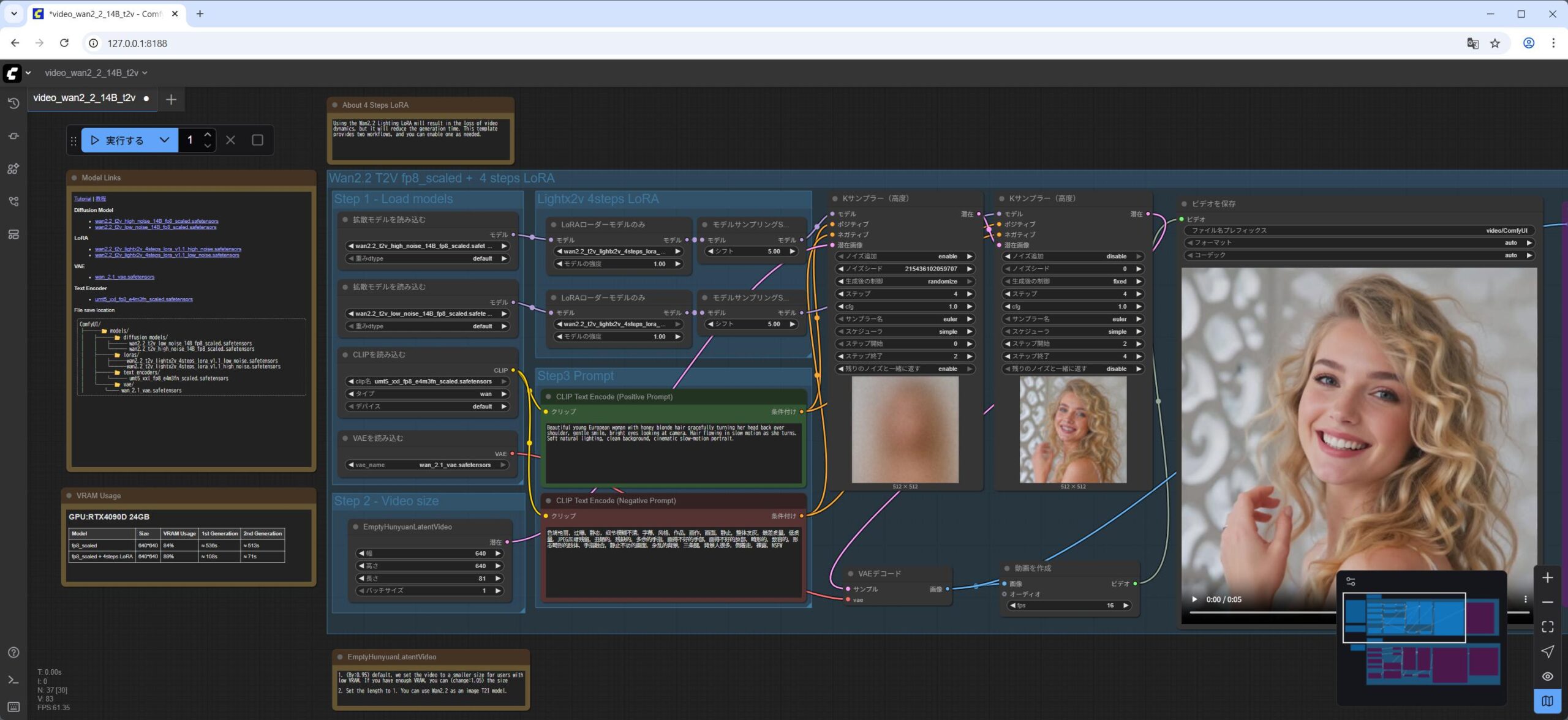
私の NVIDIA GeForce RTX 5060Ti 16GB の環境で 4分くらいかかりました。
Wan2.2 14B I2V Image to Video
次に、高品質な Image-to-Video モデル で、画像をもとに動画を生成してみます。
サンプルのワークロードファイルをドラッグアンドドロップした後、ダウンロードしておいた入力用の画像も指定する形です。
これも ワークフローには、LoRA を利用しないフローもありますが、今回は LoRA を使用している部分(上半分だけ) を利用する形です。
video_wan2_2_14B_i2v.jsonを ComfyUI の WebUI にドラッグアンドドロップします。- 最初の
Load Diffusion Modelノードがwan2.2_i2v_high_noise_14B_fp8_scaled.safetensorsモデルをロードしていることを確認します。 - 2番目の
Load Diffusion Modelノードがwan2.2_i2v_low_noise_14B_fp8_scaled.safetensorsモデルをロードしていることを確認します。 Load CLIPノードがumt5_xxl_fp8_e4m3fn_scaled.safetensorsモデルをロードしていることを確認します。Load VAEノードがwan_2.1_vae.safetensorsモデルをロードしていることを確認します。- 1番目の
Lora Loader Model Onlyノードがwan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensorsモデルをロードしていることを確認します。 - 1番目の
Lora Loader Model Onlyノードがwan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensorsモデルをロードしていることを確認します。 Load Imageノードに、ダウンロードしていた画像input.jpgをドラッグアンドドロップします実行をクリックします。
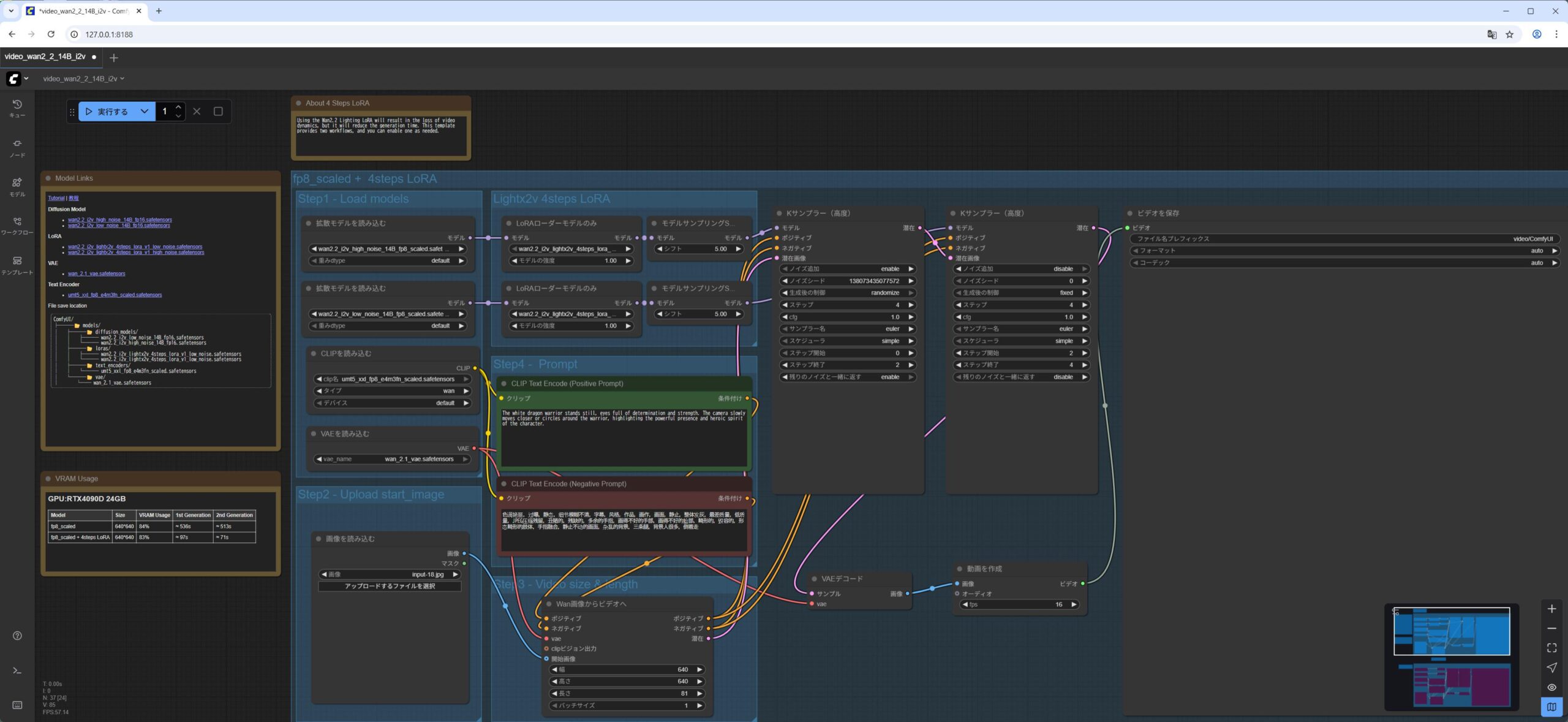
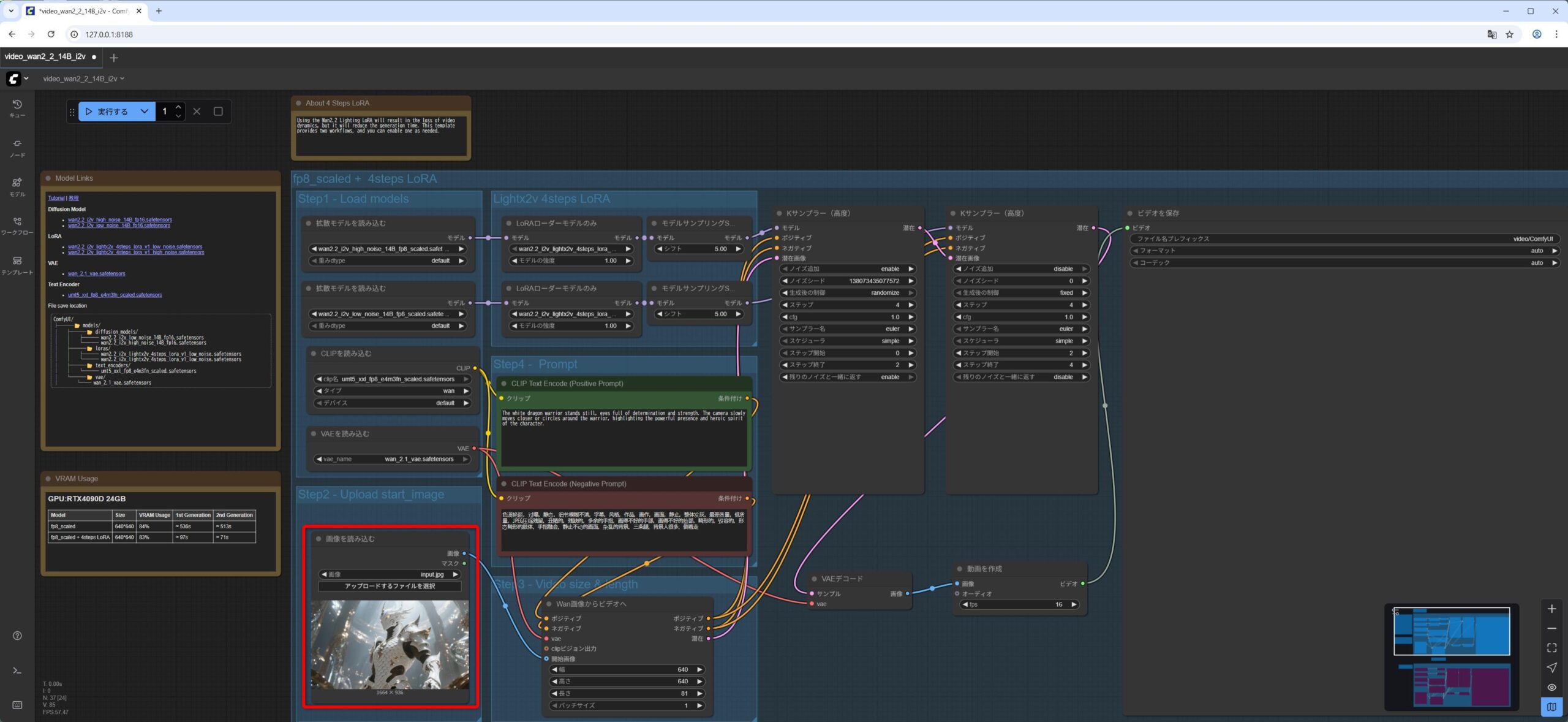
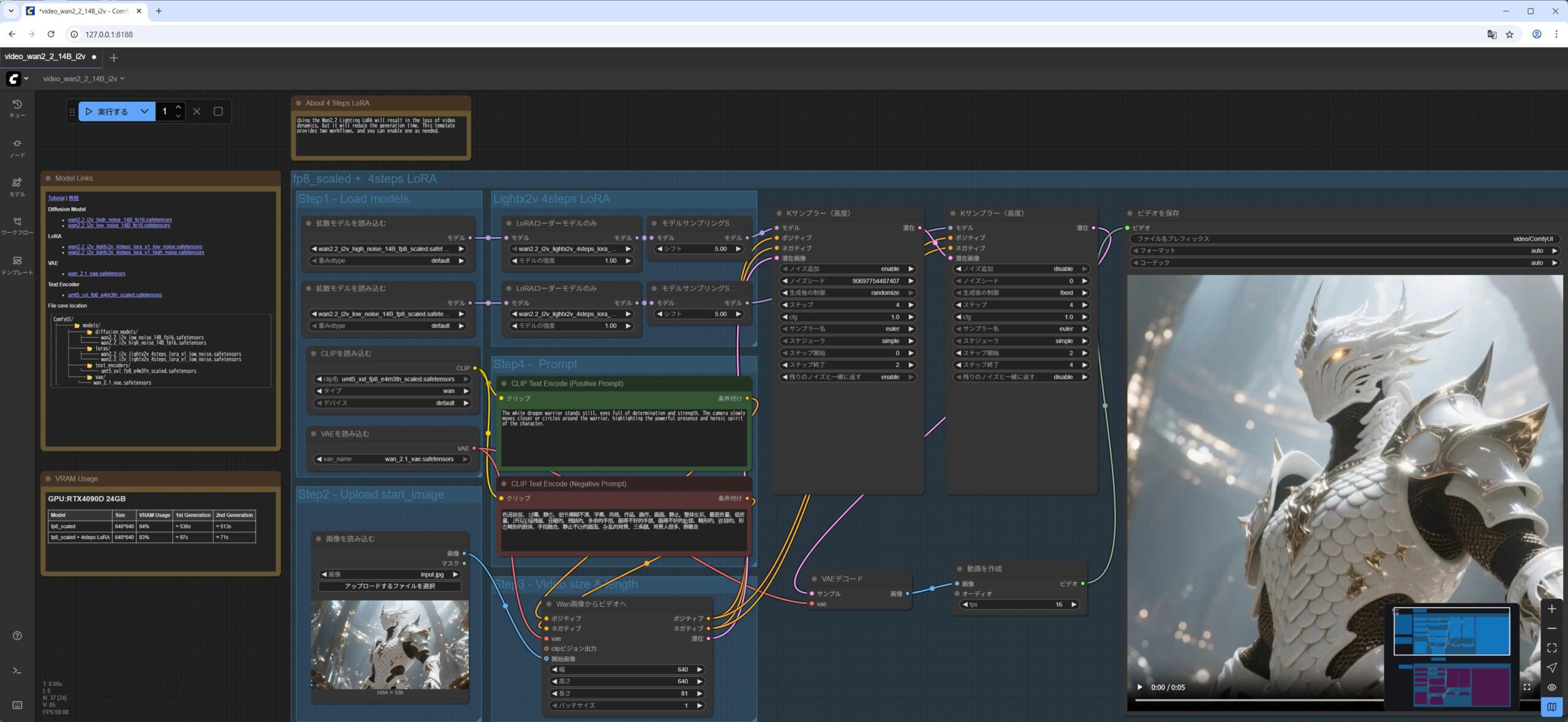
私の NVIDIA GeForce RTX 5060Ti 16GB の環境で 4分くらいかかりました。
Wan2.2 14B FLF2V First Last Frame to Video
最後に、開始画像と終了画像を指定して、間をつなぐ動画の生成です。
サンプルのワークロードファイルをドラッグアンドドロップした後、ダウンロードしておいた開始画像と終了画像を指定します。
これも LoRA を使用している部分(上半分だけ) を利用する形しています。
- 最初の
Load Imageノードに、開始画像wan22_14B_flf2v_start_image.pngをドラッグアンドドロップします。 - 2番目の
Load Imageノードに、開始画像wan22_14B_flf2v_end_image.pngをドラッグアンドドロップします。 - 最初の
Load Diffusion Modelノードがwan2.2_i2v_high_noise_14B_fp8_scaled.safetensorsモデルをロードしていることを確認します。 - 2番目の
Load Diffusion Modelノードがwan2.2_i2v_low_noise_14B_fp8_scaled.safetensorsモデルをロードしていることを確認します。 Load CLIPノードがumt5_xxl_fp8_e4m3fn_scaled.safetensorsモデルをロードしていることを確認します。Load VAEノードがwan_2.1_vae.safetensorsモデルをロードしていることを確認します。- 1番目の
Lora Loader Model Onlyノードがwan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensorsモデルをロードしていることを確認します。 - 1番目の
Lora Loader Model Onlyノードがwan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensorsモデルをロードしていることを確認します。 実行をクリックします。
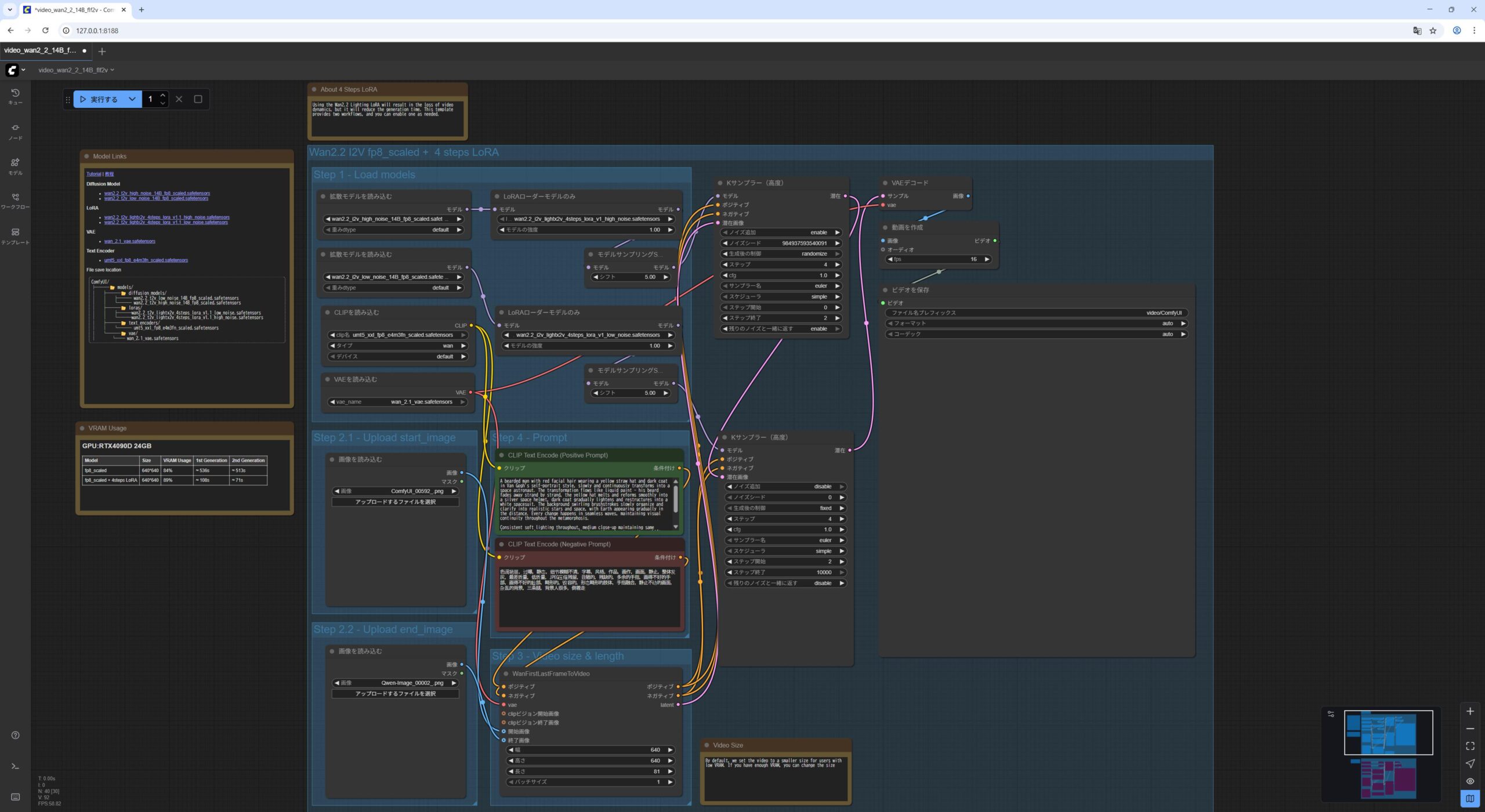
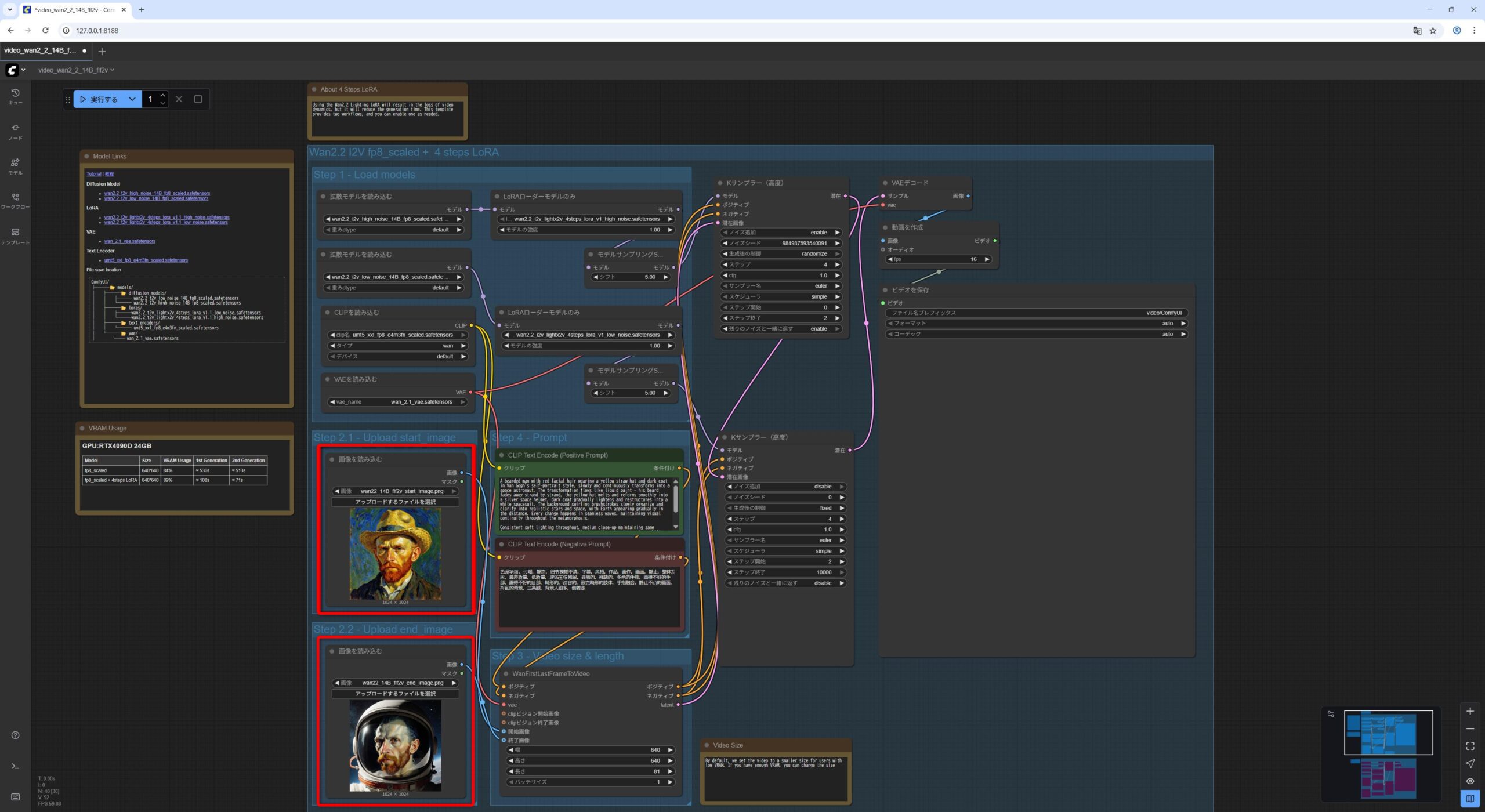
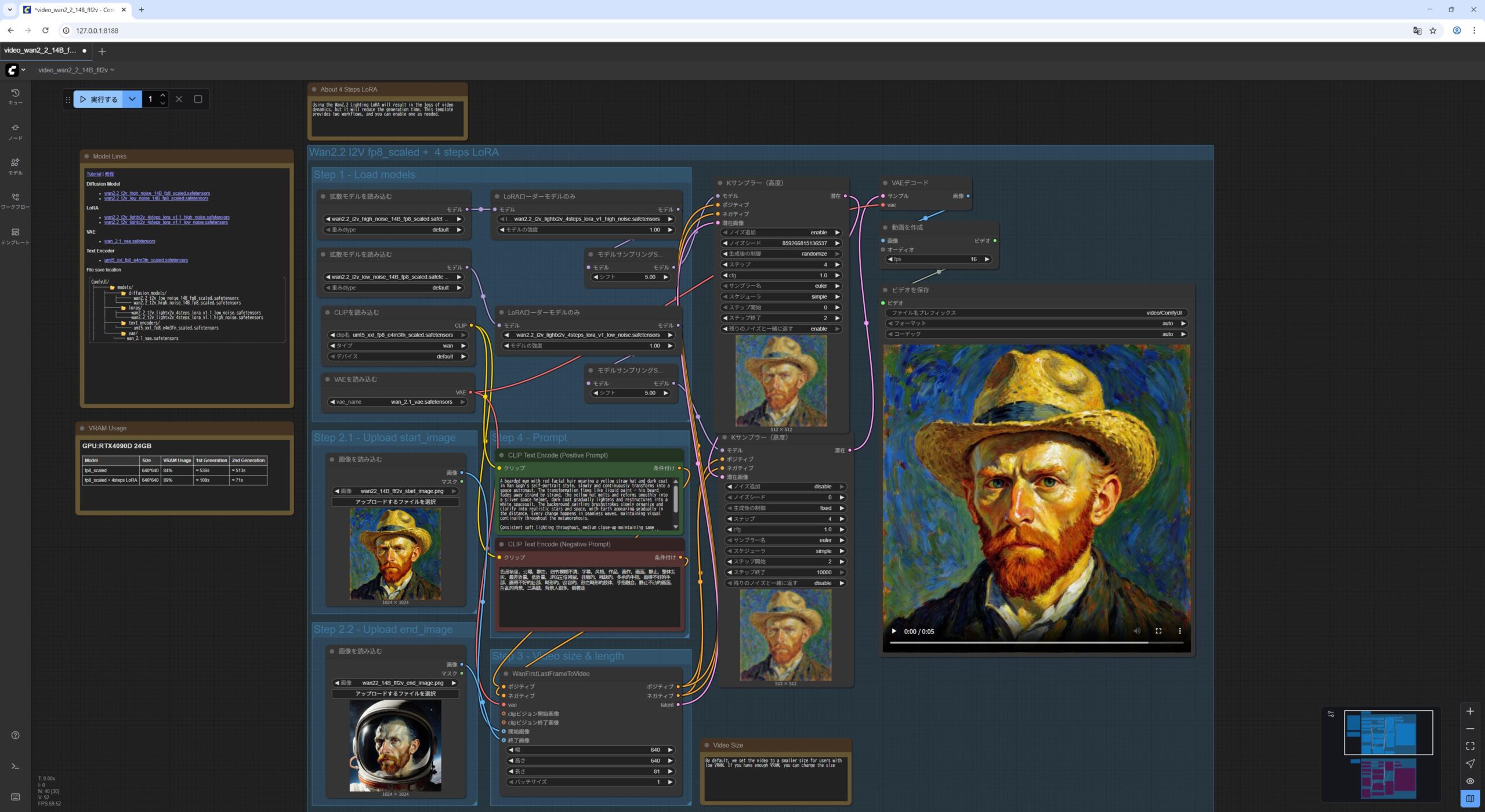
私の NVIDIA GeForce RTX 5060Ti 16GB の環境で 3分半くらいかかりました。
まとめ、おまけ
プロンプトやサイズ、利用する画像を変更することでいろいろできそうです。
生成される動画の質もよく、ミドルレンジのグラフィックカード NVIDIA GeForce RTX 5060Ti 16GB でもそこまで時間がかからず生成できました。
FLF2V で、複数動画を作成して、動画編集ソフトでつなげると以下のような感じになりました。
プロンプトを変更してなかったので、変な遷移もありますがこれはこれで面白いです。
少し前に流行った 人魚エフェクト・人魚への変身動画も、プロンプトを工夫すれば手元で作れるかもしれません。
参考となれば幸いです。