概要
ローカル環境で LLM を利用する場合、Ollama を利用するケースが多いと思いますので、改めて整理してみます。
Ollama とは
Ollama は、ローカル環境で大規模言語モデル(LLM)を手軽に動作させるためのオープンソースプロジェクトです。
公式サイト
https://ollama.com/
https://github.com/ollama/ollama
Ollama Windows 版
本稿更新時点では、Ollama は Windows ネイティブアプリケーションとしても提供されています。
(ネイティブアプリケーション版を利用する場合は、WSL やその上で動作する docker は必須ではないです。)
以下は、公式ドキュメントの情報をもとに補足しています。
https://github.com/ollama/ollama/blob/main/docs/windows.md
システム要件 (Windows版)
- OS:Windows 10 22H2 以降(Home または Pro)
- NVIDIA GPU:ドライバーバージョン 452.39 以降
- AMD Radeon GPU:最新のドライバー(AMD サポートから入手可能)
Ollama は、進行状況の表示に Unicode 文字を使用しています。一部の古いターミナルフォントでは、これらの文字が正しく表示されない場合があります。その際は、ターミナルのフォント設定を変更してください。
ファイルシステム要件 (Windows 版)
Ollama のインストールには管理者権限は不要です。デフォルトでは %LOCALAPPDATA%\Program\Ollama (例: C:\Users\ユーザー名\AppData\Local\Programs\Ollama) 配下インストールされます。バイナリのインストールには 約 5 GB の空き容量が必要です。
また、大規模言語モデル(LLM) を保存するための追加のストレージ容量が必要になります。これらのモデルは数十 GB から数百 GB に及ぶ場合があります。ホームディレクトリに十分な空き容量がない場合、バイナリのインストール先やモデルの保存場所を変更できます。
Ollama インストール方法
1. Ollama の公式サイトからインストーラ (OllamaSetup.exe) をダウンロードします。

2. ダウンロードしたインストーラを実行します。
インストール場所の変更
Ollama をホームディレクトリ以外の場所にインストールする場合、以下のコマンドを実行します。
OllamaSetup.exe /DIR="d:\some\location"
モデルの保存場所の変更
デフォルトでは、Ollama はホームディレクトリ (C:\Users\ユーザ名\.ollama\models) にモデルを保存しますが、別の場所に変更することも可能です。
- Windows の設定(Windows 11)またはコントロールパネル(Windows 10)を開く
- 「環境変数」を検索し、「アカウントの環境変数を編集」をクリック
- 「OLLAMA_MODELS」という新しい変数を作成し、モデルを保存したいディレクトリを指定
- OK または適用をクリックし、設定を保存
- Ollama を再起動(タスクトレイの Ollama を終了し、スタートメニューから再起動するか、新しいターミナルで再実行)
Ollama の基本的な使い方
Ollama は CLI ベースでの操作となります。
OllamaSetup.exe でインストールした場合は、ユーザーの %PATH% に ollama.exe が追加されるので、パスを記載しなくても実行できます。
Windows 11 で実行する場合は、ターミナル上で実行するのがよいでしょう。 ([スタート] → “ターミナル” で検索)
モデルの取得
Ollama では、pull コマンドを使ってモデルをダウンロードできます。
たとえば、Llama 2 を取得するには以下のコマンドを実行します。
ollama.exe pull llama2
ダウンロード可能なモデルは以下のサイトから確認できます。
https://ollama.com/library
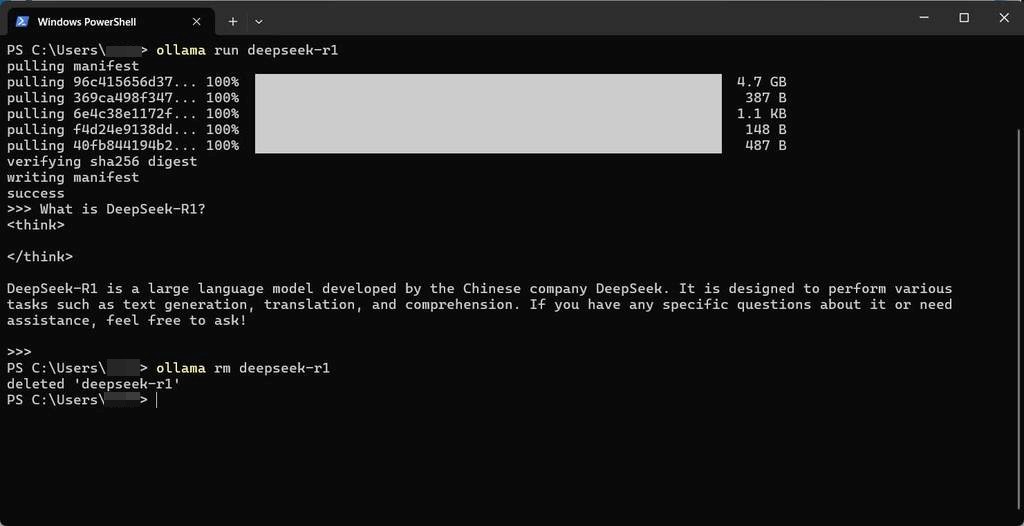
例えば、昨今話題となっている DeepSeek-R1 もあります。(ollama 経由で pull できるモデルは日本語への対応は不完全です。)
念のため以下のページの例を引用しておきます。
https://github.com/ollama/ollama
| Model | Parameters | Size | Download |
|---|---|---|---|
| DeepSeek-R1 | 7B | 4.7GB | ollama run deepseek-r1 |
| DeepSeek-R1 | 671B | 404GB | ollama run deepseek-r1:671b |
| Llama 3.3 | 70B | 43GB | ollama run llama3.3 |
| Llama 3.2 | 3B | 2.0GB | ollama run llama3.2 |
| Llama 3.2 | 1B | 1.3GB | ollama run llama3.2:1b |
| Llama 3.2 Vision | 11B | 7.9GB | ollama run llama3.2-vision |
| Llama 3.2 Vision | 90B | 55GB | ollama run llama3.2-vision:90b |
| Llama 3.1 | 8B | 4.7GB | ollama run llama3.1 |
| Llama 3.1 | 405B | 231GB | ollama run llama3.1:405b |
| Phi 4 | 14B | 9.1GB | ollama run phi4 |
| Phi 3 Mini | 3.8B | 2.3GB | ollama run phi3 |
| Gemma 2 | 2B | 1.6GB | ollama run gemma2:2b |
| Gemma 2 | 9B | 5.5GB | ollama run gemma2 |
| Gemma 2 | 27B | 16GB | ollama run gemma2:27b |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Moondream 2 | 1.4B | 829MB | ollama run moondream |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Solar | 10.7B | 6.1GB | ollama run solar |
モデルの実行
以下のコマンドでモデルを対話形式で利用できます。
事前に pull していない場合は、ダウンロードも自動で行われます。
ollama.exe run llama2
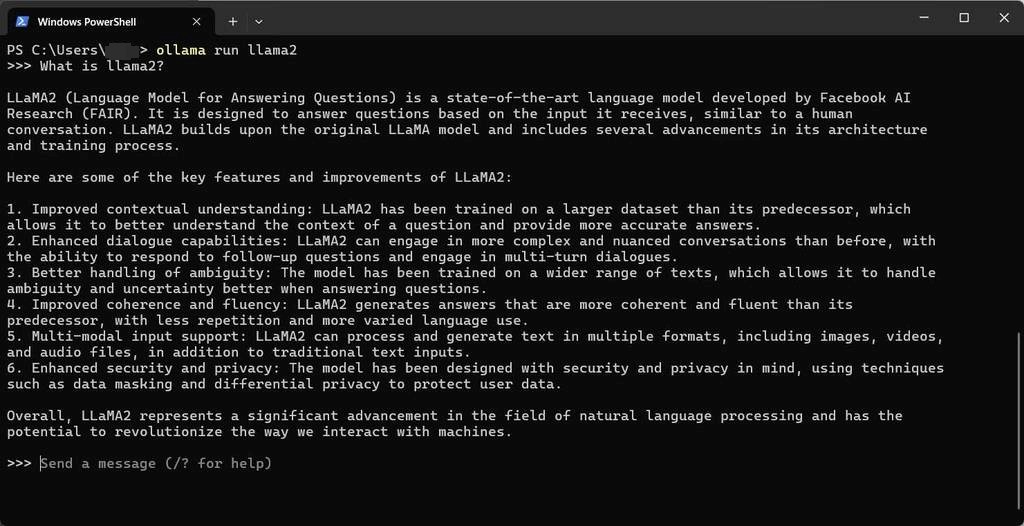
終了する場合は、Ctrl+d (コントロールキーをしながら d) です。
モデル自体が日本語に対応していれば、日本語でのやりとりも可能です。
出力は Markdown 形式なので、ターミナル上だと ** などがそのまま見えます。
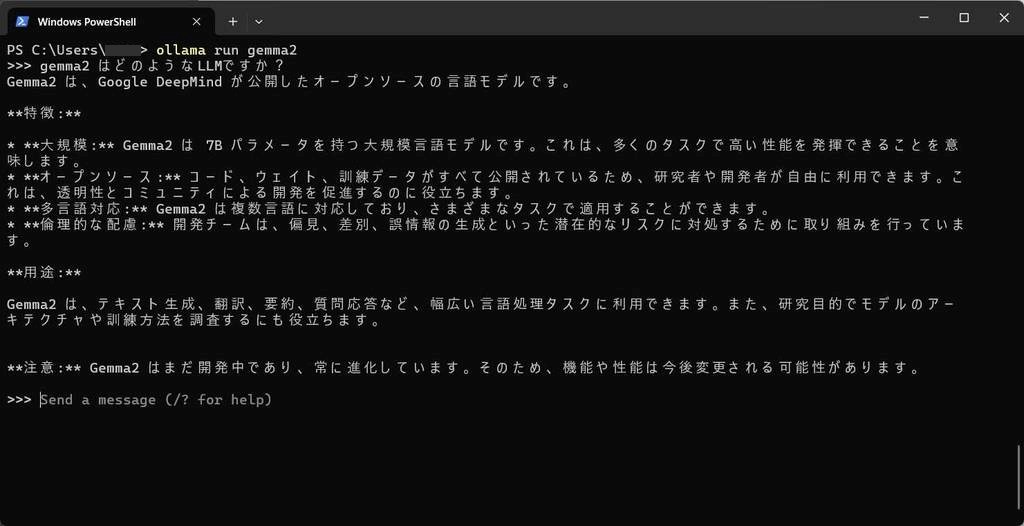
ダウンロード済みのモデルの確認
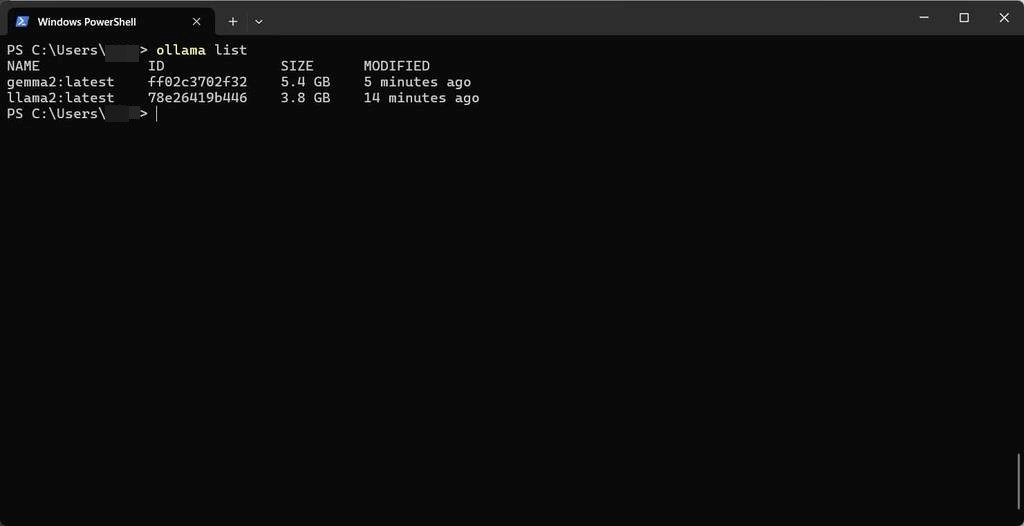
ダウンロード済みのモデルは、list で確認できます。
ollama.exe list
モデルの削除
空き容量の都合など不要になったモデルは rm で削除できます。
ollama.exe rm モデル名
GPU との連携
対応する GPU があり、そのドライバをインストールすれば、基本的には GPU と連携するようです。
ただし、試した限り、GPU (の VRAM) に対して、モデルのサイズが大きすぎると GPU との連携はあきらめるようで CPU が使われました。
私が試した環境は、NVIDIA GeForce RTX 3050 (VRAM : 6GB) ですが、以下のような挙動が見られました。
- Llama 3.2 1B (llama3.2:1b), Gemma2 2B (gemma2:2b), Phi3 Mini 3.8B (phi3:latest)では 主に GPU が利用される。
- Gemma2 9B (gemma2:latest)では、主に CPU が利用される。(GPU 側は VRAM 全部と 計算側で30%くらい利用)
- Llama 2 7B (llama2:latest) では、GPU と CPU が使われる。(両方とも 100% くらい)
モデルのサイズとしては以下のような形です。
すでに利用済みの VRAM の分やオーバヘッドなどを差し引いて VRAM に載りきらないと、CPU とメモリが利用されるのかなという印象です。
PS C:\Users\user> ollama list
NAME ID SIZE MODIFIED
llama3.2:1b baf6a787fdff 1.3 GB 10 minutes ago
gemma2:latest ff02c3702f32 5.4 GB 12 minutes ago
gemma2:2b 8ccf136fdd52 1.6 GB 16 minutes ago
phi3:latest 4f2222927938 2.2 GB 23 minutes ago
llama2:latest 78e26419b446 3.8 GB 2 hours ago
PS C:\Users\user>参考となれば幸いです。
▼ 関連