
概要
前回は Docker を使わずに、Windows 上で 直接 HeartMuLa Studio を動作させました。
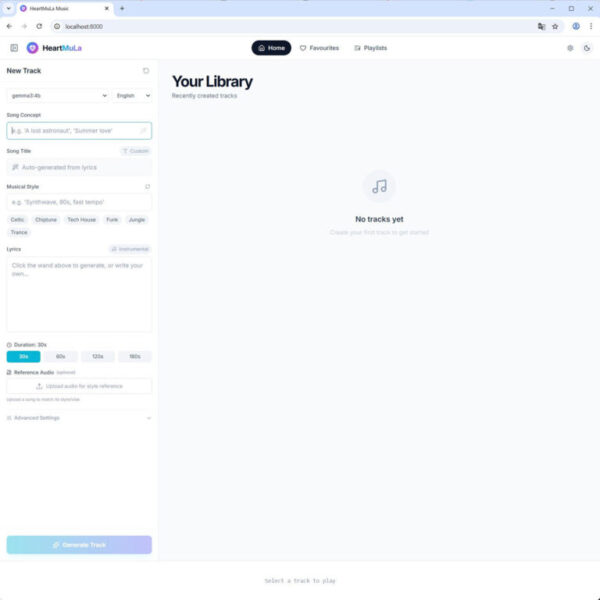
今回は、Docker 環境で動かしてみます。
HeartMuLa Studio の GitHub 情報が更新され、HeartCodec のリポジトリ名を手動で変更する必要はなくなりました。ただし、以下の点については引き続き手動修正が必要です。
- PyTorch 2.4.1 + CUDA 12.4 (or CPU) では RTX 5060 Ti を利用できない
→ PyTorch 2.7.0 + CUDA 12.8 のイメージを使う - Sharded モデル対応のため pipeline.py の修正が必要
HeartMuLa および HeartMuLa Studio について
概要については前回の記事をご参照ください。
ローカル実行環境の用意
PC 環境
同様に NVIDIA GeForce RTX 5060 Ti 16GB を搭載した自作 PC を使用します。

ソフトウェアの準備
いくつか必要なソフトウェアがありますので、事前にインストールしておきます。
実行環境は Windows 11 なので、いずれも Windows 版をインストールする形です。
(1) Docker Desktop on Windows
Docker を動かすために必要です。
https://docs.docker.com/desktop/setup/install/windows-install/
インストール時のオプションはデフォルトのままでよいです。
WSL 環境が使われる形でインストールします。
(2) Git
Git for Windows をインストールして、コマンドプロンプト・ターミナル経由で git コマンドが利用できるようにしておきます。
https://git-scm.com/install/windows
別の記事でも言及しているので必要に応じてご参照ください。
(3) Ollama
歌詞の作成にローカルで実行している Ollama と連携できます。
事前にインストールし、モデルもダウンロードしておきます。
https://ollama.com/

環境構築
基本的には HeartMuLa Studio の公式手順に従いますが、
RTX 5060 Ti 対応および Hugging Face 上の HeartCodec モデル仕様に合わせて一部変更します。
https://github.com/fspecii/HeartMuLa-Studio?tab=readme-ov-file#docker-recommended
(1) GitHub の Repository を Clone
ここでは、C:\HeartMuLa-Studio-Docker に構築します。
ターミナルを開いて以下を実行します。
cd \
git clone https://github.com/fspecii/HeartMuLa-Studio.git
mv HeartMuLa-Studio HeartMuLa-Studio-Docker (2) Dockerfile の変更
デフォルトでは、CUDA 12.1 / PyTorch 2.5.1 がインストールされるため、NVIDIA GeForce RTX 5060 Ti に対応していません。
Dockerfile を変更して、CUDA 12.8 と PyTorch 2.7.0 を利用できるようにします。
対象ファイル : DockerfileC:\HeartMuLa-Studio-Docker\Dockerfile
以下、2か所を変更します。
変更箇所① (26行目)
変更前
FROM nvidia/cuda:12.1.0-cudnn8-runtime-ubuntu22.04変更後
FROM nvidia/cuda:12.8.0-runtime-ubuntu22.04変更箇所② (69行目)
変更前
RUN pip3 install --no-cache-dir --force-reinstall torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu121変更後
RUN pip3 install --no-cache-dir --force-reinstall torch==2.7.0+cu128 torchvision==0.22.0+cu128 torchaudio==2.7.0+cu128 --extra-index-url https://download.pytorch.org/whl/cu128(3) pipeline.py の変更
Hugging Face の HeartCodec-oss-20260123 にあるモデルファイルは、現在は分割されて (Sharded) いますが、HeartMuLa Studio のモデルファイルの読み込み部分がこれに対応しておらず、エラーとなってしまいますので書き換えます。
(ここの変更は Windows 上で直接 HeartMuLa Studio を動かした際と全く同じです。)
対象ファイル : pipeline.py C:\HeartMuLa-Studio-Docker\backend\heartmula\pipeline.py
修正箇所は、297行目から 418行目にあるdef _load_models 関数です。
いくつか変更が必要なので、以下に 変更後の def _load_models 関数全文を記載します。
右上のコピーボタンを使えば、インデントを含めてコピーできます。
(もしインデントが崩れるようなら、def の前は、スペース4つインデントが必要です。後続もそれに合わせてインデントを入れてください。)
def _load_models(self):
(
mula_weights_path,
mula_config_path,
codec_path,
tokenizer_path,
gen_config_path,
) = _resolve_paths(
self.ckpt_root,
self.version,
heartmula_weights_path=self.heartmula_weights_path,
)
from accelerate import init_empty_weights
from mmgp import offload
# Load tokenizer + gen config
self.tokenizer = Tokenizer.from_file(str(tokenizer_path))
self.gen_config = HeartMuLaGenConfig.from_file(str(gen_config_path))
# Load HeartMuLa config
with open(mula_config_path, encoding="utf-8") as fp:
mula_config = HeartMuLaConfig(**json.load(fp))
# Create empty model
with init_empty_weights():
self.mula = HeartMuLa(mula_config)
# --- Add support for sharded HeartMuLa weights ---
if mula_weights_path is None:
sharded_mula = sorted(Path(self.ckpt_root).glob("model-*-of-*.safetensors"))
if sharded_mula:
mula_weights_path = [str(f) for f in sharded_mula]
else:
raise FileNotFoundError("HeartMuLa weights not found (no single file or shards detected)")
# Quantized?
is_quantized = "_int8" in str(mula_weights_path)
if is_quantized:
preprocess_fn = _dequantize_int8_state_dict
else:
preprocess_fn = _strip_heartmula_rope_cache
# Load HeartMuLa weights
offload.load_model_data(
self.mula,
mula_weights_path,
default_dtype=None,
writable_tensors=False,
preprocess_sd=preprocess_fn,
)
# Decoder fix
decoder = self.mula.decoder
delattr(self.mula, "decoder")
self.mula.decoder = [decoder]
if hasattr(self.mula, "_interrupt_check"):
self.mula._interrupt_check = self._abort_requested
self.model = self.mula
self.mula.eval()
# Disable compilation
self.mula.decoder[0].layers._compile_me = False
self.mula.backbone.layers._compile_me = False
first_param = next(self.mula.parameters(), None)
if first_param is not None:
self.mula_dtype = first_param.dtype
# Resolve codec names
codec_weights_name, codec_config_name = _resolve_codec_names(self.codec_version)
# --- Add support for sharded HeartCodec weights ---
if self.heartmula_weights_path and "quantized" in str(self.heartmula_weights_path):
quantized_codec_path = Path(self.heartmula_weights_path).parent / "HeartMula_codec_int8.safetensors"
if quantized_codec_path.is_file():
codec_weights_path = quantized_codec_path
else:
quantized_codec_path = None
else:
quantized_codec_path = None
if quantized_codec_path:
codec_weights_path = quantized_codec_path
else:
sharded_codec = sorted(Path(codec_path).glob("model-*-of-*.safetensors"))
if sharded_codec:
codec_weights_path = [str(f) for f in sharded_codec]
else:
codec_weights_path = Path(codec_path) / codec_weights_name
if not codec_weights_path.is_file():
codec_weights_path = Path(codec_path) / "model.safetensors"
if not isinstance(codec_weights_path, list) and not codec_weights_path.is_file():
raise FileNotFoundError(
f"Expected HeartCodec weights at {codec_path}/{codec_weights_name} or model.safetensors but not found."
)
# Load codec config
codec_config_path = Path(codec_path) / codec_config_name
if not codec_config_path.is_file():
codec_config_path = Path(codec_path) / "config.json"
with open(codec_config_path, encoding="utf-8") as fp:
codec_config = HeartCodecConfig(**json.load(fp))
with init_empty_weights():
self.codec = HeartCodec(codec_config)
self.codec._offload_hooks = ["detokenize"]
self.codec._model_dtype = self.VAE_dtype
# Load codec weights
offload.load_model_data(
self.codec,
codec_weights_path,
default_dtype=self.VAE_dtype,
writable_tensors=False,
preprocess_sd=None,
)
self.codec.eval()
first_param = next(self.codec.parameters(), None)
if first_param is not None:
self.codec_dtype = first_param.dtype
self.sample_rate = getattr(self.codec, "sample_rate", 48000)
self._offload_obj = None
(4) コンテナを起動
cd C:\HeartMuLa-Studio-Docker
docker compose up -d起動後は、http://localhost:8000 でアクセスできます。
初回はモデルのダウンロードがあるので時間がかかります。
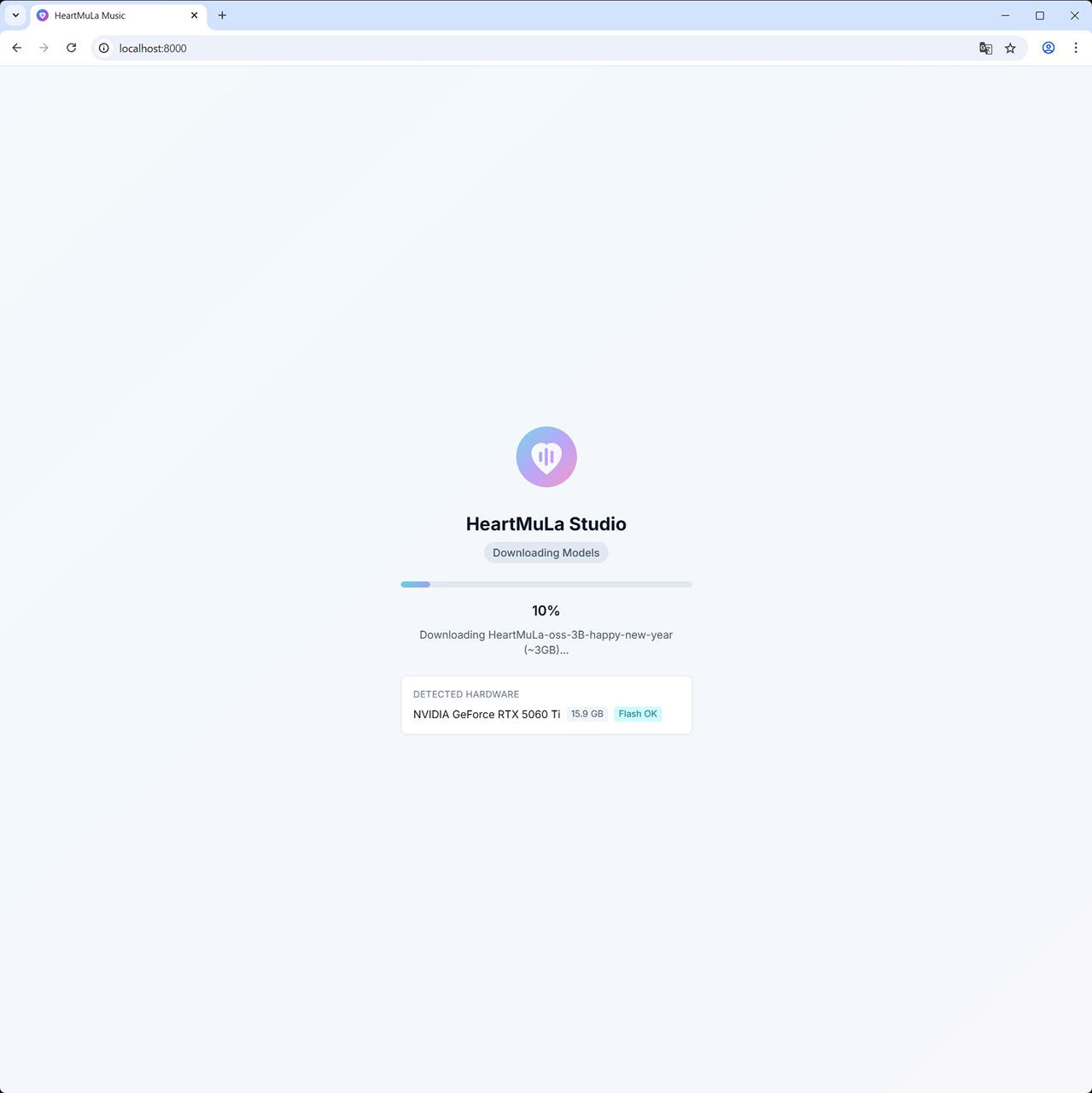
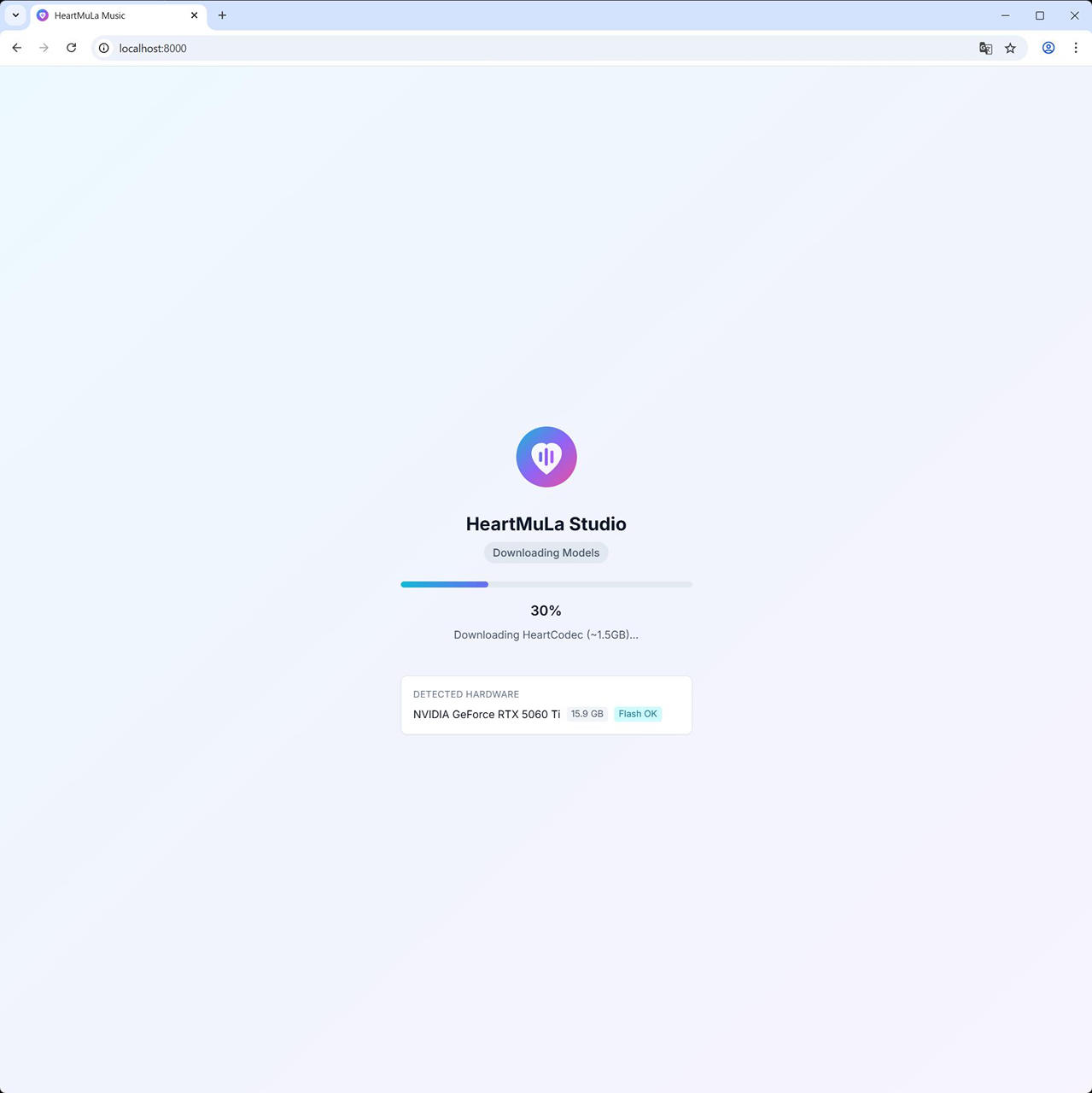
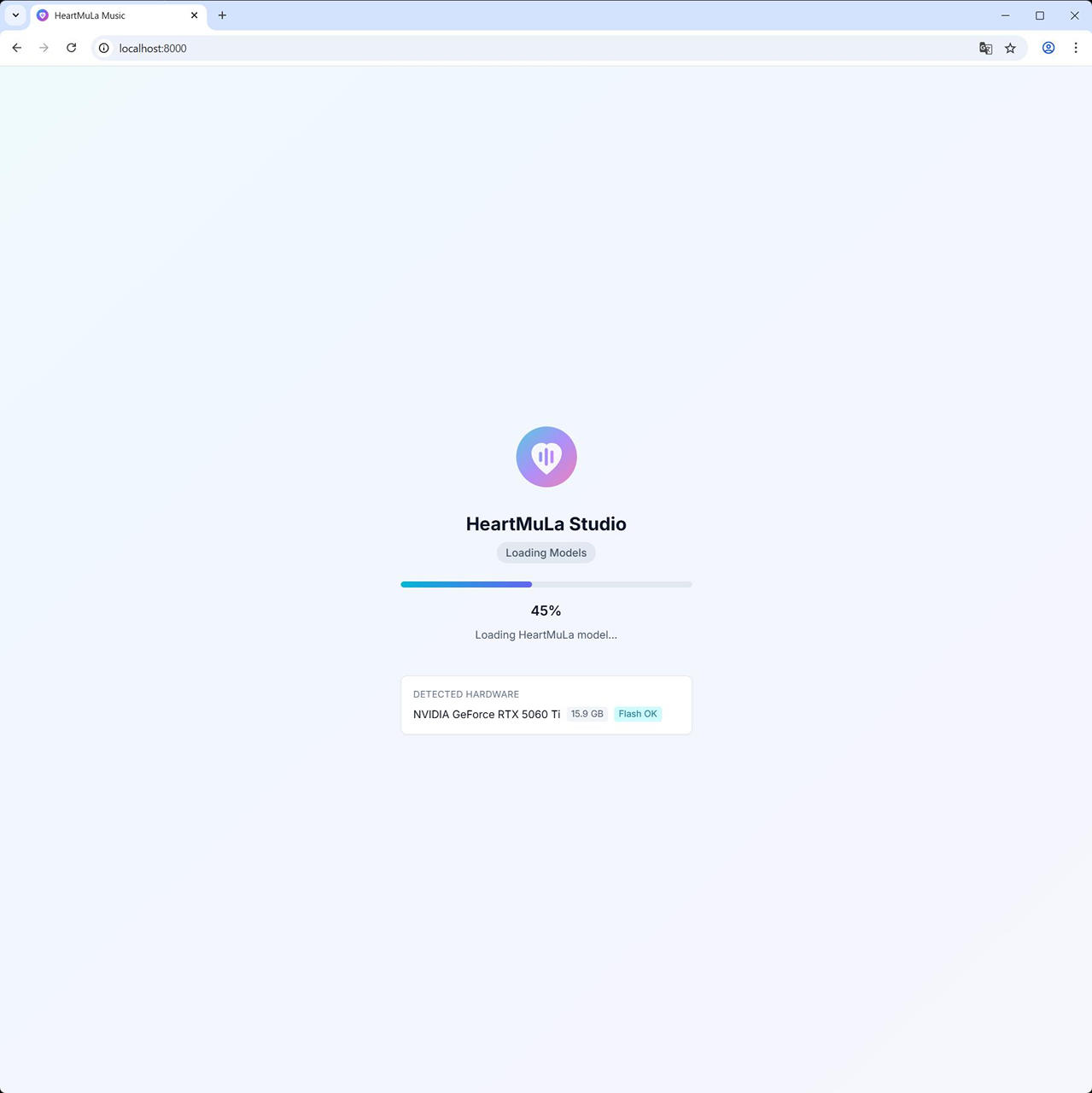
Docker Desktop の GUI でも Container / Image / Volume / Builds が作成されていることを確認できます。
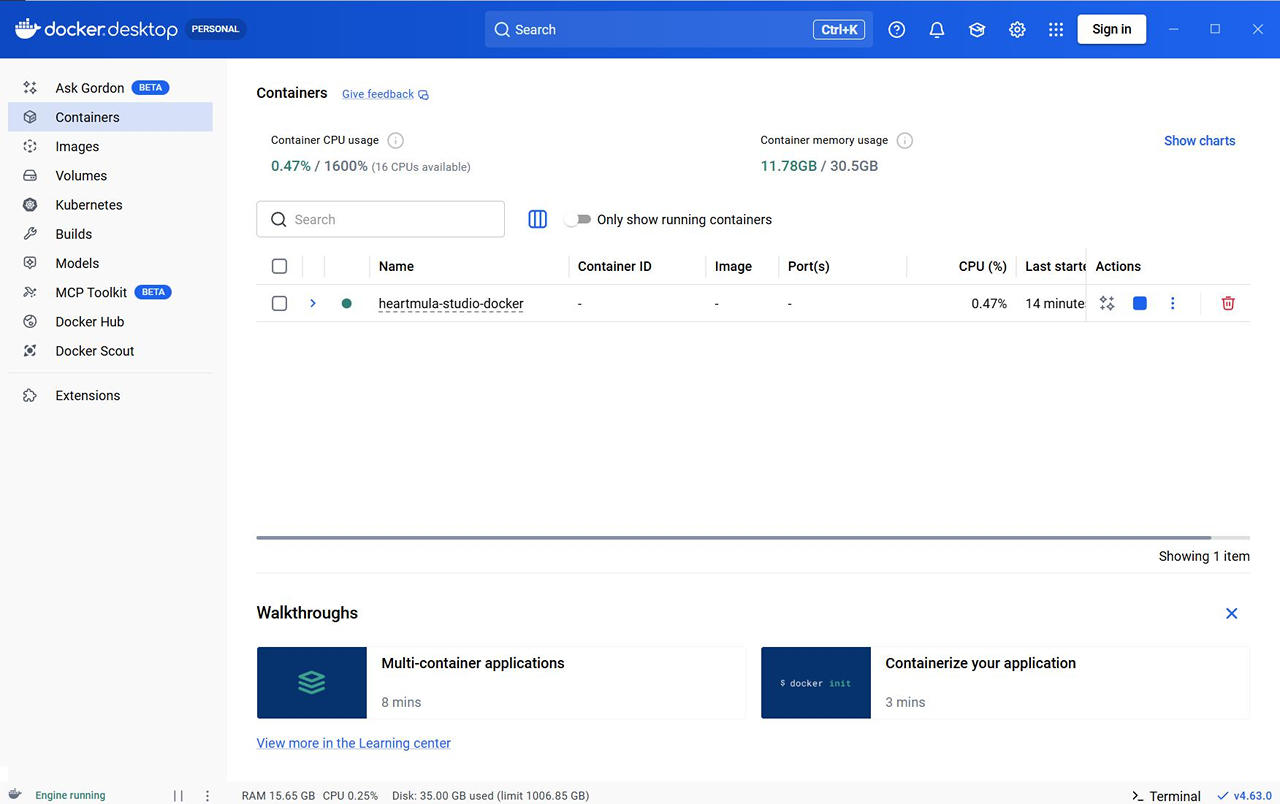
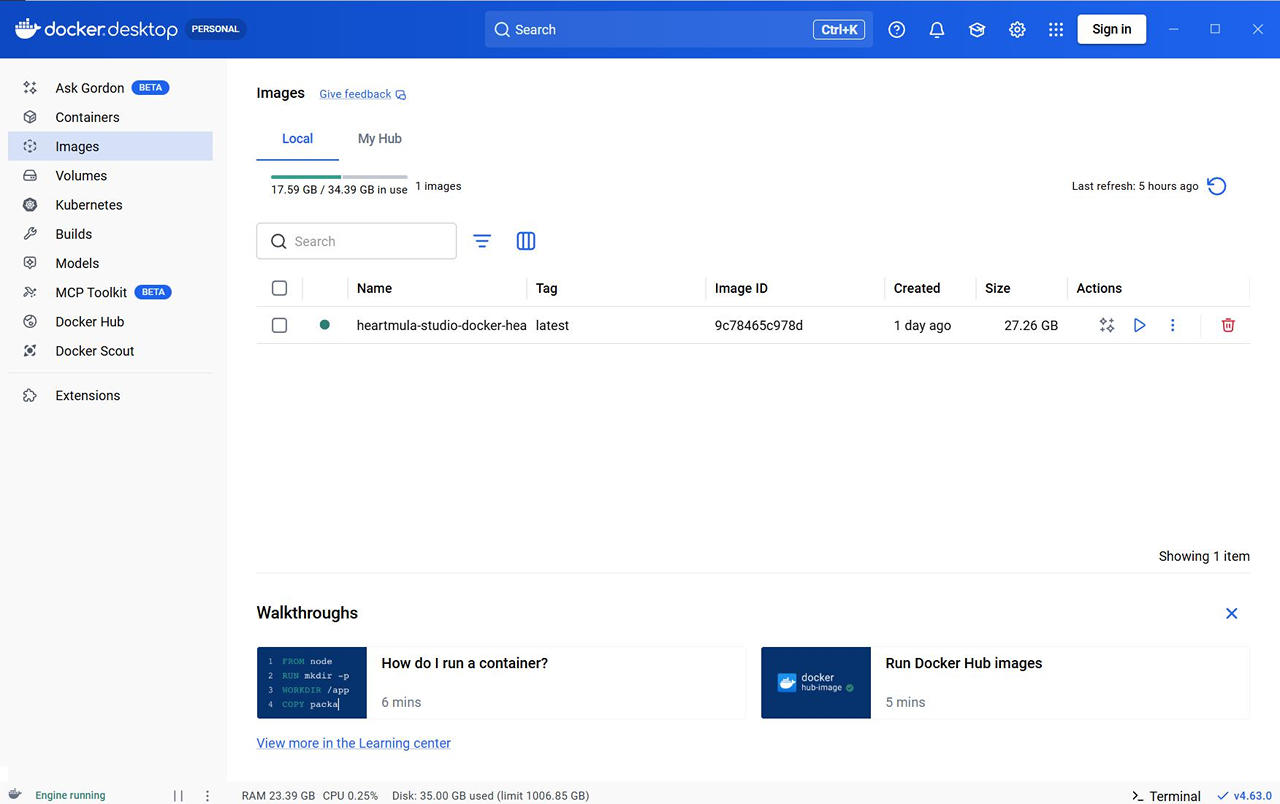
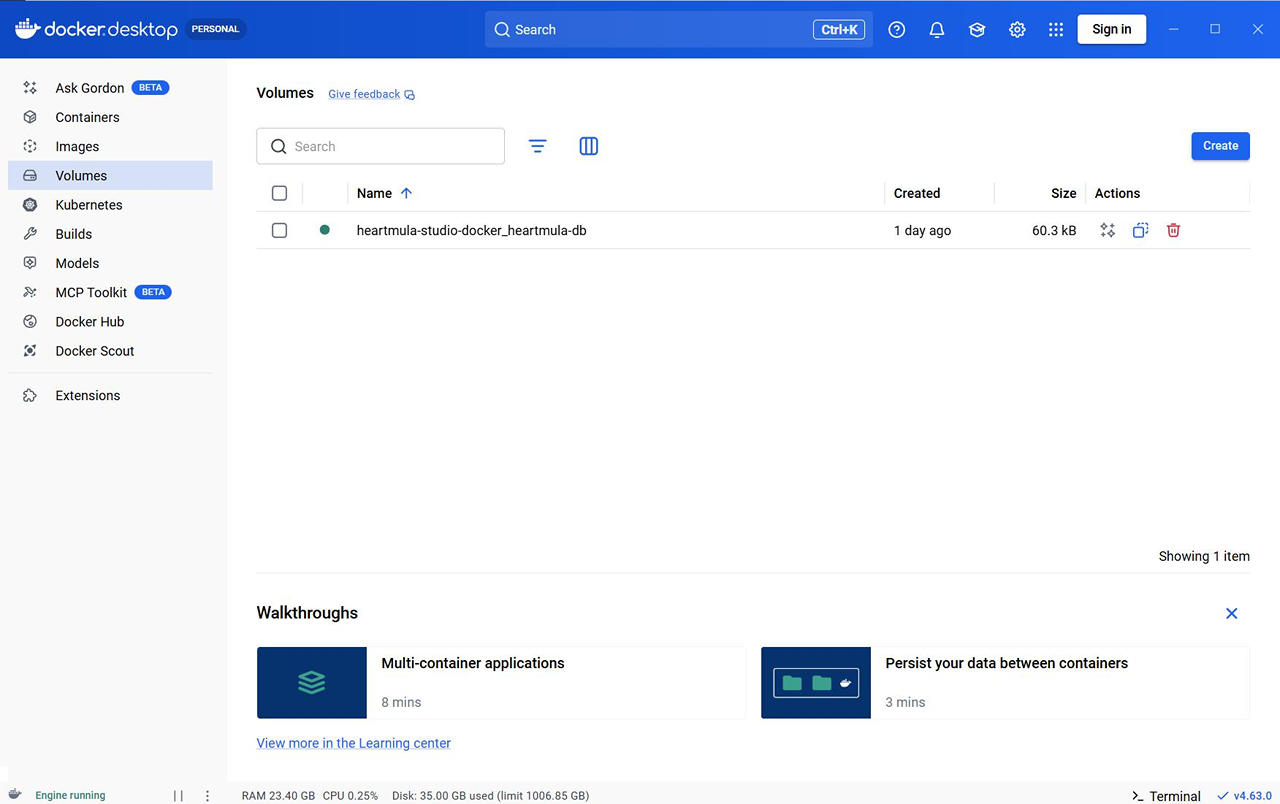
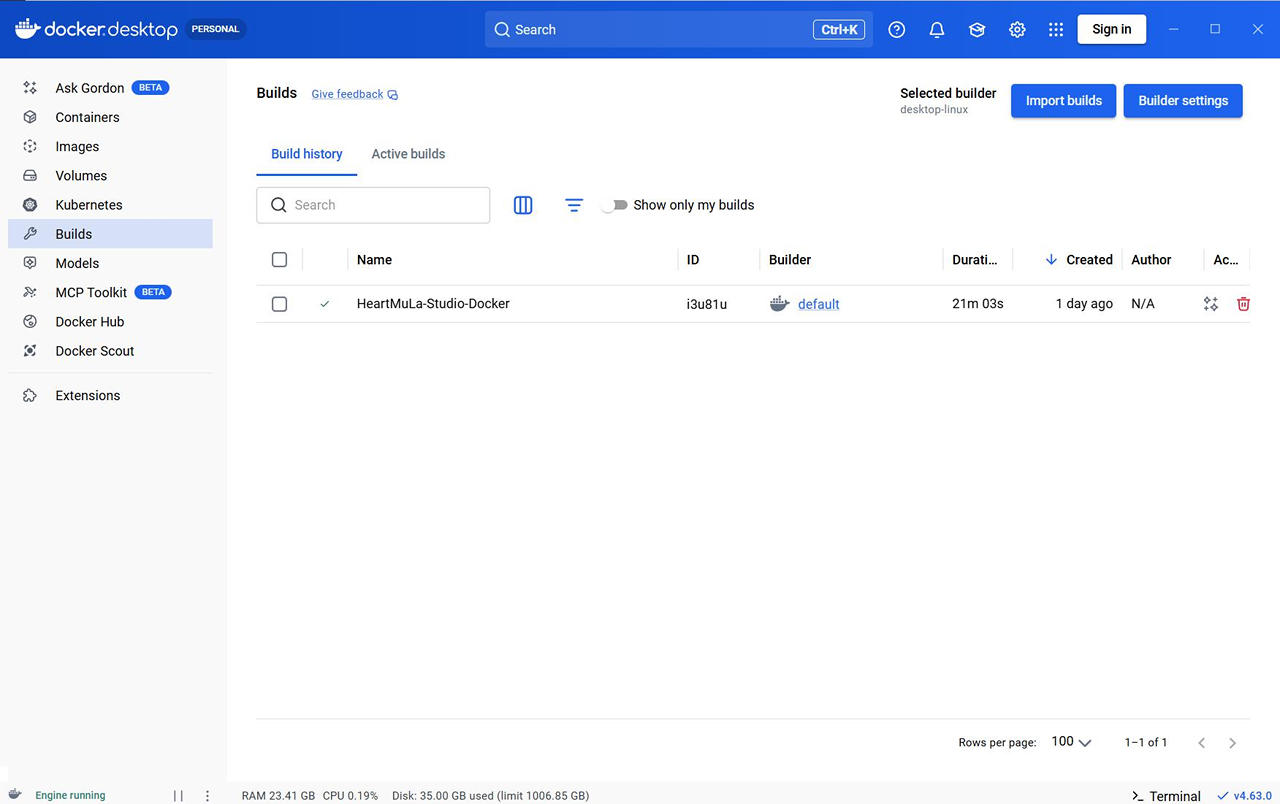
音楽生成
使い方は、Windows 上で直接 HeartMuLa Studio を動かした際と同じです。
(1) Ollama と連携させるので、Ollama はあらかじめ起動しておきます。
(2) HeartMuLa Studio の WebUI 左上で、使用する LLM を選択します。
(3) Japanese を選択します。
(4) Song Concept を入力します。
(5) Song Concept 欄右の Generate Lyrics & style with AI ボタンをクリックします。
(6) LLM での生成を待ちます(60 秒でタイムアウトします)。
(7) [Song Concept], [Musical Style] および [Lyrics] が補完されます。
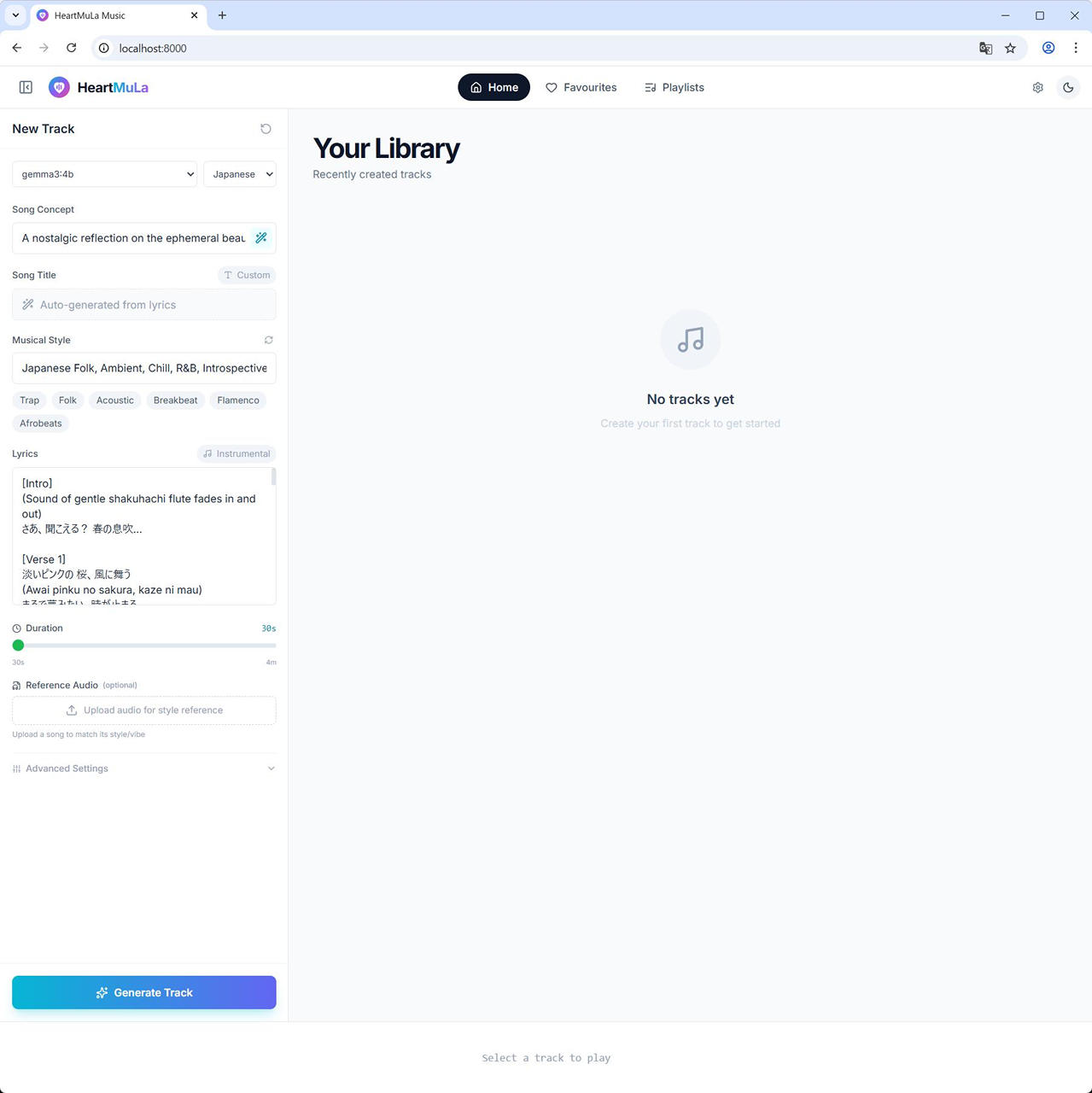
今回は、”桜, 空” と入力して、gemma3:4b で生成した内容が以下となります。
[Song Concept]A nostalgic reflection on the ephemeral beauty of cherry blossoms and new beginnings, blending Japanese aesthetics with contemporary introspection.[Musical Style]
Japanese Folk, Ambient, Chill, R&B, Introspective[Intro]
(Sound of gentle shakuhachi flute fades in and out)
さあ、聞こえる? 春の息吹…
[Verse 1]
淡いピンクの 桜、風に舞う
(Awai pinku no sakura, kaze ni mau)
まるで夢みたい、時が止まる
(Marude yume mitai, toki ga tomaru)
雨上がりの空、光り輝く
(Ameagari no sora, hikari kagayaku)
新しい始まり、心に響く
(Atarashii hajimari, kokoro ni hibiku)
まるでDrakeみたい、この瞬間を刻む
(Marude Drake mitai, kono shunkan o kizamu)
[Verse 2]
古都の石畳、足元に咲く
(Koto no ishigata, asokomi ni saku)
春の匂い、甘くて優しい
(Haru no nioi, amakute yasashii)
Taylor Swiftみたいに、思い出が蘇る
(Taylor Swift mitai ni, omoide ga makoru)
過ぎ去った日々、あの日の私
(Sugisatta hibi, ano hi no watashi)
すべてを抱きしめて、歩き出す
(Subete o dakishimete, arukidasu)
[Chorus]
桜、春、希望の歌
(Sakura, haru, kibou no uta)
心に染み渡る、温かい光
(Kokoro ni shimi wataru, atatakai hikari)
色褪せない、この景色を
(Iroasenai, kono keshiki o)
永遠に、記憶に刻む
(Eien ni, kioku ni kizamu)
[Bridge]
Eminemみたいに、焦燥と興奮
(Eminem mitai ni, shousou to kouhen)
すべてを賭けて、今、ここに立つ
(Subete o kake te, ima, koko ni tatsu)
Travis Scottみたいに、空間に広がる
(Travis Scott mitai ni, kuukan ni hirogaru)
無限の可能性、見つけ出す
(Muzhen no kanousei, mitsukedasu)
もう一度、生まれ変わるように
(Mou ichido, umare kawaru you ni)
[Chorus]
桜、春、希望の歌
(Sakura, haru, kibou no uta)
心に染み渡る、温かい光
(Kokoro ni shimi wataru, atatakai hikari)
色褪せない、この景色を
(Iroasenai, kono keshiki o)
永遠に、記憶に刻む
(Eien ni, kioku ni kizamu)
[Outro]
(Shakuhachi flute returns, layered with synth pads)
桜散る… 春が過ぎる…
(Sakura chiru… Haru ga sugiru…)
また会おう… きっと…
(Mata aou… kitto…)
(Fade to silence)
(8) Duration を設定し、Generate Track ボタンをクリックします。
以前は、Duration は 30s, 60s, 120s, 180s の4択でしたが、今は 240s までの間で 10秒単位で選択できるようになりました。
まずは、30秒で生成
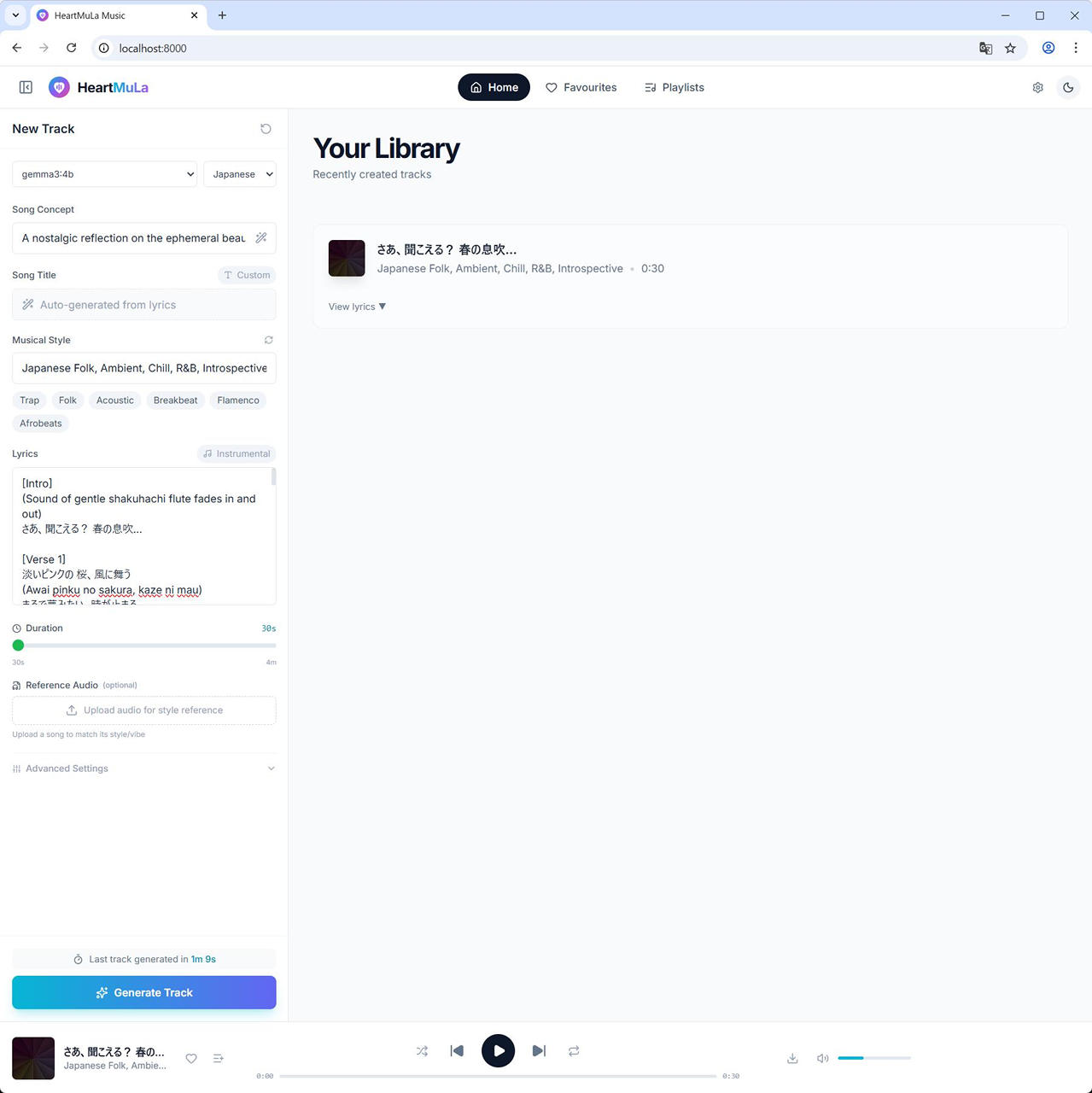
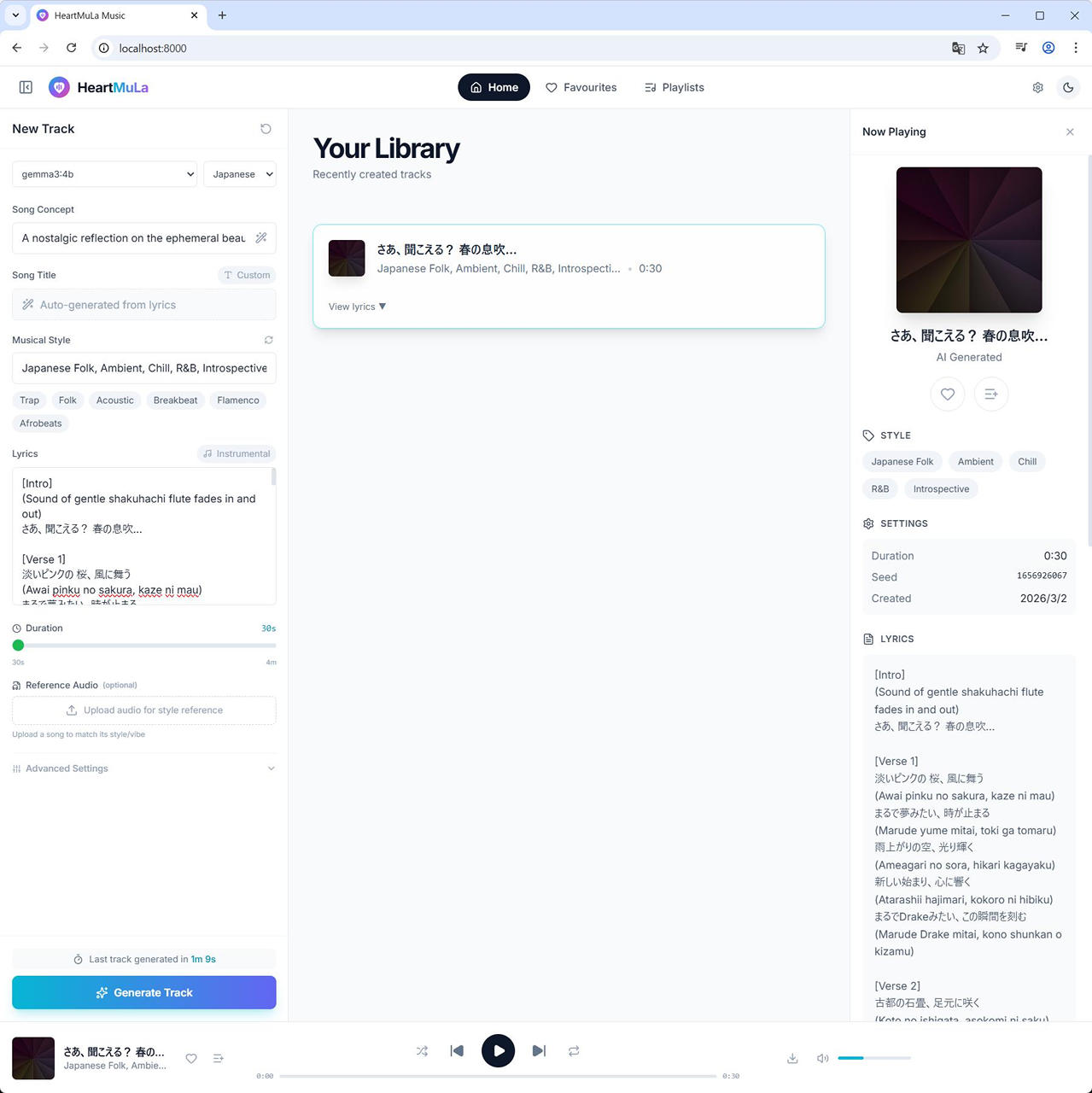
その後、240秒で生成
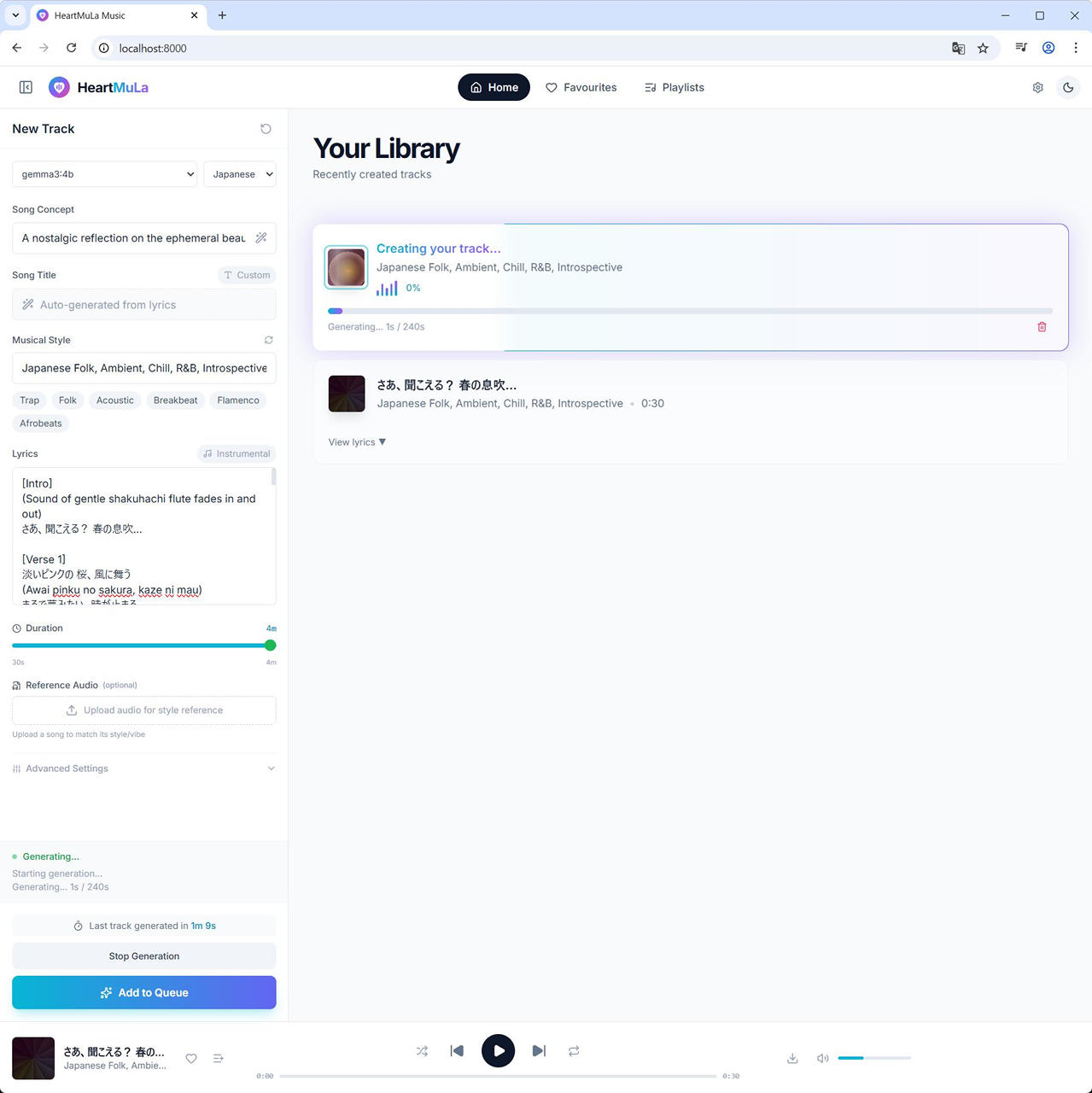
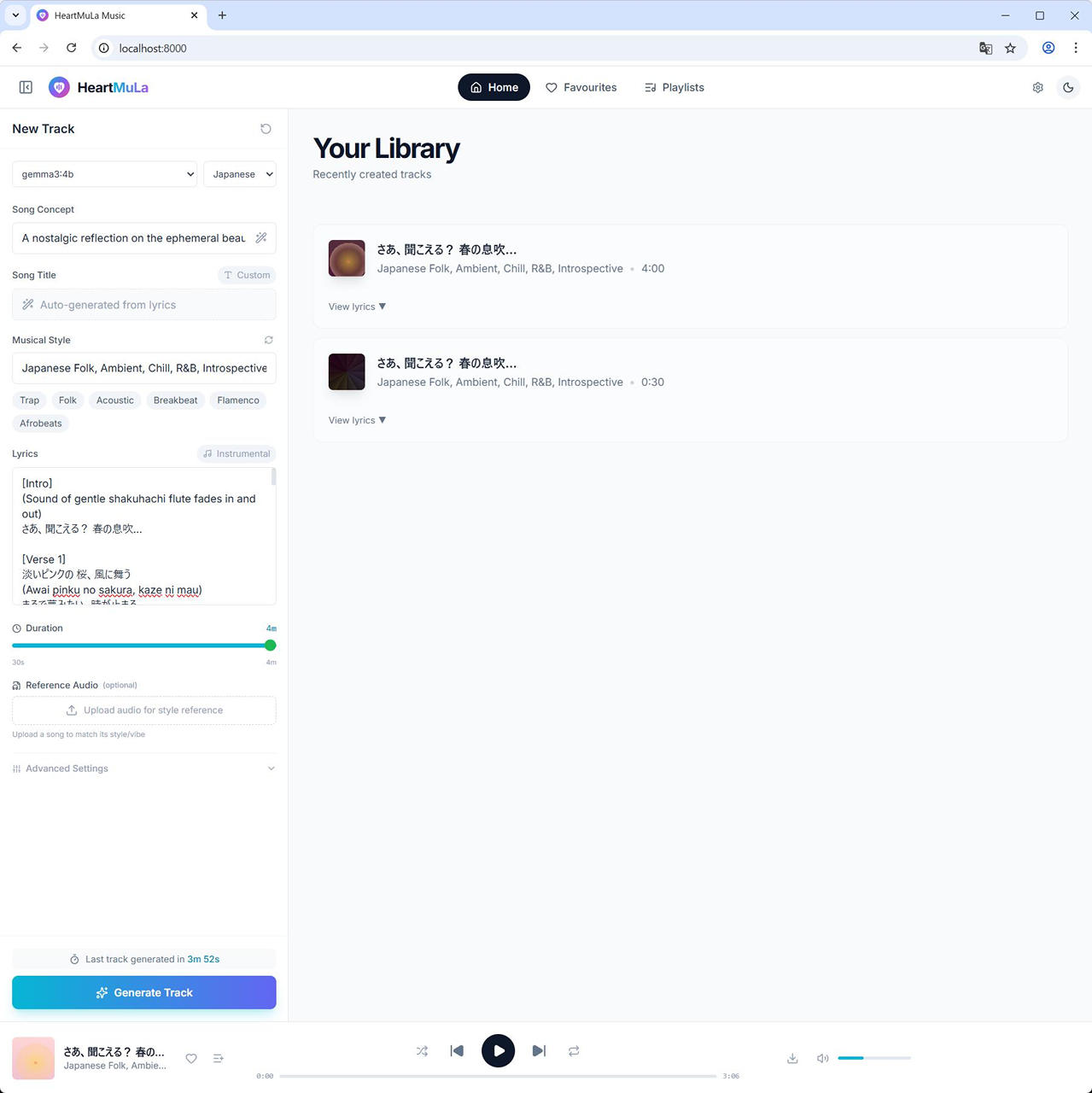
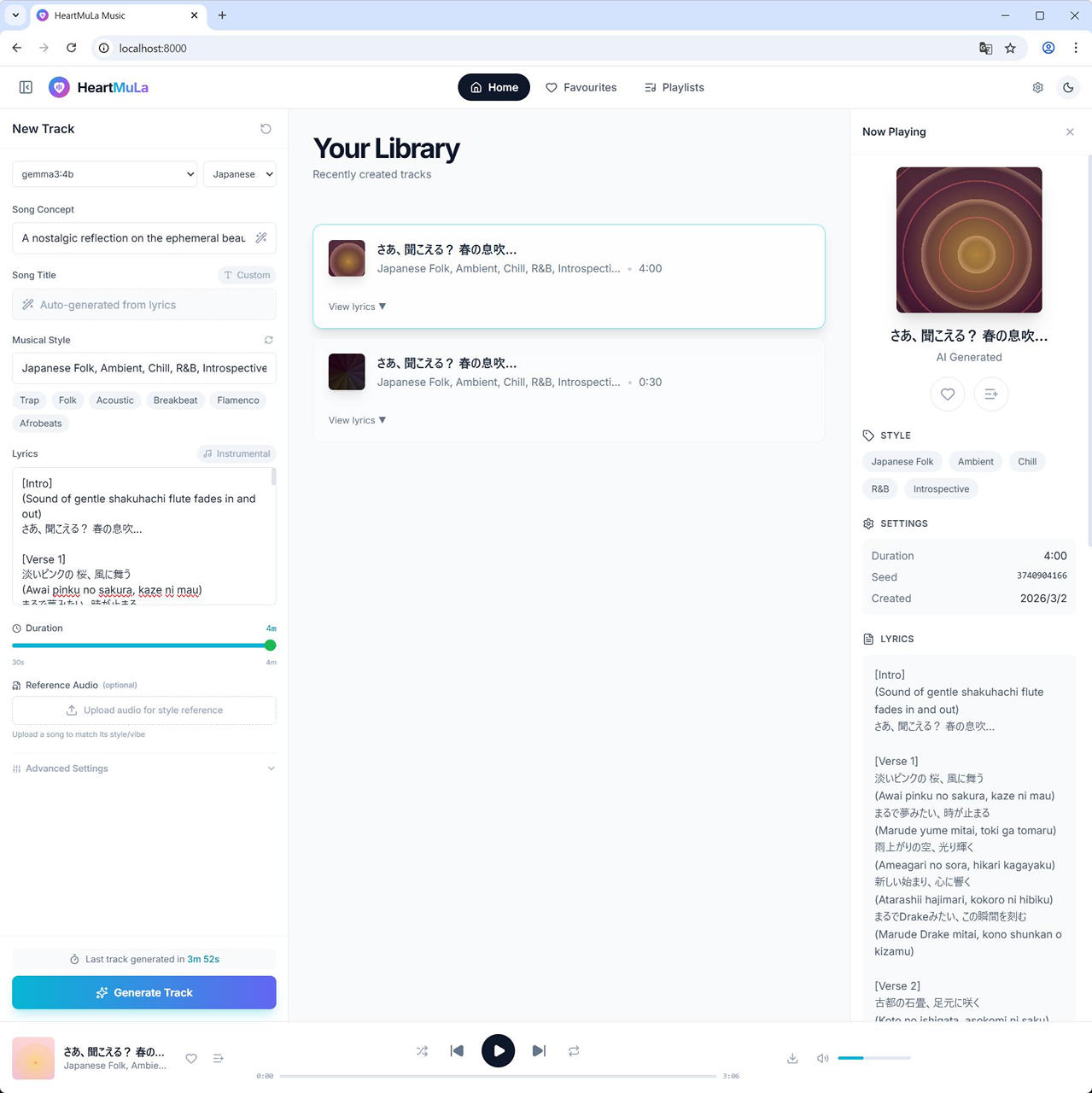
30秒の音楽の生成に約67秒、240秒の生成に 232秒 でした。
30秒バージョン
240秒バージョン
以上、参考となれば幸いです。