
概要
音声認識AI の OpenAI Whisper をWindows の ローカル PC を動かしてみましたので情報残しておきます。
OpenAI Whisper とは
OpenAI Whisper は、OpenAI 社によって開発された 自動音声認識(ASR: Automatic Speech Recognition)モデルです。音声ファイルを入力すると、音声の内容を高精度でテキストに変換してくれます。
公式サイト
https://openai.com/ja-JP/index/whisper/
https://github.com/openai/whisper
用意するもの
PC 環境
NVIDIA GeForce RTX 5060Ti 16GBを入れて自作した PC で行います。

Whisper は CPU でも動作しますが、CUIDA 対応の GPU があると処理速度が非常に向上します。
github のは以下のように記載されています。
Available models and languages
There are six model sizes, four with English-only versions, offering speed and accuracy tradeoffs. Below are the names of the available models and their approximate memory requirements and inference speed relative to the large model. The relative speeds below are measured by transcribing English speech on a A100, and the real-world speed may vary significantly depending on many factors including the language, the speaking speed, and the available hardware.
Size Parameters English-only model Multilingual model Required VRAM Relative speed tiny 39 M tiny.entiny~1 GB ~10x base 74 M base.enbase~1 GB ~7x small 244 M small.ensmall~2 GB ~4x medium 769 M medium.enmedium~5 GB ~2x large 1550 M N/A large~10 GB 1x turbo 809 M N/A turbo~6 GB ~8x The
https://github.com/openai/whisper?tab=readme-ov-file#available-models-and-languages.enmodels for English-only applications tend to perform better, especially for thetiny.enandbase.enmodels. We observed that the difference becomes less significant for thesmall.enandmedium.enmodels. Additionally, theturbomodel is an optimized version oflarge-v3that offers faster transcription speed with a minimal degradation in accuracy.
機械翻訳
Whisper には 6 種類のモデルサイズがあり、そのうち 4 種類には 英語専用モデル(.en) も用意されています。モデルの選択は、速度と精度のトレードオフになります。
以下の表は、各モデルの名前・パラメータ数・必要なVRAM・相対的な推論速度を示しています。相対速度は、A100 GPU を使って英語音声を文字起こしした際の目安です。実際の速度は言語や話速、ハードウェア環境により大きく変動します。
(表は省略)
.en 付きモデル(例:tiny.en)は 英語専用に最適化されており、tiny や base サイズでは精度が向上します。
small.en や medium.en になると、英語専用モデルと多言語モデルの精度差は ほとんどなくなります。
turbo モデルは large-v3 を最適化したもので、精度をほぼ落とさず、速度が大幅に向上しています。
ソフトウェア
用意したソフトウェア環境は以下です。
- OS : Windows 11
- Python 3.10.11
- Windows 用の git.exe
- Windows 用の ffmpeg.exe
インストール
Python
ここでは Python 3.10 を利用しました。
(1) 公式サイトから、Windows 用 Python 3.10.11 のインストーラをダウンロードします。
https://www.python.org/downloads/windows
(2) ダウンロードした python-3.10.11-amd64.exe を実行してインストールします。
この環境は、既に別のバージョンがすべてのユーザ向けにインストールされているので、Customized から同じようにインストールしました。
Install Now で個別ユーザでインストールする形でも問題ないです。
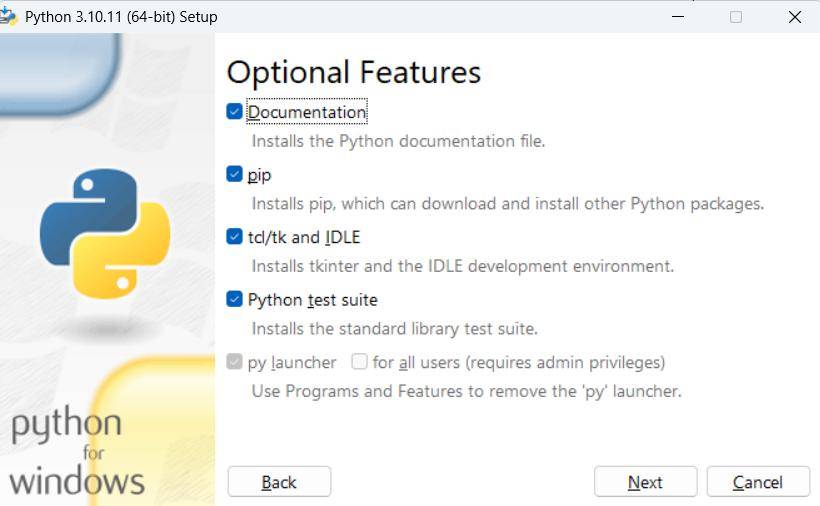
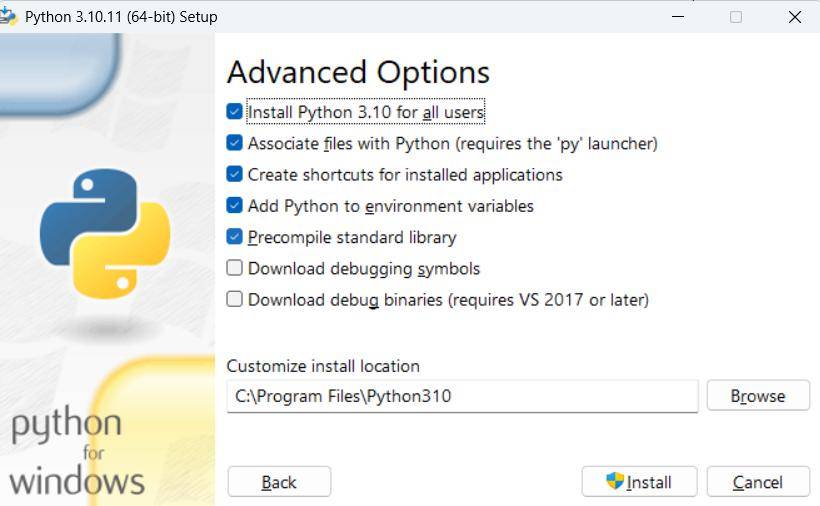
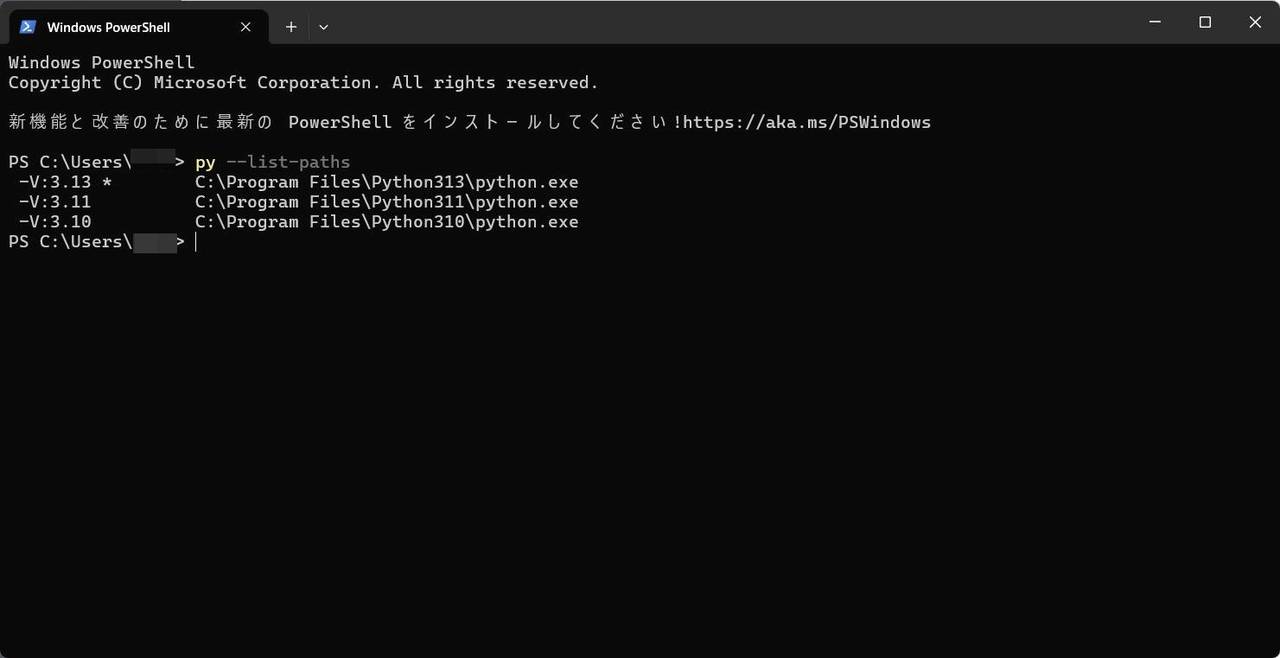
完了後に、ターミナルを開いて py –list-paths を実行した際に 3.10 が見えれば OK です。
Git
インストール時、内部的に git clone が行われるので、Windows 上で動作する git を用意します。
インストーラ版でフルでインストールしてもよいのですが、今回は git clone にしか使わないので Portable 版で行っています。インストーラ版でも問題ないです。
(1) ダウンロード
Git の公式サイトにアクセスします。
https://git-scm.com/
参考までに、Windows 用の Git に特化したプロジェクトの公式サイト(https://gitforwindows.org/) もありますが、いずれも最終的に git-for-windows の github にリンクしているのでダウンロードできるものは同じです。
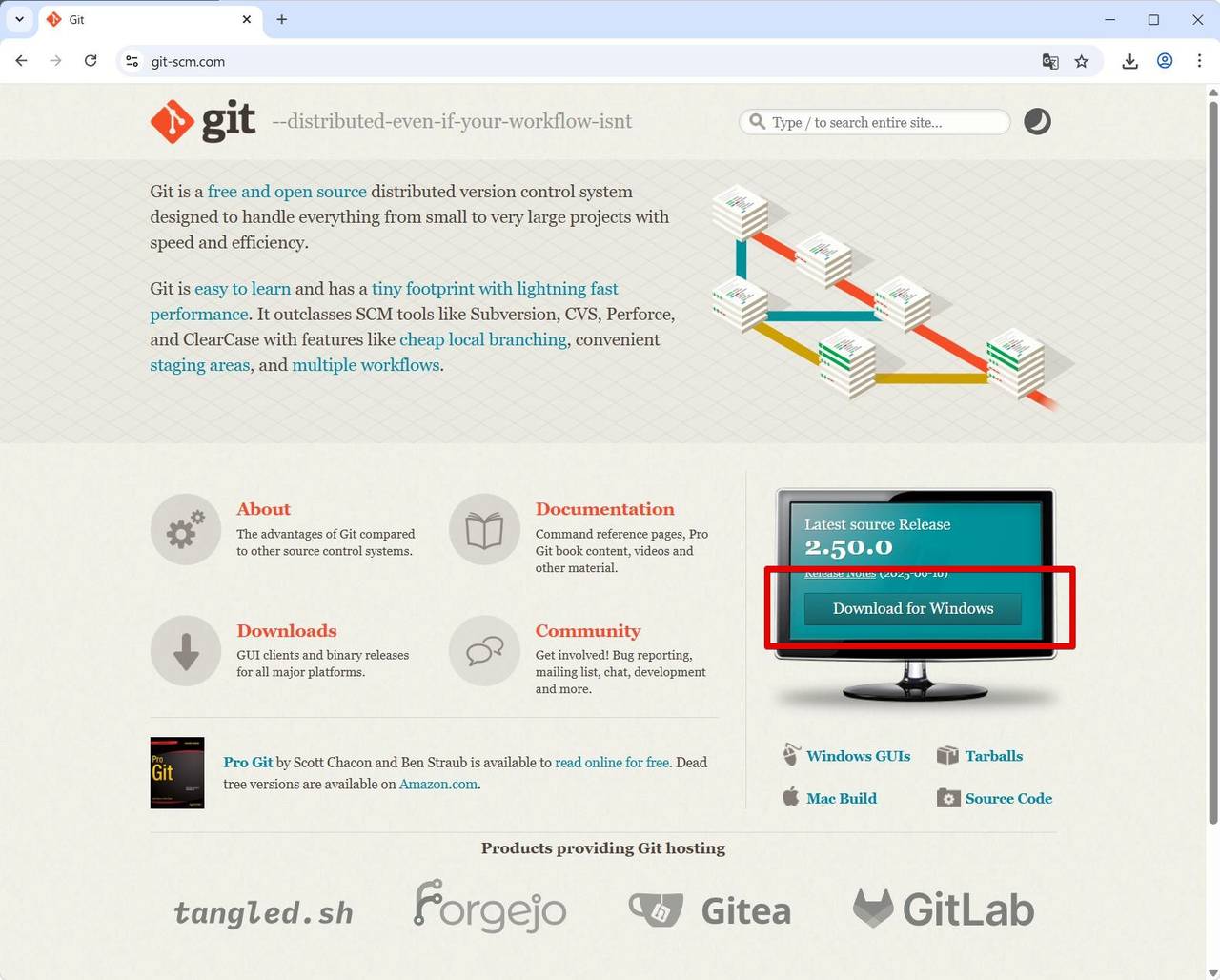
右側 中ほどの [Download for Windows] をクリックします。
(2) ファイルの配置とパスの設定
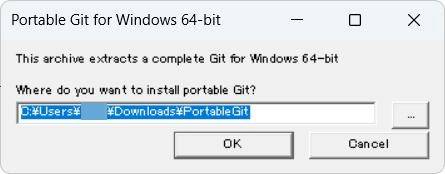
ダウンロードした PortableGit-x.xx.x-64-bit.7z.exe を実行し適当なフォルダに解凍します。
ここでは、一旦、[ダウンロード] フォルダに解凍し、その後 C:\Program File に移動しました。
そして git.exe のあるフォルダに対してパスを設定しています。
FFmpeg
音声変換や前処理に必要な FFmpeg を用意します。
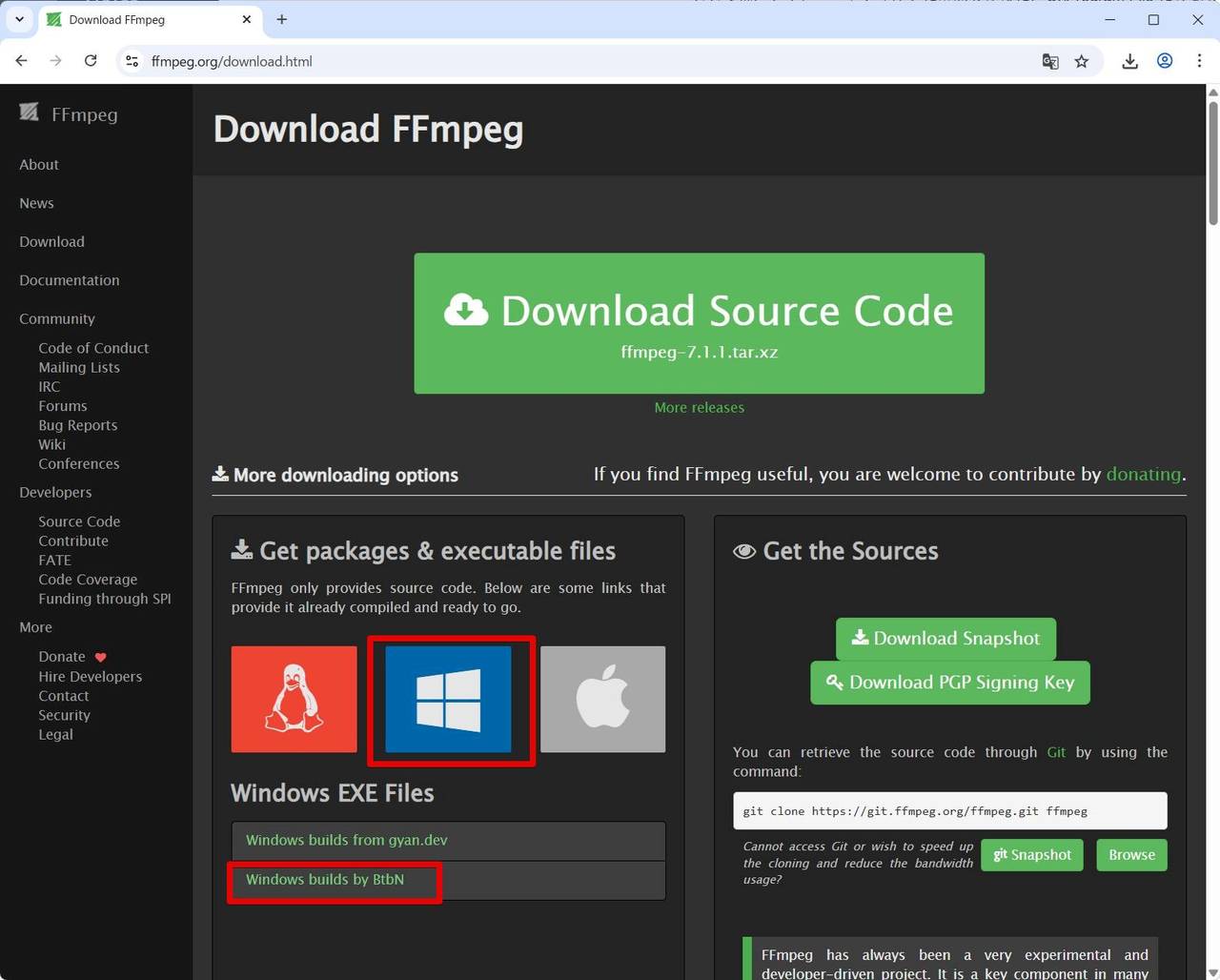
(1) ダウンロード
公式サイトたどってから Windows 用バイナリをダウンロードします。
https://ffmpeg.org/download.html
公式サイトでは直接 Windows 用のバイナリを配布していないので、リンクしているサイトからダウンロードする形となります。ここでは Windows builds by BtbN からダウンロードしました。
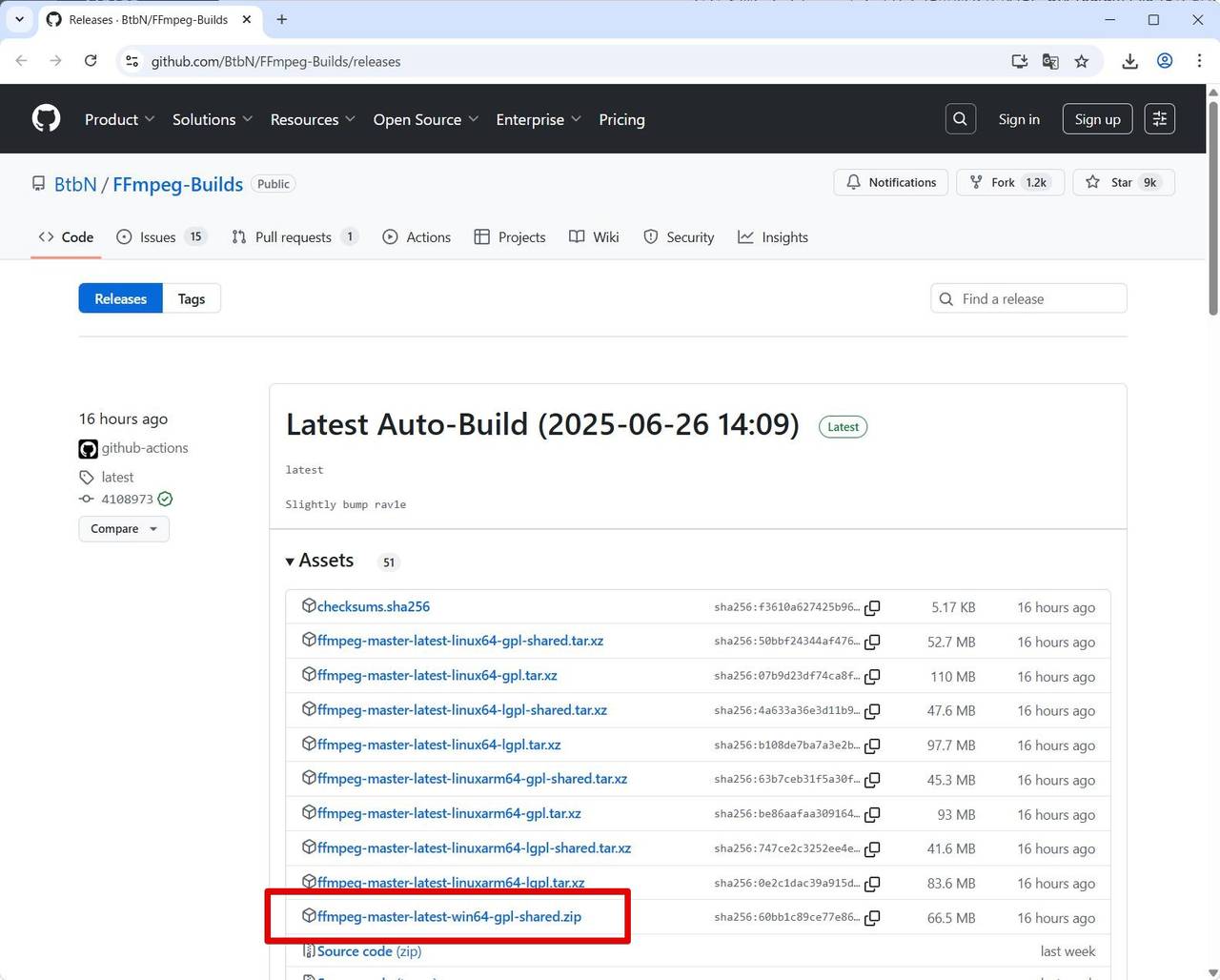
(2) ファイルの配置とパスの設定
ダウンロードした ffmpeg-master-latest-win64-gpl-shared.zip を解凍し、適当な場所に配置した後、ffmpeg.exe のあるフォルダに対してパスを設定します。
ここでは、C:\Program Files\ffmpeg として配置しパスを設定しています。
PowerShell の設定
Windows 11 だと PowerShell の実行ポリシーのデフォルトが Restricted のため、ダウンロードしたスクリプトが実行できません。Python の venv を activate するためのスクリプトが実行できるように変更しておきます。
管理者権限で PowerShell を起動し、以下実行します。
Set-ExecutionPolicy RemoteSigned出力例
Windows PowerShell
Copyright (C) Microsoft Corporation. All rights reserved.
新機能と改善のために最新の PowerShell をインストールしてください!https://aka.ms/PSWindows
PS C:\WINDOWS\system32> Get-ExecutionPolicy
Restricted
PS C:\WINDOWS\system32> Set-ExecutionPolicy RemoteSigned
実行ポリシーの変更
実行ポリシーは、信頼されていないスクリプトからの保護に役立ちます。実行ポリシーを変更すると、about_Execution_Policies
のヘルプ トピック (https://go.microsoft.com/fwlink/?LinkID=135170)
で説明されているセキュリティ上の危険にさらされる可能性があります。実行ポリシーを変更しますか?
[Y] はい(Y) [A] すべて続行(A) [N] いいえ(N) [L] すべて無視(L) [S] 中断(S) [?] ヘルプ (既定値は "N"): y
PS C:\WINDOWS\system32> Get-ExecutionPolicy
RemoteSigned
PS C:\WINDOWS\system32>
Whisper
必要なソフトウェアの準備ができたら、Whisper をインストールします。
(1) Whisper をインストールするフォルダを作成し、Python の仮想環境を作成します。
ここでは、C:\Whisper にインストールすることにします。
ターミナルを開いて、以下を実行します。Python 3.10 を利用するので py -3.10 でバージョンを指定しています。
cd C:\Whisper\
py -3.10 -m venv venv
.\venv\Scripts\activate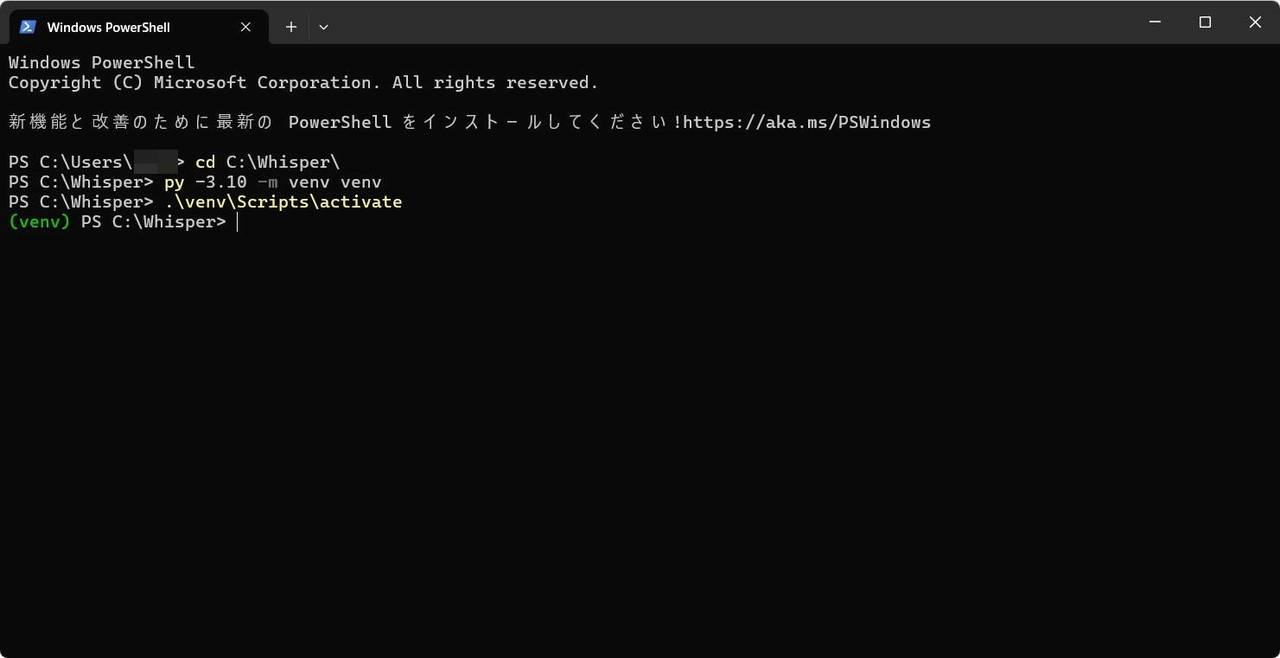
venv が activate されていると、プロンプトに (venv) がつきます。
(2) Whisper のインストール
venv が activate されている状態で以下を実行します。
pip install git+https://github.com/openai/whisper.git
(3) GPU 用の PyTorch のインストール
Whisper と一緒にインストールされる Pytorch は CPU 向けのものなので、一度削除して CUDA 対応のものをインストールします。
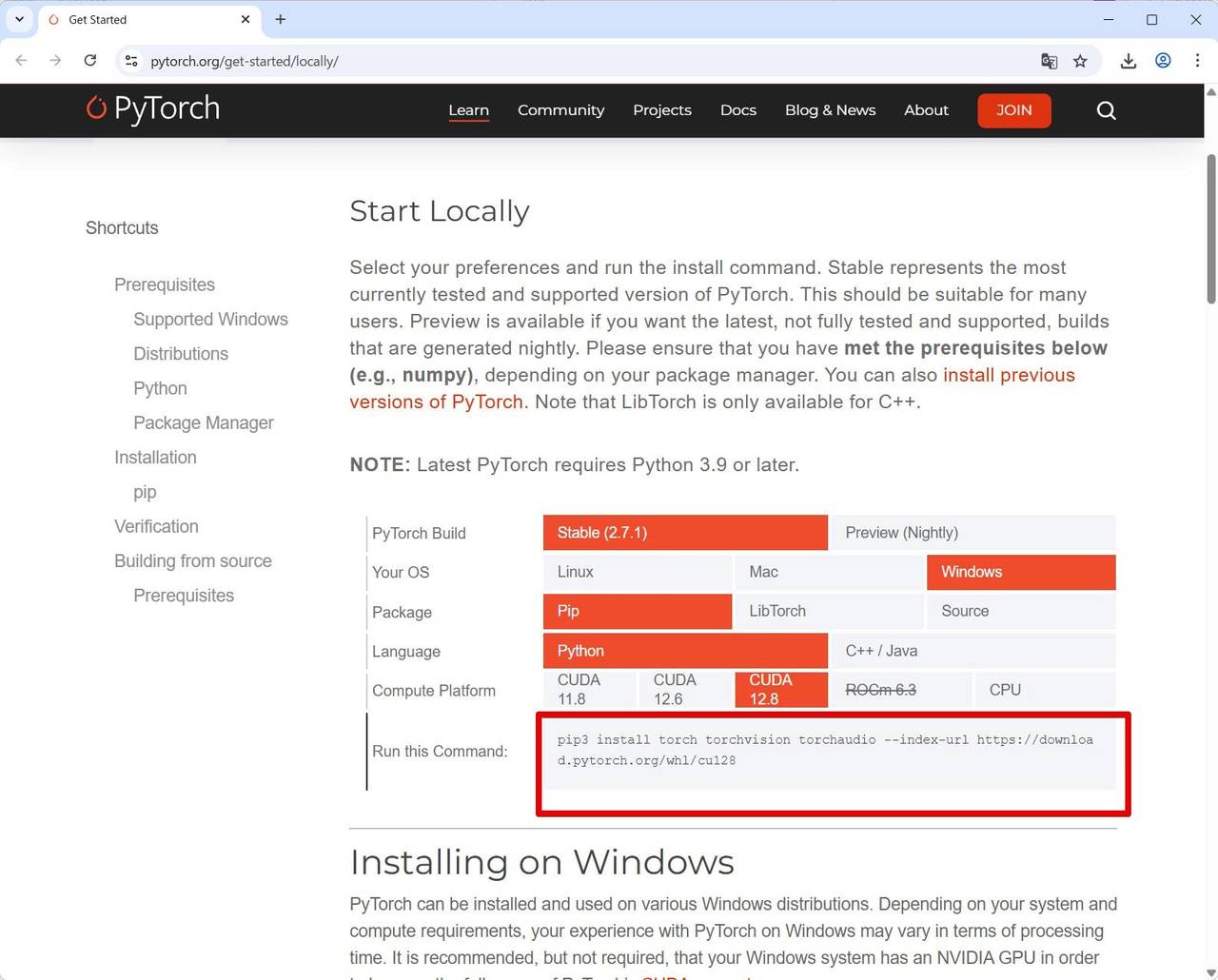
インストールのためのコマンドは PyTorch公式サイトから確認できます。
(Stable – Windows – Pip – Python – CUDA 12.8 を選択後、[Run this Command:] の内容から確認)
pip uninstall torch
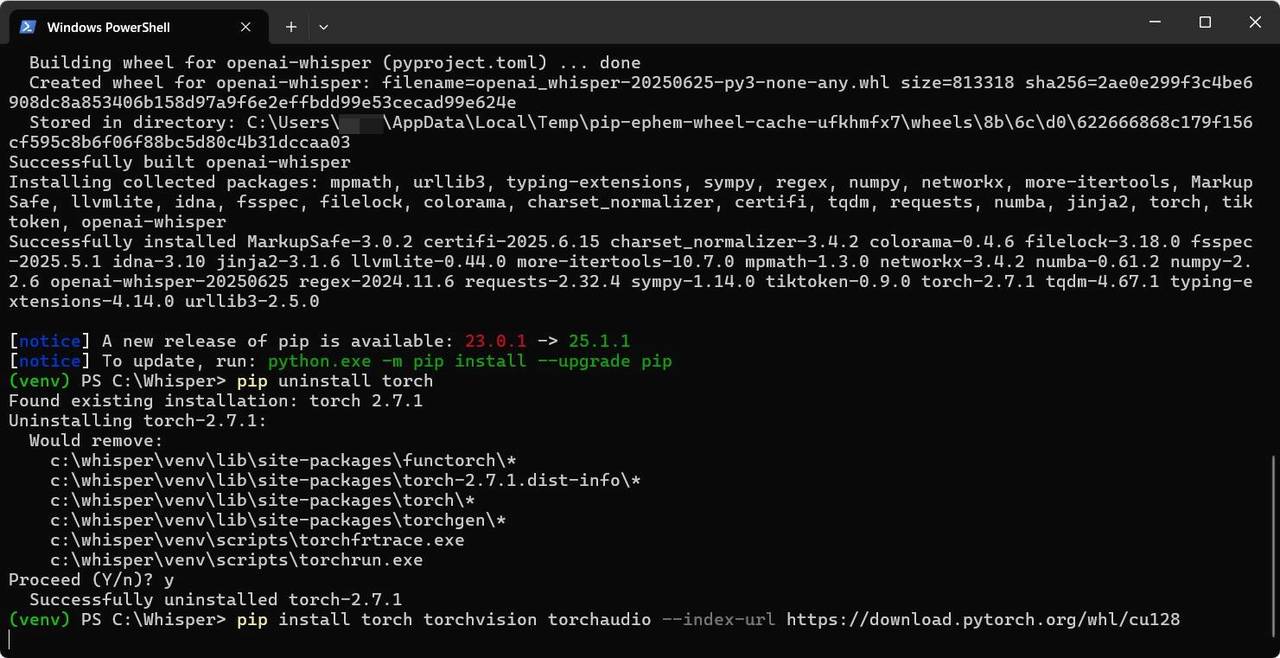
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128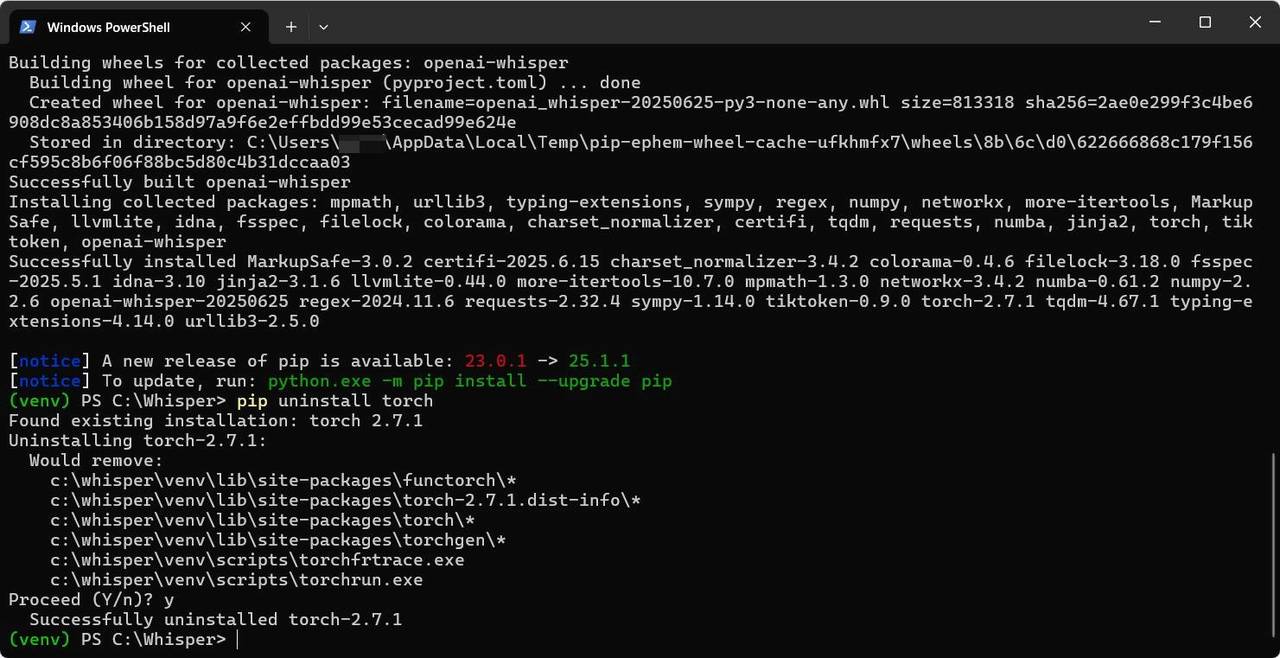
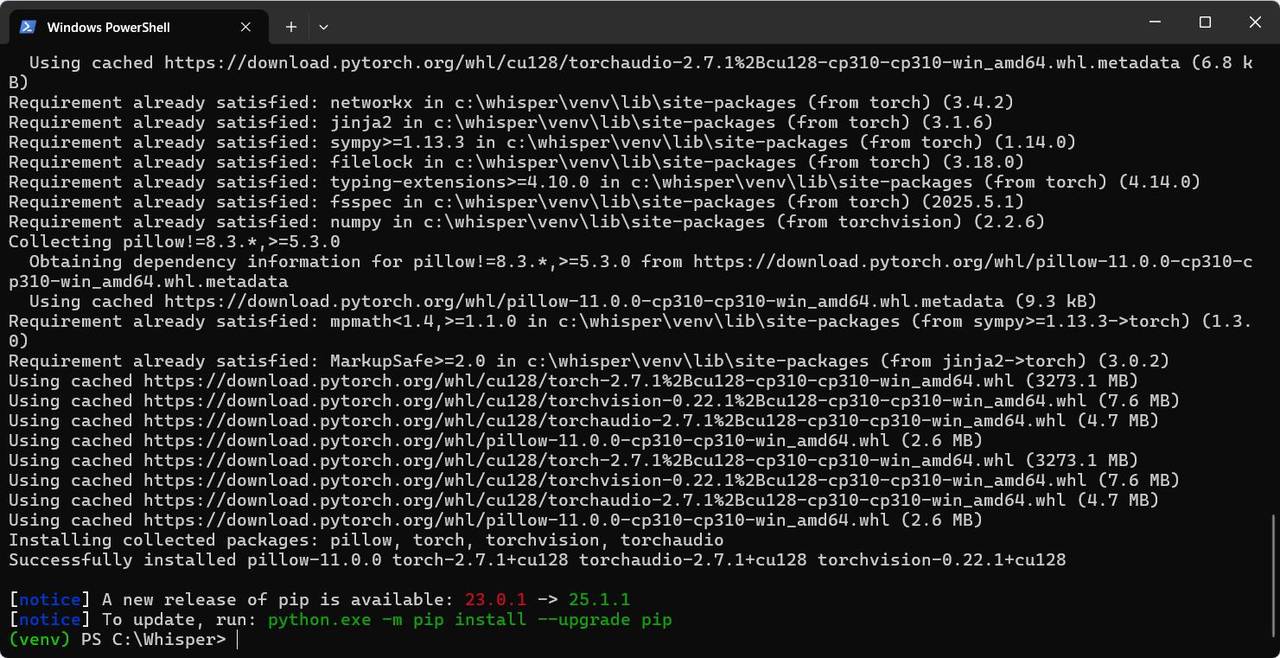
これでインストール完了です。
Wisper 2回目以降の起動
一度インストールを行った後は、venv を activate すれば、再度同様に利用できます。
cd C:\Whisper\
py -3.10 -m venv venv
.\venv\Scripts\activate自動文字起こしの実行
日本語音声ファイル example-ja.wav から文字起こしを行う場合、以下を実行します。
whisper example-ja.wav --language Japanese --model largemodel の部分は、利用したいモデルを指定します。
入力に指定できるファイル形式は、.wav 以外に .mp3, .m4a や .mp4 など ffmpeg が読めるフォーマットであれば大体可能です。(.mp4 の動画ファイルでも可でした。)
実行後、同じディレクトリに以下のファイルが出力されます:
example-ja.json:JSON 形式example-ja.srt:一般的な字幕ファイルexample-ja.tsv:タブ区切り形式example-ja.txt:プレーンテキストexample-ja.vtt:一般的な字幕ファイル
文字起こしの例
例として、効果音ラボ にあるファイルを利用させていただきます。
→ [声素材] – [アプリ・音声案内(落ち着いた女性)] – [放送] – [本日は…] のファイル
これを sample.mp3 として保存して、C:\Wisper におきます。
以下を実行します。
(初めて利用するモデルの場合はダウンロードが行われます。)
whisper.exe sample.mp3 --language Japanese --model large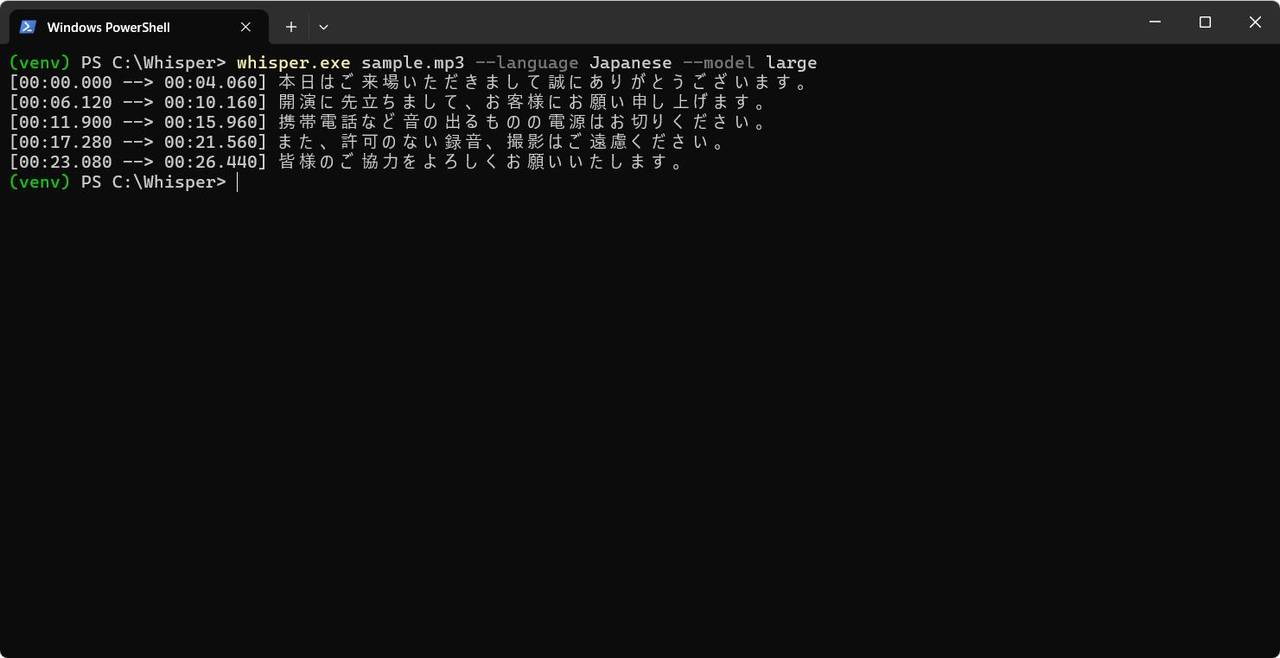
結果、以下が出力されました。
- sample.json
- sample.srt
- sample.tsv
- sample.txt
- sample.vtt
sample.vtt の中身は以下です。
WEBVTT
00:00.000 --> 00:04.060
本日はご来場いただきまして誠にありがとうございます。
00:06.120 --> 00:10.160
開演に先立ちまして、お客様にお願い申し上げます。
00:11.900 --> 00:15.960
携帯電話など音の出るものの電源はお切りください。
00:17.280 --> 00:21.560
また、許可のない録音、撮影はご遠慮ください。
00:23.080 --> 00:26.440
皆様のご協力をよろしくお願いいたします。ちゃんと文字に起こされていることがわかります。
使い方のカスタマイズ例
文字起こしの際に同時に英語に翻訳することも可能です。
# 翻訳付きで出力(日本語 → 英語に翻訳)
whisper example-ja.wav --task translate --model large上記の [文字起こしの例] で使った sample.mp3 でこれを行うと以下のようになります。
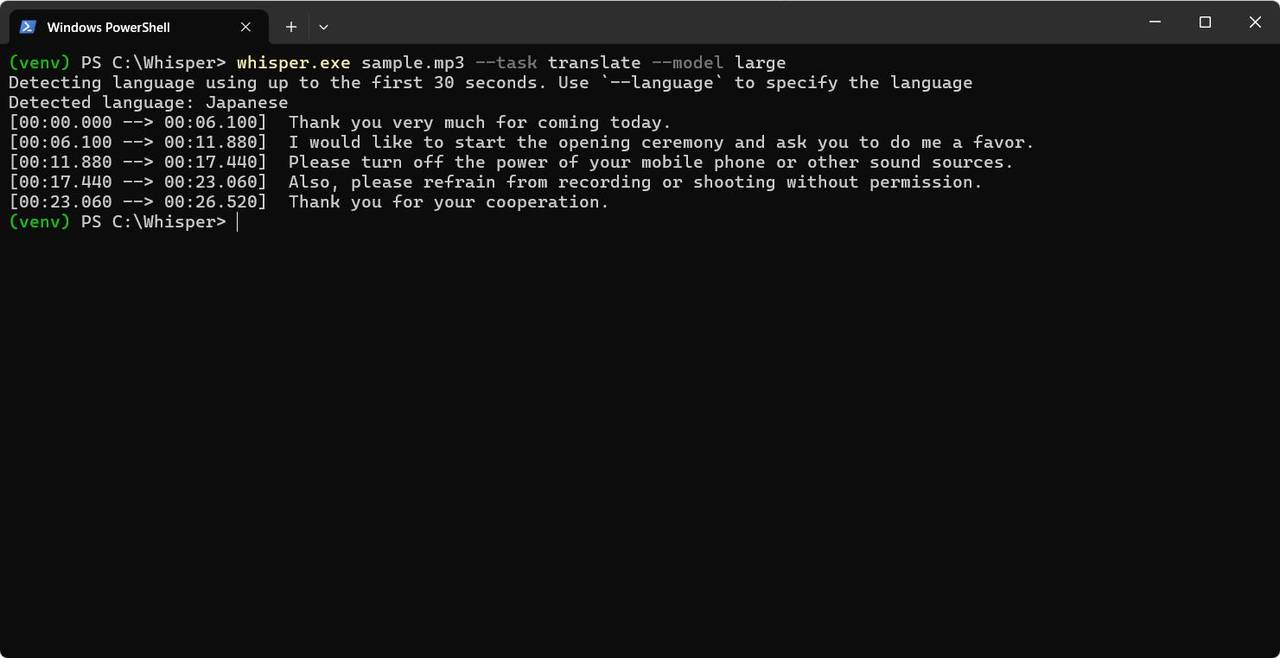
sample.vtt の中身
WEBVTT
00:00.000 --> 00:06.100
Thank you very much for coming today.
00:06.100 --> 00:11.880
I would like to start the opening ceremony and ask you to do me a favor.
00:11.880 --> 00:17.440
Please turn off the power of your mobile phone or other sound sources.
00:17.440 --> 00:23.060
Also, please refrain from recording or shooting without permission.
00:23.060 --> 00:26.520
Thank you for your cooperation.Python から使う場合
Python スクリプト内で利用する場合も簡単です。
例)
import whisper
import json
# Whisper モデルのロード
model = whisper.load_model("large")
# 音声ファイルのロードと処理
audio = whisper.load_audio("sample.mp3")
audio = whisper.pad_or_trim(audio)
# 音声を文字起こし
result = model.transcribe(audio)
# JSON形式で保存
with open("output.json", "w") as json_file:
json.dump(result, json_file, ensure_ascii=False, indent=4)
# SRT形式で保存
with open("output.srt", "w") as srt_file:
for segment in result['segments']:
srt_file.write(f"{segment['id']}\n")
srt_file.write(f"{segment['start']} --> {segment['end']}\n")
srt_file.write(f"{segment['text']}\n\n")
# TSV形式で保存
with open("output.tsv", "w") as tsv_file:
for segment in result['segments']:
tsv_file.write(f"{segment['id']}\t{segment['start']}\t{segment['end']}\t{segment['text']}\n")
# TXT形式で保存
with open("output.txt", "w") as txt_file:
txt_file.write(result['text'])
# VTT形式で保存
with open("output.vtt", "w") as vtt_file:
vtt_file.write("WEBVTT\n\n")
for segment in result['segments']:
vtt_file.write(f"{segment['start']} --> {segment['end']}\n")
vtt_file.write(f"{segment['text']}\n\n")実際の文字起こしの速度
細かいところは記載できませんが、例えば Youtube にあるような動画の文字起こしを試したところ、30分くらいの動画の場合、large だと 処理には10分くらいかかりました、turbo だと 同じ動画で 3分くらいで処理できました。
まとめ
Whisper を使えば、手軽に音声をテキスト化することができます。インストールも比較的簡単で、ローカルPCでも十分に動かせます。音声データの前処理や分析の入口として、非常に強力なツールです。
少し触ってみた限りでは、文字起こしの精度は非常に高いと感じました。
(拾えた言葉の多さや、その後の日本語で書き起こしの際の誤字の少なさ などの観点から)
英語にできるのも面白いです。
文字に起こした際のファイルは .srt, .vtt などで作成されるので、撮影した動画に字幕を付ける際にも利用できると思います。
また、ローカル環境での実行であれば、課金状況などを気にせずに使えて (PCの電気代のみ)、
GeForce RTX 5060Ti (16GB) では現実的な時間での文字起こしができ、精度もかなり良いという印象です。
参考となれば幸いです。