
概要
ローカル PC で AI チャットを動作させるツールやアプリケーションはいくつかありますが 今回は Jan を試してみました。
Jan は、インストールからチャットAIの利用まで GUI ベースで簡単に用意することができ、ローカル環境なのでプライバシーも優先できます。
現時点で細かい調整はできないようですが、オープンソースで商用利用なども可能(AGPLv3 ライセンス) なので、手軽に利用できるという意味では便利だと思います。
今回は、以前 Stable Diffusion を利用したのと同じ環境に Jan を導入してみます。
OS: Windows 11 Pro
CPU : Intel Core i5-9500 3.00GHz
Memory : 40GB
GPU : NVIDIA GeForce RTX 3050 6G (VRAM : 6GB)
Jan とは
Jan は、ローカルの PC でオフラインで実行可能な チャットAI アプリケーションです。
特徴として以下が挙げられています。
Features
- Download popular open-source LLMs (Llama3, Gemma or Mistral,…) from Model Hub or import any GGUF models
- Connect to cloud model services (OpenAI, Anthropic, Mistral, Groq,…)
- Chat with AI models & customize their parameters in an intuitive interface
- Use local API server(opens in a new tab) with OpenAI-equivalent API
- Customize Jan with extensions
Philosophy
Jan is built to be user-owned:
https://jan.ai/docs
- Open source via the AGPLv3 license(opens in a new tab)
- Local-first(opens in a new tab), with all data stored locally
- Runs 100% offline, with privacy by default
- Free choice of AI models, both local and cloud-based
- We do not collect or sell user data. See our Privacy.
機械翻訳
機能
- Model Hub から人気のあるオープンソースの大規模言語モデル(Llama3、Gemma、Mistral など)をダウンロードするか、任意の GGUF モデルをインポート可能
- クラウド上のモデルサービス(OpenAI、Anthropic、Mistral、Groq など)に接続可能
- 直感的なインターフェースで AI モデルとチャットし、そのパラメータをカスタマイズ可能
- OpenAI と同等の API を備えたローカル API サーバーを利用可能
- 拡張機能を使って Jan をカスタマイズ可能
哲学
Jan はユーザー所有を前提として作られています:
- AGPLv3 ライセンスによるオープンソース
- すべてのデータがローカルに保存されるローカルファーストの設計
- プライバシーを最優先し、完全にオフラインで動作
- ローカルおよびクラウドベースの AI モデルを自由に選択可能
インストール方法
(1) 公式サイトからダウンロードします。
https://jan.ai/ にアクセスし、使用しているOS(Windows、macOS、Linux)に対応したインストーラーをダウンロードします。
ここでは Windows 版をダウンロードします。
(2) ダウンロードした .exe を実行します。
本稿更新時点では jan-win-x64-0.5.14.exe がダウンロードできました。
これを実行しインストールを行います。

インストール先などは聞かれずに、%USERPROFILE%\AppData\Local\Programs\jan にインストールされます。
(例: C:\Users\ユーザ名\AppData\Local\Programs\jan)
モデルなどのデータは別のフォルダに置かれます。デフォルトだと C:\Users\user\AppData\Roaming\Jan の配下です。
(例: C:\Users\ユーザ名\AppData\Roaming\Jan\data)
この data フォルダの場所は後から変更可能です。
対象のドライブには十分な空き容量が確保しておいたほうが良いです。
インストールが完了すると自動で Jan が開始されます。
Jan の初回実行とモデルのダウンロード
Jan を実行した際の画面は以下となります。
初回実行時は、[Help Us Improve Jan] のダイアログが表示されているので、内容を確認してどちらかを選択します。
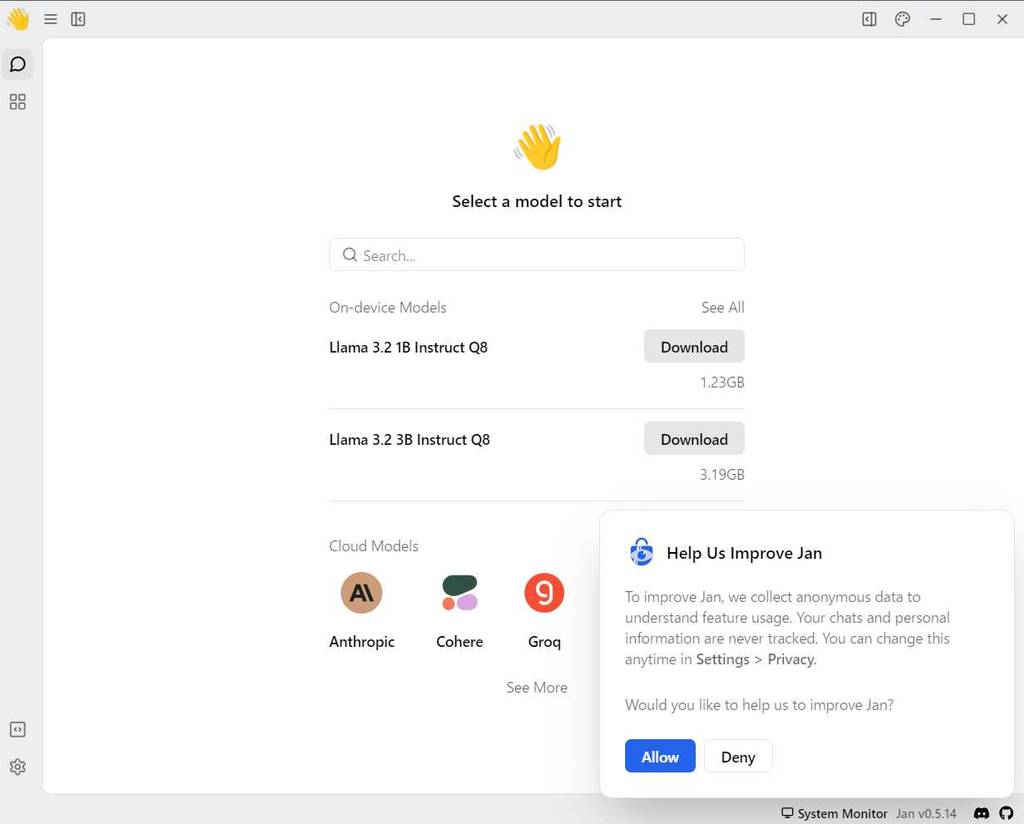
また、最初は モデル (LLM) がダウンロードされていないため、ダウンロードを行うところから実施する必要があります。
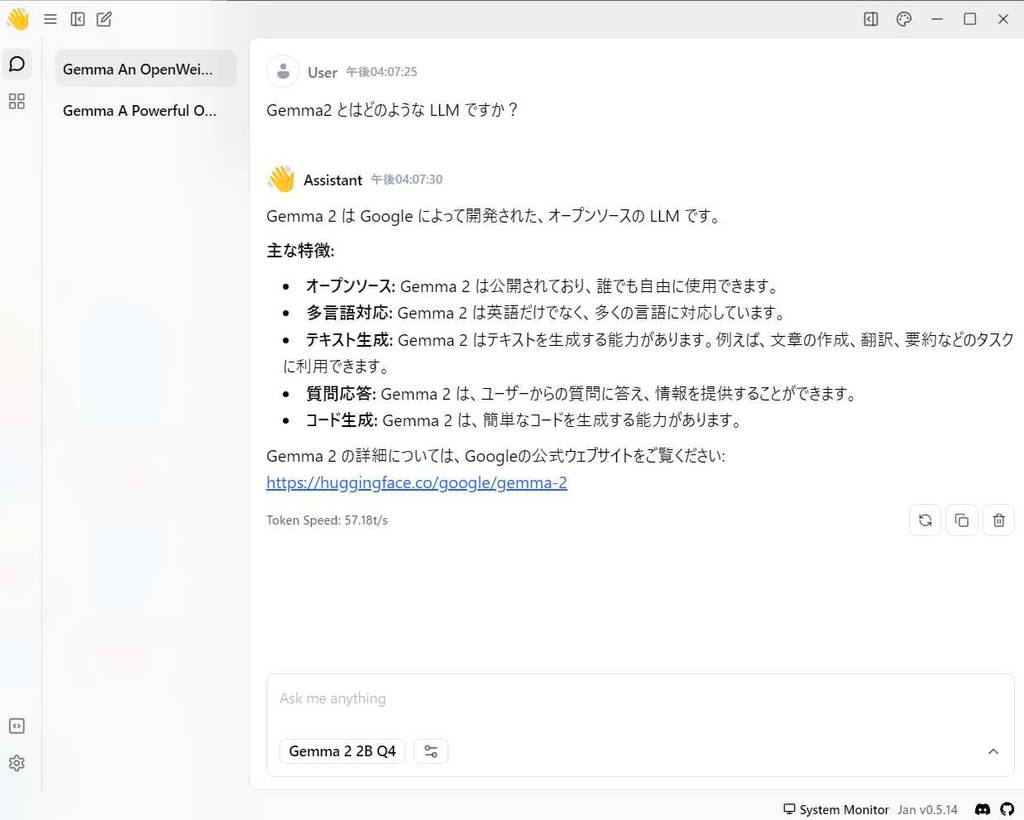
個人的には Gemma2 を利用してみたかったので、ここでは Gemma2 のダウンロードを行います。
Gemma2 は、Google によって開発されたオープンソースの LLM で Gemma2 License で公開されています。
https://github.com/google-deepmind/gemma/blob/main/LICENSE
(1) 左側、上から2つ目 Hub ボタンをクリック
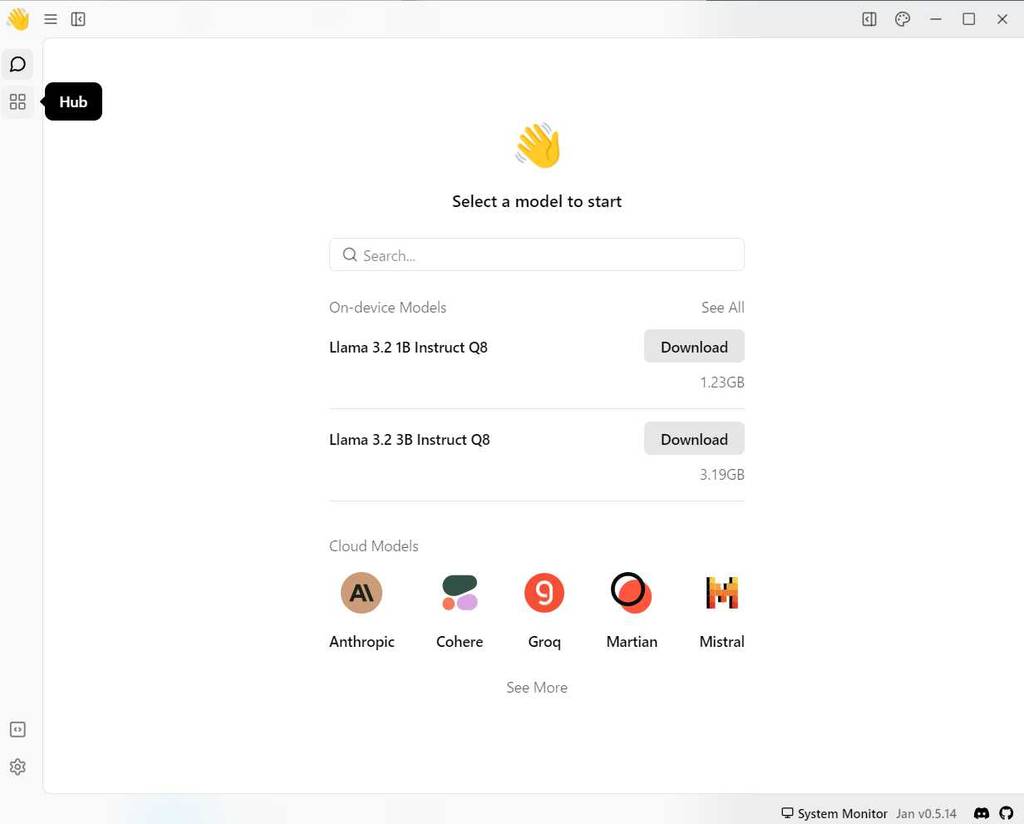
(2) 検索ボックスに Gemma と入力
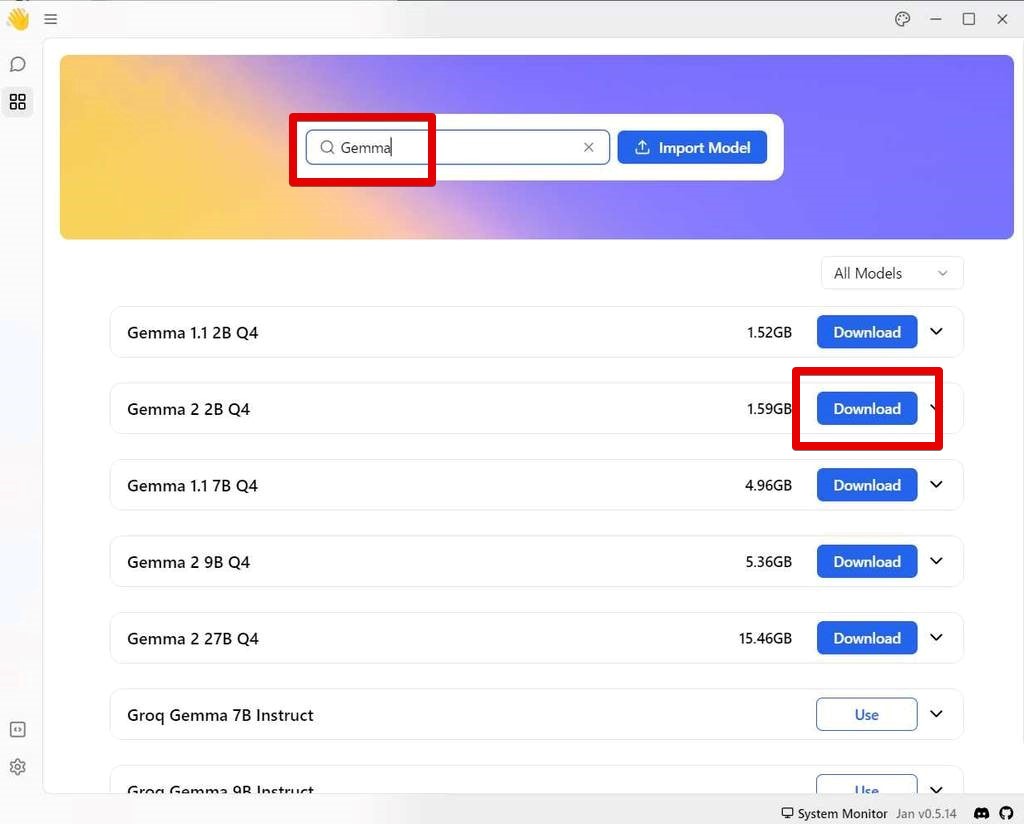
(3) ここでは、私の PC のスペックも考慮して [Gemma 2 2B Q4] を利用することにします。
[Gemma 2 2B Q4] の右の [Download] をクリックします。
ダウンロードの完了を待ちます。
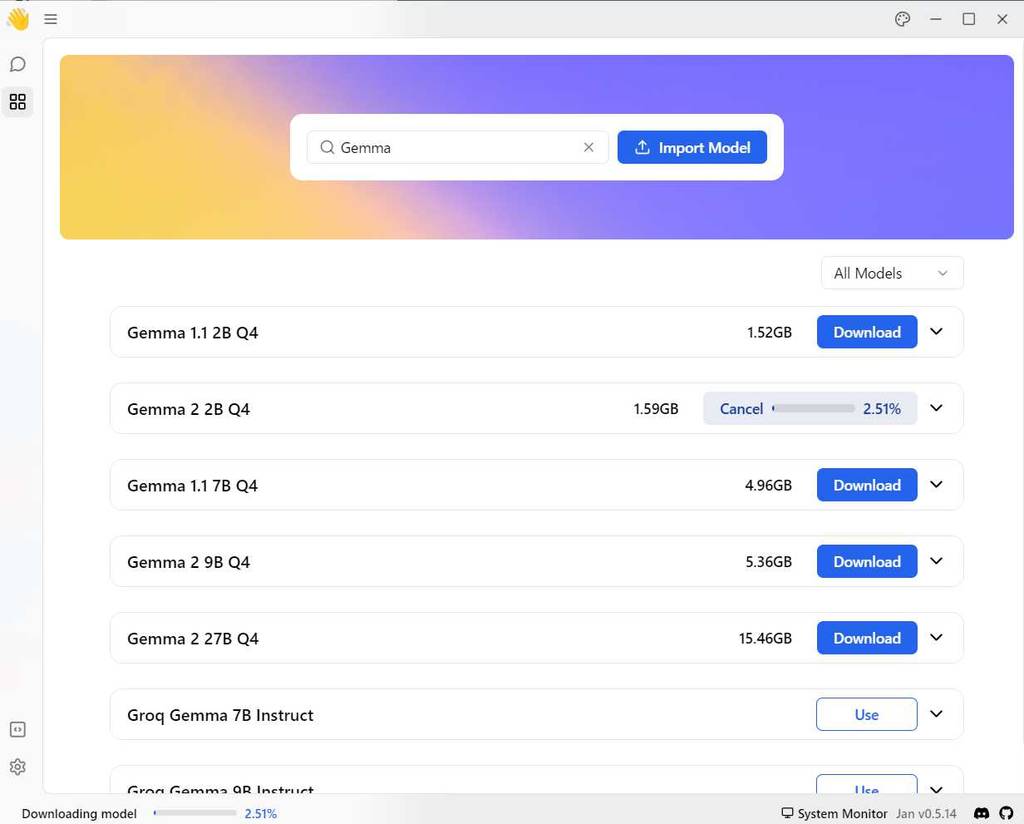
(4) ダウンロードが完了したら、そのまま [Use] ボタンをクリックするか、左側の一番上の [Thread] をクリックします。
(5) チャット画面が開きます。プロンプト入力欄のドロップダウンメニューで [Gemma 2 2B Q4] が選択されていることを確認して、プロンプトを入力します。
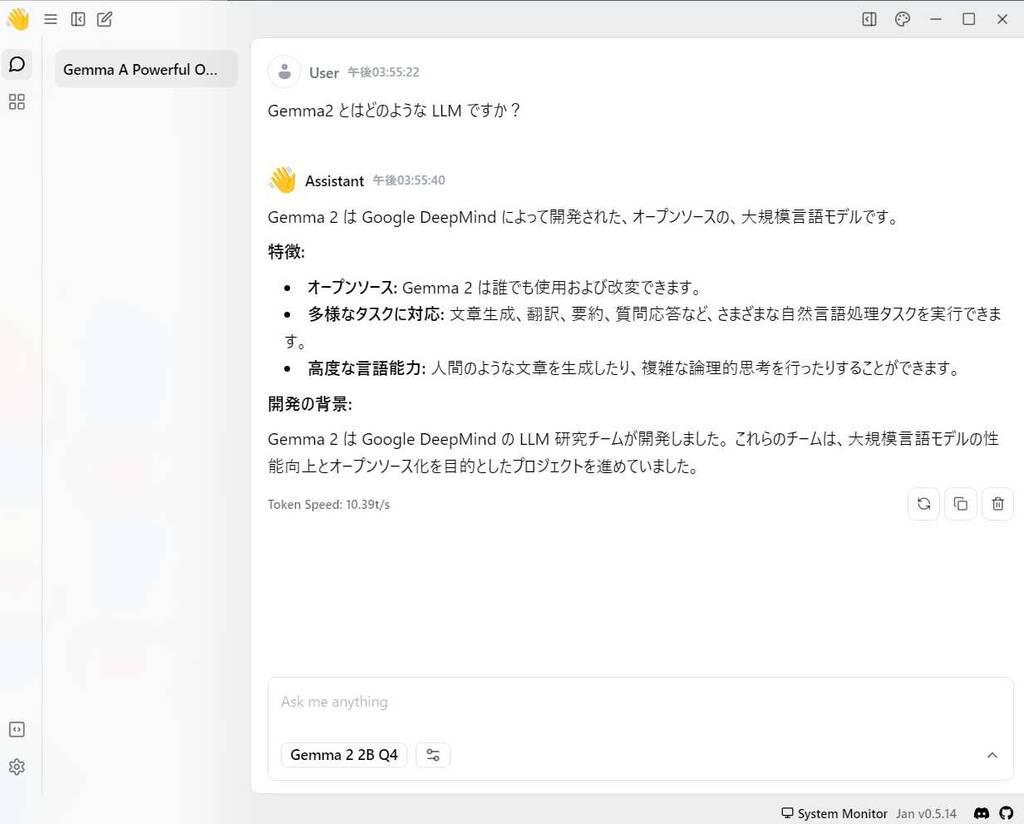
私の環境だと Gemma 2 2B Q4 のサイズの LLM であれば、比較的待ち時間の少ないチャットがやりとりができます。
環境に合わないサイズの大きいモデルだと、時間が非常にかかったり返答の生成が途中で止まったりします。
Jan の設定
Jan の設定を行うには、左側一番下の [Settings] をクリックします。
設定例
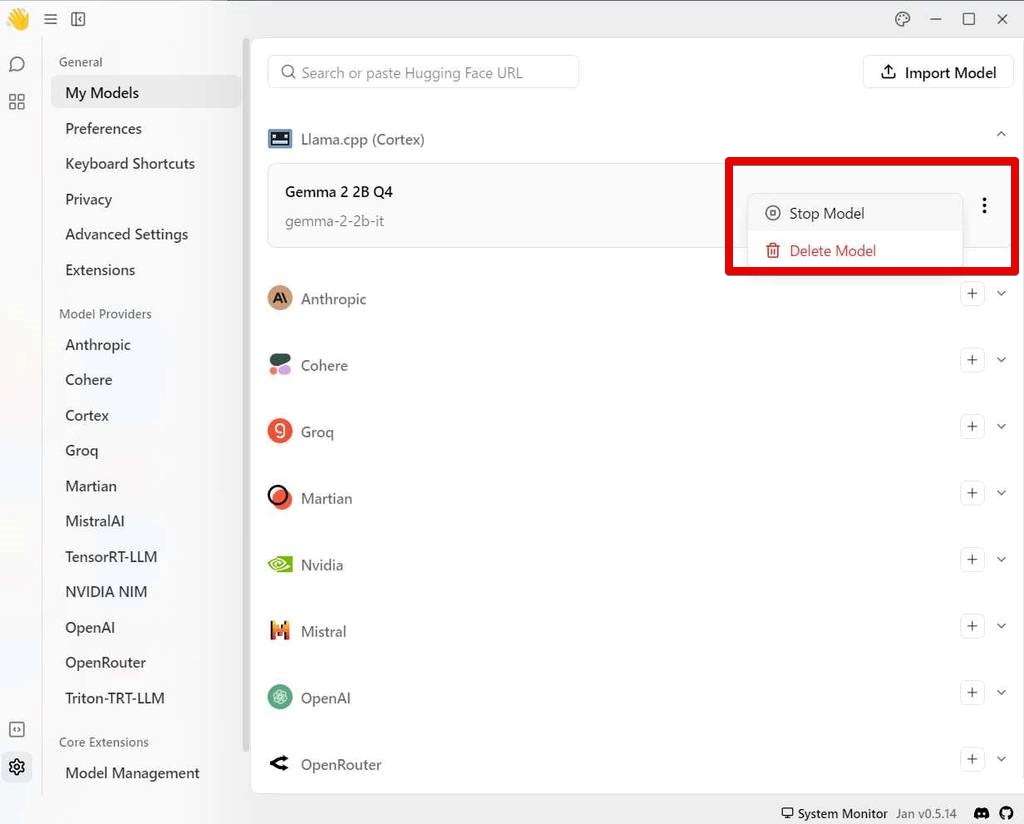
- もしダウンロード済みのモデルが不要になった場合は、[My Models] から対象のモデルの右側の 三点ドットのから [Delete Model] で削除できます。
- GPU Acceleration を利用する場合は、[Advanced Settings] から [GPU Acceleration] をオンにします。
- データフォルダを変更する場合は、[Jan Data Folder] から行います。
など
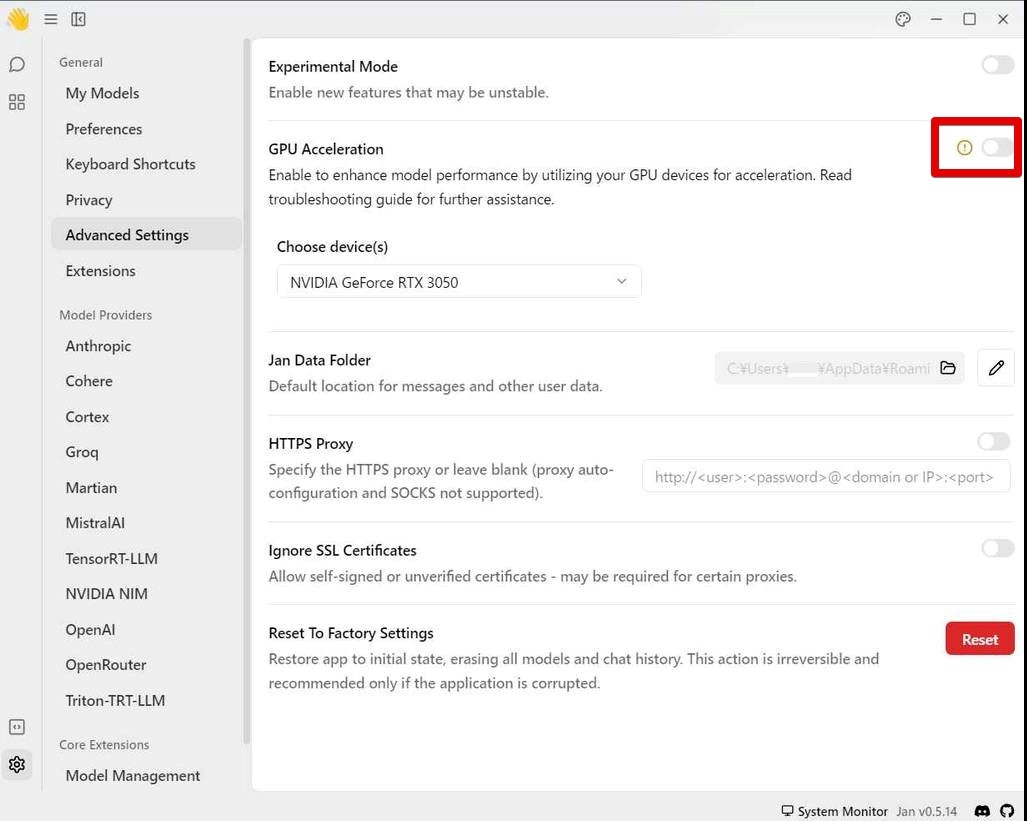
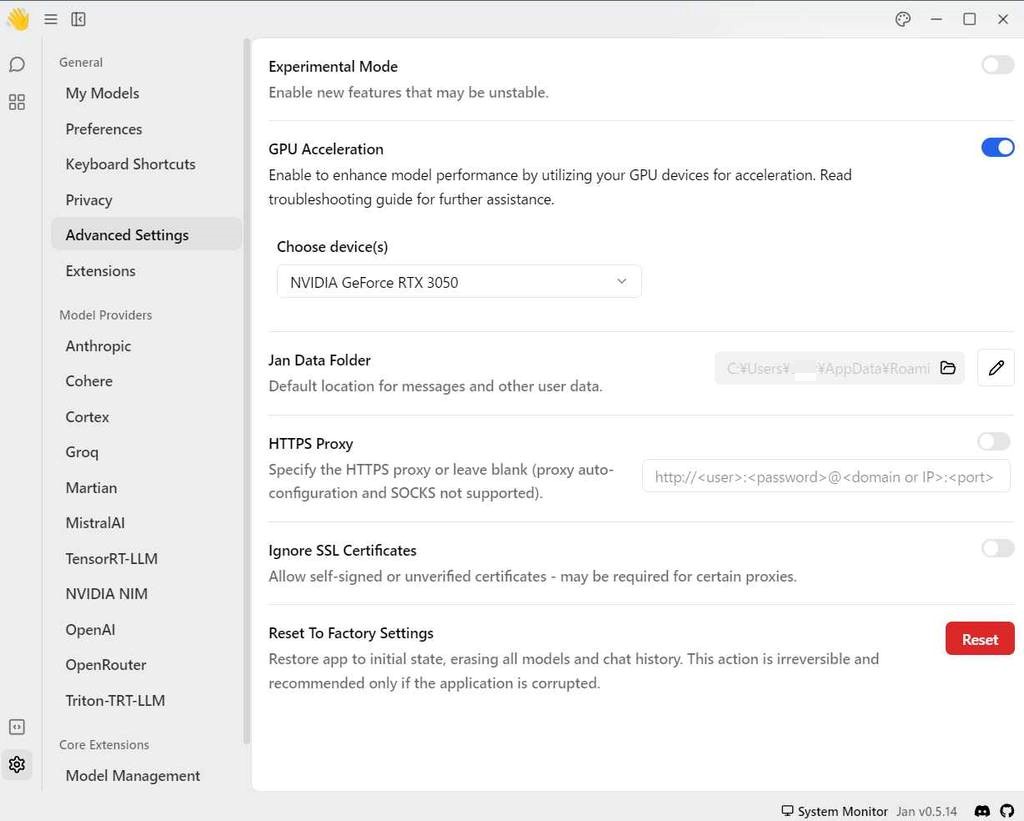
GPU を利用すると速くなるか?
GPU Acceleration を有効にした後、Jan のアプリケーションを停止し、新規でスレッドを作成してから、再度同じプロンプトを実行してみたところ、CPU に比べると 5倍くらいの Token Speed で応答が生成されました。
任意のモデルを読み込む方法
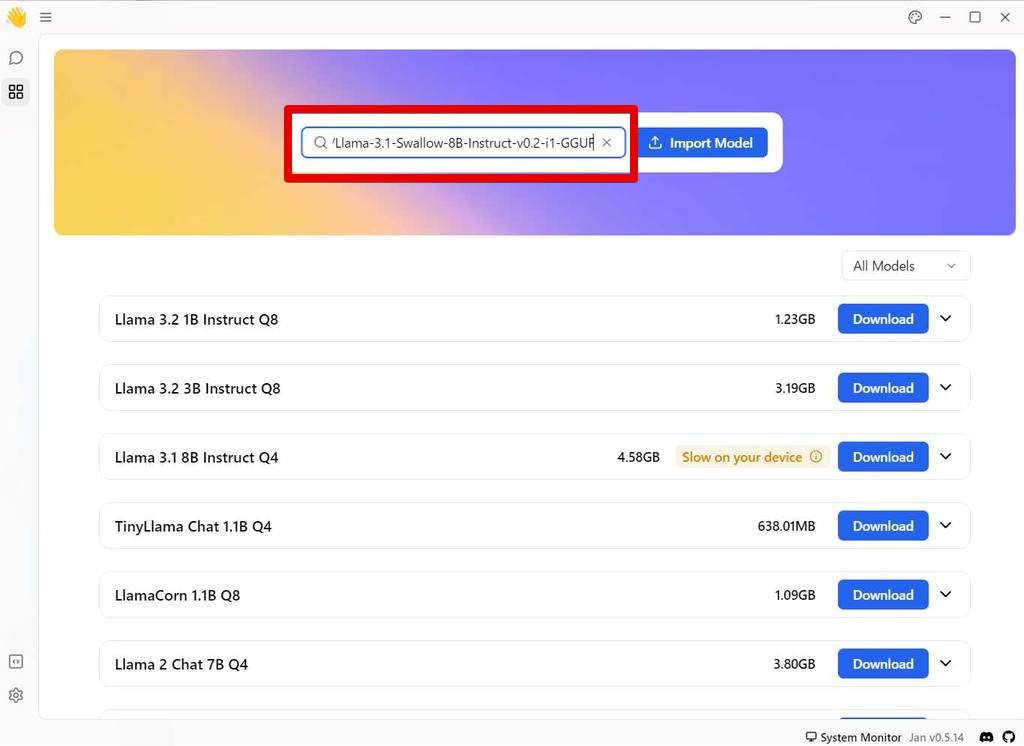
Hub の画面で表示されていないモデルでも、Hugging Faceで公開されていれば簡単に読み込めます。
ドキュメントに記載されている [2. Import from Hugging Face] の方法で行う形です。
https://jan.ai/docs/models/manage-models
具体的には Hub の画面を表示させて、対象のモデルの Hugging Face の URL を検索ボックスに入力して Enterを入力します。
例えば、
https://huggingface.co/mradermacher/Llama-3.1-Swallow-8B-Instruct-v0.2-i1-GGUF
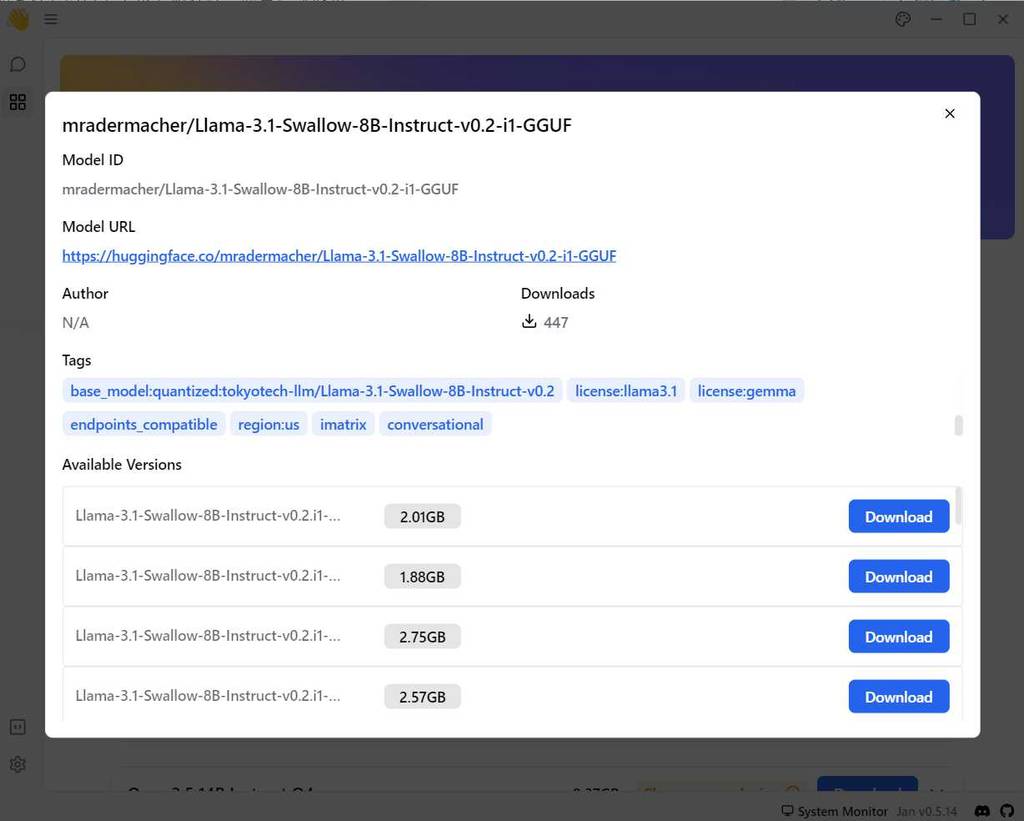
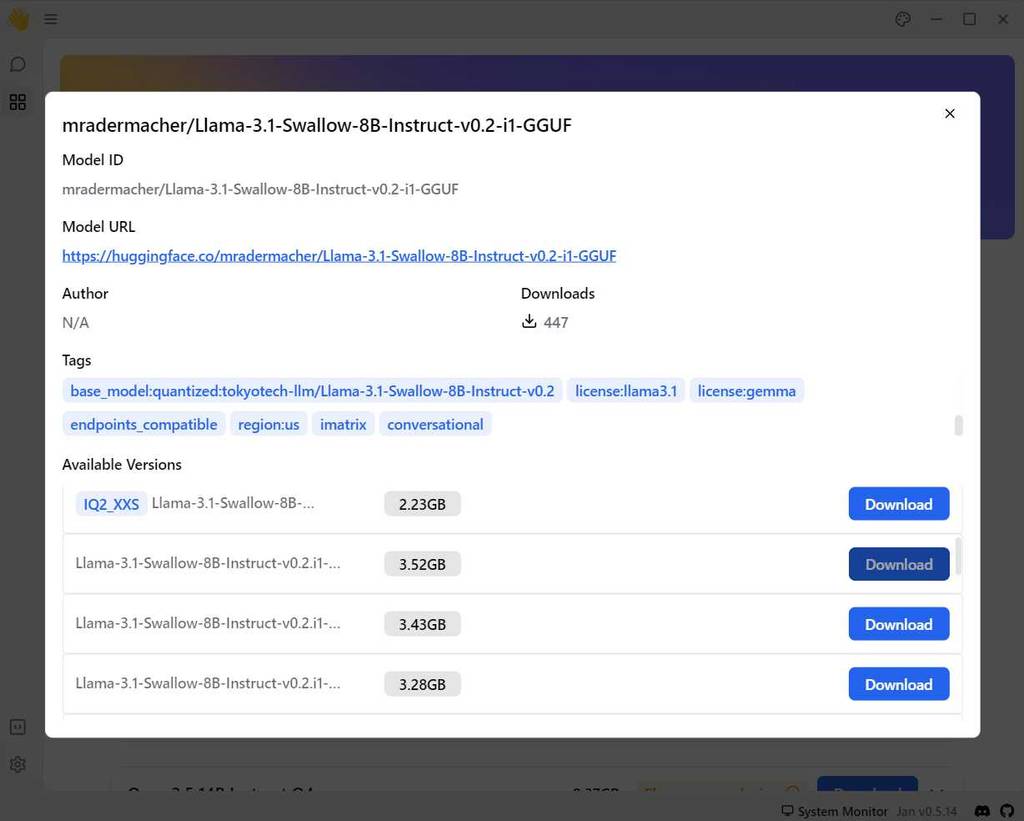
と入力して Enter を入力すると、説明と Available Version が表示されるので、利用したいモデルの Download ボタンをクリックします。
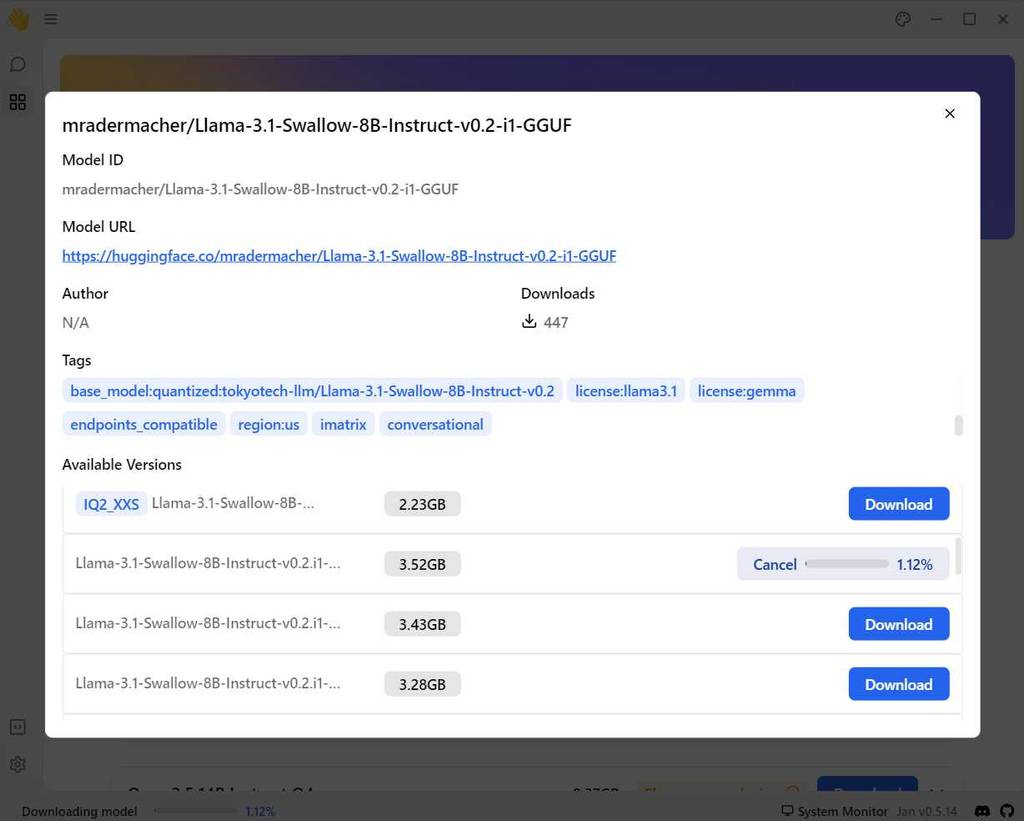
ダウンロードが完了したら Thread 画面のプロンプト欄の下のドロップボックスで対象のモデルを選択すれば利用できます。
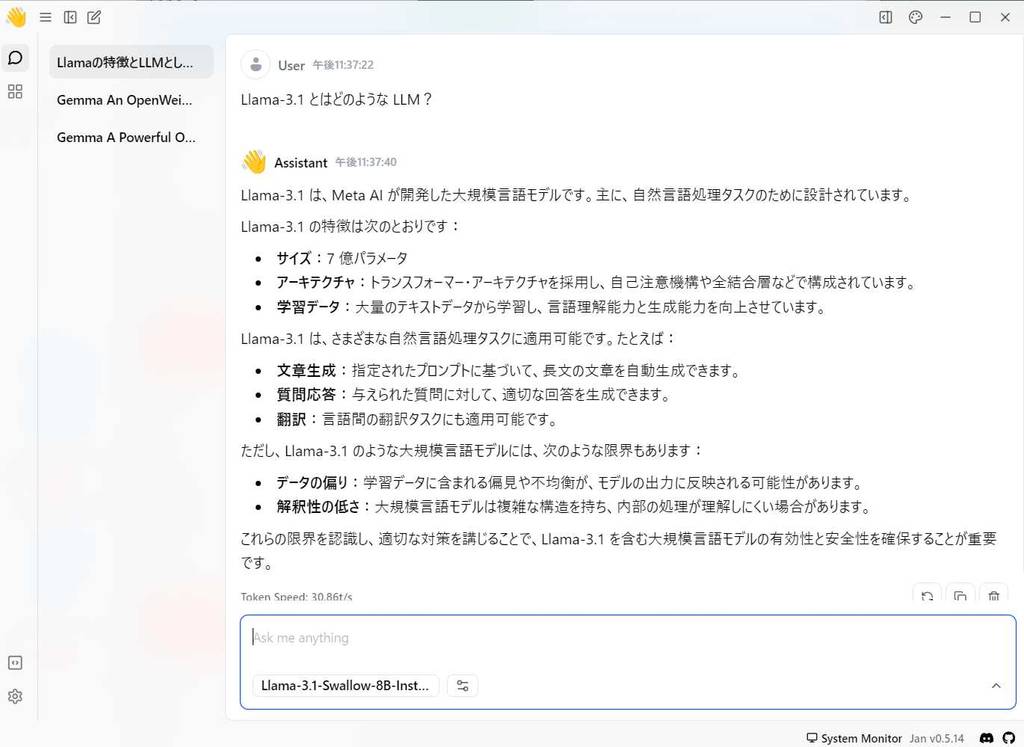
参考となれば幸いです。